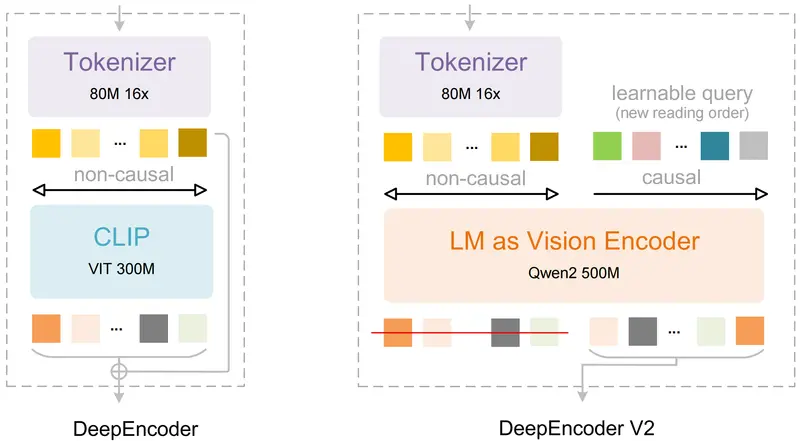
在复杂文档图像理解和结构化提取任务中,如何准确识别并组织交织的文本段落、公式、表格和图像,一直是业界的技术难点。
字节跳动最新推出的 Dolphin 模型,提出了一种全新的解决方案 —— 基于“异构锚点提示”机制的两阶段文档图像解析方法,在保证高精度的同时,实现了高效的并行处理能力。

为什么需要 Dolphin?
传统文档图像解析方法往往面临以下几个挑战:
- 多元素混排(文字、图、表、公式);
- 阅读顺序不规则,逻辑关系复杂;
- 模型推理效率低,难以满足实际应用需求;
而 Dolphin 的设计目标正是为了解决这些问题。它不仅能够自动识别文档中的各种元素类型,还能将其按照自然阅读顺序排列输出,为后续的信息抽取与下游任务提供高质量结构化输入。
Dolphin 的核心设计理念
Dolphin 采用先分析后解析的两阶段范式:
🧭 第一阶段:页面级布局分析
- 生成一个自然阅读顺序的元素序列;
- 完成对文档整体结构的理解;
- 包括文本块、图片、公式区域、表格等的定位与排序;
🔍 第二阶段:元素级并行解析
- 使用异构锚点提示(Heterogeneous Anchor Prompts);
- 针对不同类型的元素执行特定任务(如 OCR、公式识别、表格结构提取等);
- 支持并行解析,显著提升整体效率;
这一设计使 Dolphin 能够在保持高性能的同时,灵活应对多样化的文档解析任务。
模型架构详解
Dolphin 基于经典的视觉编码器-解码器结构,结合 Transformer 架构构建,具备良好的扩展性和可集成性。
📷 视觉编码器:Swin Transformer
- 负责从输入文档图像中提取高维视觉特征;
- 兼顾局部细节与全局结构信息;
✍️ 文本解码器:mBART
- 基于多语言预训练模型 mBART 进行解码;
- 实现从视觉特征到自然语言描述的转换;
💬 提示接口:基于自然语言控制任务
- 使用自然语言指令指定解析任务类型(如提取表格、识别公式等);
- 灵活支持多种下游解析需求;
此外,该模型已封装为 Hugging Face 的 VisionEncoderDecoderModel 格式,便于开发者快速接入 Transformers 生态系统。
性能优势与应用场景
⚡ 高效解析
得益于轻量级架构与并行机制,Dolphin 在处理复杂文档时表现出色,尤其适合大规模文档数据的自动化处理。
📊 多样任务支持
Dolphin 可广泛应用于以下场景:
- 学术论文结构化提取
- 财务报告表格识别
- 教材与讲义内容重构
- 法律文书自动归档
- 多媒体文档智能检索
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











