
加州大学洛杉矶分校的研究人员推出OpenVLThinker,通过迭代自我改进的方法,将复杂的推理能力(如自我验证和自我修正)整合到大型视觉语言模型(LVLMs)中,并评估其在多模态推理任务中的表现。
例如,有一个多模态推理任务,例如给定一张包含几何图形的图像和一个问题:“图中的三角形的最长边是多少?”传统的视觉语言模型可能只能识别图像中的对象,但缺乏复杂的推理能力。而OpenVLThinker通过迭代自我改进的方法,能够生成详细的推理过程,例如:
- 识别图像中的三角形及其边长。
- 通过数学推理计算最长边。
- 生成详细的推理路径并验证结果的正确性。
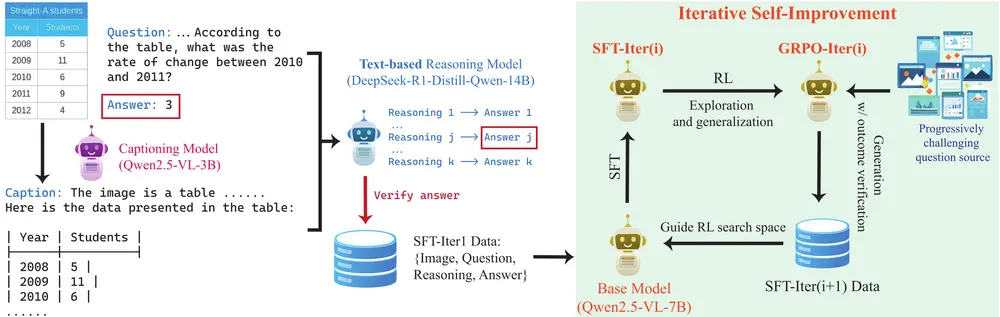
主要功能
- 复杂推理能力:OpenVLThinker能够生成复杂的推理路径,包括自我验证和自我修正,从而提高模型在多模态推理任务中的表现。
- 迭代自我改进:通过交替使用监督微调(SFT)和强化学习(RL),模型能够逐步提升其推理能力。
- 多模态推理:模型能够处理包含图像和文本的多模态任务,生成准确的推理结果。
主要特点
- 监督微调(SFT):通过SFT,模型能够学习到初始的推理结构,为后续的强化学习提供基础。
- 强化学习(RL):使用Group Relative Policy Optimization(GRPO)进行RL训练,进一步提升模型的推理能力和泛化能力。
- 迭代训练:通过多次迭代,模型能够逐步改进其推理能力,每次迭代都生成更高质量的推理数据用于下一轮训练。
- 数据源进化:在迭代过程中,逐步引入更具挑战性的数据源,使模型能够处理更复杂的任务。
工作原理
- 数据准备:从多个视觉数据集中收集图像-问题-答案三元组,并使用高质量的图像描述生成推理步骤。
- 监督微调(SFT):使用生成的推理数据对基础模型进行SFT,使其能够生成结构化的推理路径。
- 强化学习(RL):通过GRPO对SFT后的模型进行RL训练,进一步提升推理能力。
- 迭代改进:每次迭代后,使用改进后的模型生成新的推理数据,用于下一轮SFT和RL训练。逐步引入更具挑战性的数据源,提升模型的泛化能力。
应用场景
- 教育领域:在数学和科学教育中,OpenVLThinker可以帮助学生理解复杂的几何和物理问题,生成详细的解题步骤。
- 智能助手:在智能助手中,OpenVLThinker能够处理用户提出的多模态问题,提供准确的推理和解答。
- 科研领域:在科研中,OpenVLThinker可以用于分析复杂的图表和图像数据,生成详细的推理报告。
- 工业应用:在工业自动化中,OpenVLThinker可以用于图像识别和质量控制任务,通过复杂的推理能力提高检测精度。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











