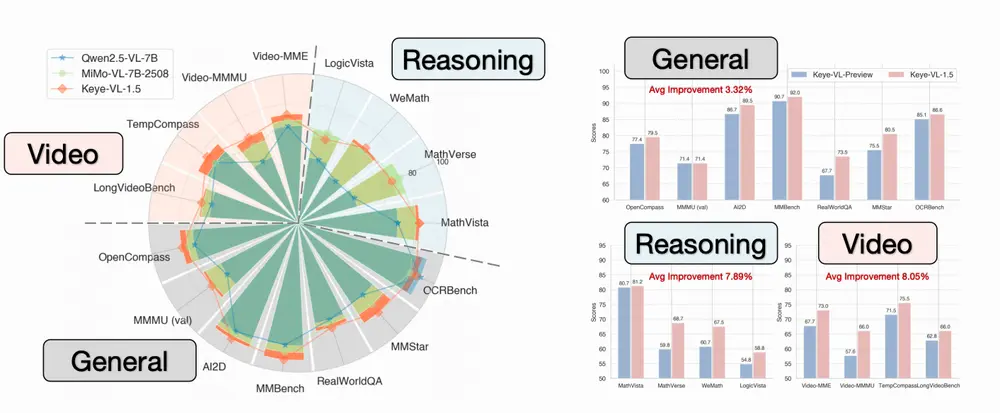
复旦大学计算机学院、腾讯优图实验室、上海交通大学等的研究人体推出新型目标检测模型Mamba-YOLO-World,它专门设计用于开放词汇检测(Open-Vocabulary Detection,简称OVD),这是一种能够识别超出预定义类别集合的对象的检测任务。简单来说,它就像是一个能够理解并识别各种不同物体的智能系统,即使这些物体在训练时没有被明确标记。
Mamba-YOLO-World是一种基于YOLO的OVD模型,采用了研究团队提出的MambaFusion路径聚合网络(MambaFusion-PAN)作为其颈部架构。具体来说,研究团队引入了一种基于状态空间模型的特征融合机制,包括具有线性复杂性和全局引导感受野的并行引导选择性扫描算法和串行引导选择性扫描算法。它利用多模态输入序列和曼巴隐藏状态来指导选择性扫描过程。实验表明,Mamba-YOLO-World在COCO和LVIS基准测试中的零样本和微调设置下的性能均超过了原始的YOLO-World,同时保持了相似的参数和FLOPs。此外,它以更少的参数和FLOPs超过了现有的最先进的OVD方法。

主要功能:
- 开放词汇检测: 能够检测和识别各种不同的物体,即使是在训练数据中未出现过的物体。
- 高效处理: 特别适合于需要快速和高效处理的场景。
主要特点:
- MambaFusion-PAN架构: 这是一种新颖的特征融合网络,它使用状态空间模型(State Space Model)来优化特征融合过程,提高了效率和准确性。
- 线性复杂度: 通过创新的并行引导选择扫描算法和串行引导选择扫描算法,实现了线性复杂度,这意味着处理时间不会随着数据量的增加而呈二次方增长。
- 全局引导的接受域: 能够全局地引导特征融合,提高了检测的准确性。
工作原理:
- 特征融合: 通过MambaFusion-PAN网络,将图像特征和文本特征进行有效融合,以提高检测的准确性。
- 选择扫描算法: 利用并行引导选择扫描算法和串行引导选择扫描算法,动态调整内部参数,以适应输入的图像序列和文本隐藏状态。
- 状态空间模型: 利用状态空间模型来处理序列数据,使得模型能够更好地理解和处理输入信号。

具体应用场景:
- 自动驾驶: 在自动驾驶车辆中,Mamba-YOLO-World可以帮助车辆识别各种不同的物体,提高行车安全。
- 安防监控: 在安防系统中,该模型可以用于实时检测和识别监控视频中的各种物体,提高监控效率。
- 智能设备: 在智能手机或其他智能设备中,Mamba-YOLO-World可以用于图像处理和识别,提供更丰富的用户体验。
总的来说,Mamba-YOLO-World是一个强大的目标检测模型,它通过创新的特征融合机制和高效的算法,提高了开放词汇检测的性能,使其在多种应用场景中都具有潜在的价值。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











