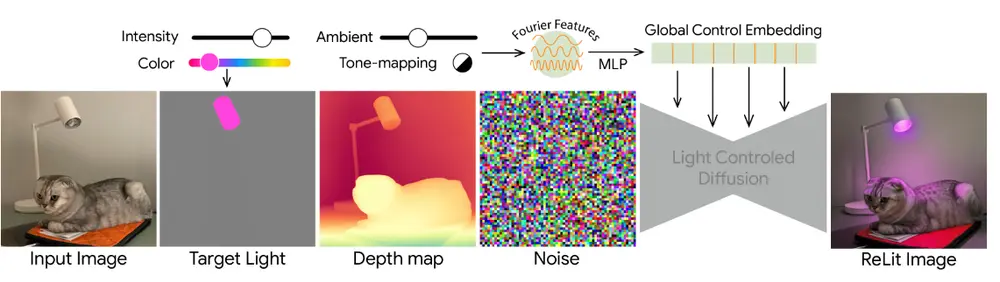
在电商广告、虚拟试穿、交互式媒体等场景中,如何高效生成高质量的人类-产品演示视频,一直是视觉生成领域的重要挑战。
近日,字节跳动 AI 实验室提出了一种全新的视频生成框架——DreamActor-H1,该模型基于扩散变换器(Diffusion Transformer, DiT),能够从单张人类图像 + 单张产品图像出发,生成具有高保真度和自然动作表现的演示视频。
这项研究不仅在身份保留、空间关系建模等方面超越了当前最先进的方法,也为个性化电商展示、AI数字人应用提供了新的技术路径。
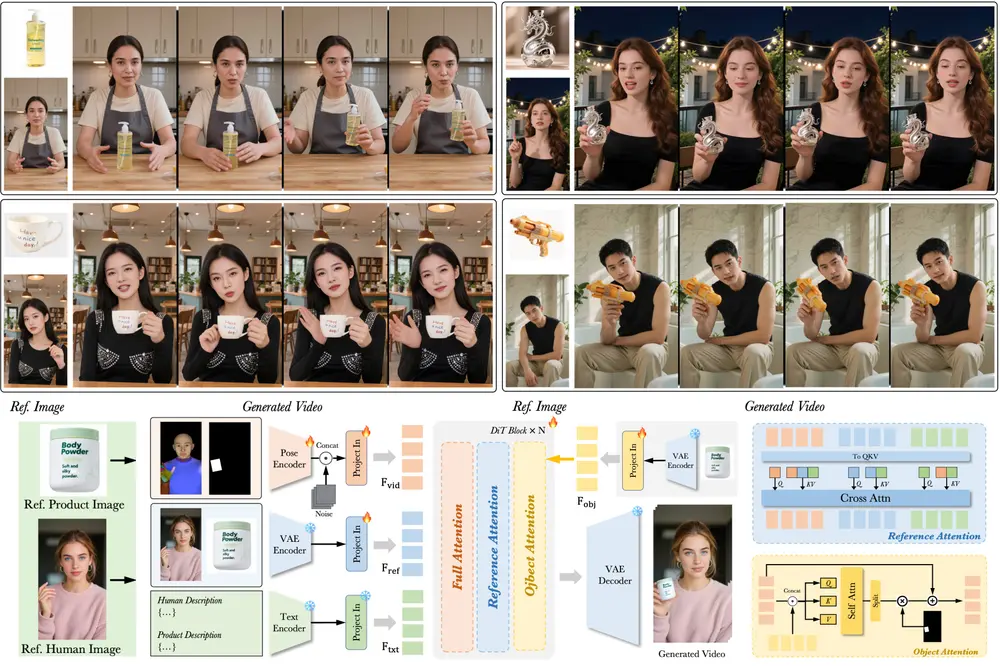
为什么需要 DreamActor-H1?
在传统视频生成任务中,生成“人类穿戴或操作特定产品”的视频通常面临三大难题:
- 身份保持难:无法同时保留输入人类和产品的外观特征(如人脸、品牌标识、纹理等);
- 动作不够真实:生成的动作不符合物理规律,手势与产品交互不自然;
- 缺乏语义控制:难以根据类别信息引导合理的动作变化(如背包应挂在肩上而非拿在手中)。
为了解决这些问题,DreamActor-H1 引入了一系列关键技术创新,使其在保持细粒度身份信息的同时,实现高质量的动态演示生成。
DreamActor-H1 的核心架构与方法亮点
DreamActor-H1 基于目前主流的 扩散变换器(DiT) 架构,并结合了一个约 70 亿参数的基础视频生成模型 Seaweed-7B。其整体流程如下:
1. 输入准备阶段
- 参考图像编码:使用 VAE 对输入的人类和产品图像进行编码,作为外观指导。
- 描述文本生成:借助视觉-语言模型(VLM)提取人类和产品描述,增强语义理解。
- 运动信号提取:对训练视频中的每一帧提取姿势估计图(pose map)和产品边界框(bounding box),用于后续动作控制。
2. 训练阶段
- 多模态融合:将姿态图、产品边界框、图像潜在表示、文本描述等多源信息统一输入 DiT 模型。
- 掩码交叉注意力机制:通过对象注意力模块,将产品潜在表示作为额外输入,提升产品细节保留能力。
- 结构化文本编码:引入类别级语义信息,增强帧间小旋转变化的 3D 一致性。
3. 推理阶段
- 自动选择合适的姿势模板,结合用户输入的人类与产品图像,生成连续、自然的演示视频。
技术突破与优势总结
DreamActor-H1 在多个方面实现了显著的技术进步:
✅ 双身份保留能力强
可同时保留输入人类的面部特征、服饰风格,以及产品的品牌标志、纹理图案。
✅ 动作自然且物理合理
通过姿态图和边界框引导,确保手势与产品放置方式符合现实物理逻辑。
✅ 支持多样化产品类型
适用于服装、包袋、电子产品等多种商品类别,具备良好的泛化能力。
✅ 增强帧间一致性
结构化文本编码帮助模型理解产品类别,从而更好地处理微小角度变化下的连续性问题。
实验结果与性能对比
研究人员在大规模混合数据集上进行了训练,并与当前主流方法进行了对比测试。结果显示:
- 在身份保留、时间一致性、生成质量等多个指标上均优于现有最先进模型。
- 视觉评估表明,DreamActor-H1 能够生成更加自然、连贯的演示动作,特别是在复杂交互场景下表现尤为突出。
- 消融实验证明,加入文本描述和对象注意力后,模型在细粒度控制和稳定性方面有明显提升。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











