
延世大学和卡内基梅隆大学的研究人员推出一个名为 WEB-SHEPHERD 的过程奖励模型(PRM),专门用于评估网络导航任务中的智能代理行为。网络导航是一个复杂的领域,需要智能代理能够进行长期的序列决策,这超出了典型的多模态大语言模型(MLLMs)任务的范畴。然而,以往的研究中缺乏专门用于网络导航的奖励模型,尤其是在训练和测试阶段都能使用的模型。WEB-SHEPHERD 通过提供逐步的奖励信号,填补了这一空白,显著提高了网络代理的性能和效率。
- GitHub:https://github.com/kyle8581/Web-Shepherd
- 模型:https://huggingface.co/collections/LangAGI-Lab/web-shepherd-advancing-prms-for-reinforcing-web-agents-682b4f4ad607fc27c4dc49e8
- Demo:https://demo.web-shepherd.io
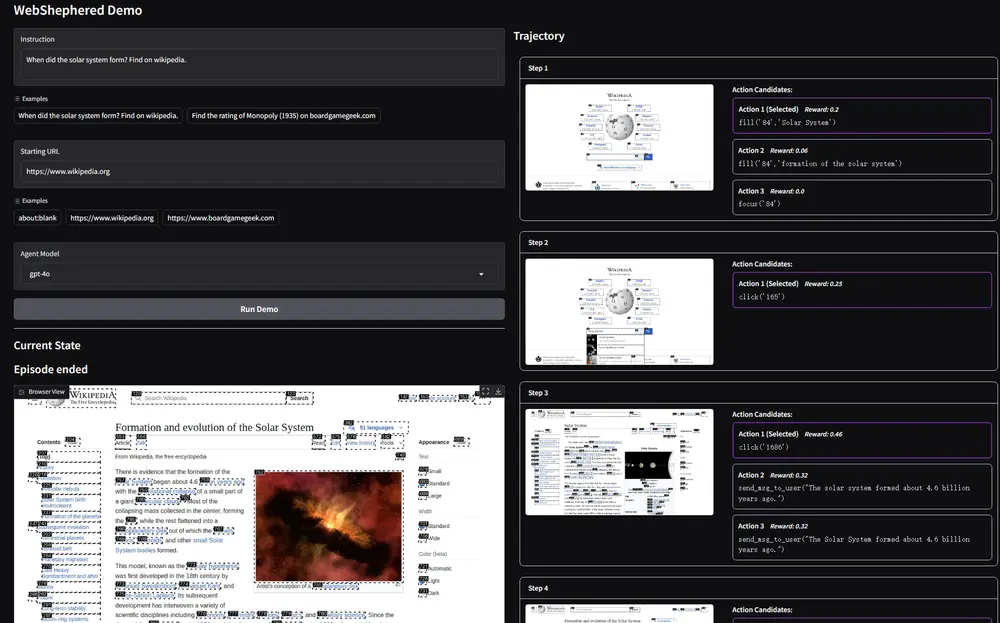
主要功能
- 奖励信号生成:WEB-SHEPHERD 能够为网络导航任务生成精确的奖励信号,帮助智能代理在复杂的网络环境中做出更优的决策。
- 过程评估:该模型不仅评估最终结果,还能在每一步提供奖励信号,确保代理在过程中保持正确的方向。
- 成本效益:与现有的基于大型语言模型的奖励模型相比,WEB-SHEPHERD 在保持高性能的同时显著降低了计算成本。
主要特点
- 首个专门的网络导航奖励模型:WEB-SHEPHERD 是首个专门为网络导航设计的奖励模型,能够评估智能代理的每一步操作。
- 大规模数据集支持:为了训练 WEB-SHEPHERD,作者构建了 WEBPRM COLLECTION,这是一个包含 40K 步骤级偏好对和注释检查表的大规模数据集。
- 元评估基准:作者还发布了 WEBREWARDBENCH,这是第一个用于评估过程奖励模型的元评估基准,允许研究者在不运行资源密集型网络代理的情况下测试新的 PRM 设计。
工作原理
- 数据收集:
- 作者从人类专家那里收集用户指令和专家轨迹,确保数据覆盖多种任务和难度级别。
- 通过 GPT-4o 生成检查表(checklist),并为每个指令标注检查表,以便模型能够根据检查表评估每一步的进展。
- 为了生成被拒绝的动作,作者从多种策略中采样候选动作,并通过规则过滤器筛选出真正次优的动作。
- 模型训练:
- WEB-SHEPHERD 使用结构化的检查表来评估智能代理的每一步操作,通过参考检查表中的标准,精确评估每一步的进展。
- 该模型通过生成反馈和判断来优化语言建模损失,将整个序列视为连贯的响应进行训练。
- 奖励信号生成:
- 在推理阶段,WEB-SHEPHERD 生成反馈 ( F ) 并为每个检查表项计算奖励,最终奖励是所有检查表项奖励的平均值。
- 通过使用生成的反馈和检查表评估响应,模型能够为每一步提供精确的奖励信号。
测试结果
- WEBREWARDBENCH 评估:在 WEBREWARDBENCH 上,WEB-SHEPHERD 的性能显著优于现有的基于 GPT-4o 的奖励模型,准确率提高了约 30 个百分点。
- 成本效益:在 WebArena-lite 测试中,使用 GPT-4o-mini 作为策略模型时,WEB-SHEPHERD 作为验证器的性能比 GPT-4o-mini 高出 10.9 个百分点,且成本降低了 10 倍。
- 奖励引导的轨迹搜索:在奖励引导的轨迹搜索中,WEB-SHEPHERD 能够显著提高智能代理的性能,尤其是在复杂任务中。

应用场景
- 自动化网络任务:WEB-SHEPHERD 可以用于自动化各种网络任务,如信息检索、在线购物、表单填写等,提高任务的效率和成功率。
- 智能代理开发:该模型可以作为开发更可靠网络代理的基础,通过提供精确的奖励信号,帮助代理在复杂的网络环境中做出更优的决策。
- 多模态任务:WEB-SHEPHERD 也适用于需要视觉和文本理解的多模态任务,如在 VisualWebArena 等环境中导航。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











