
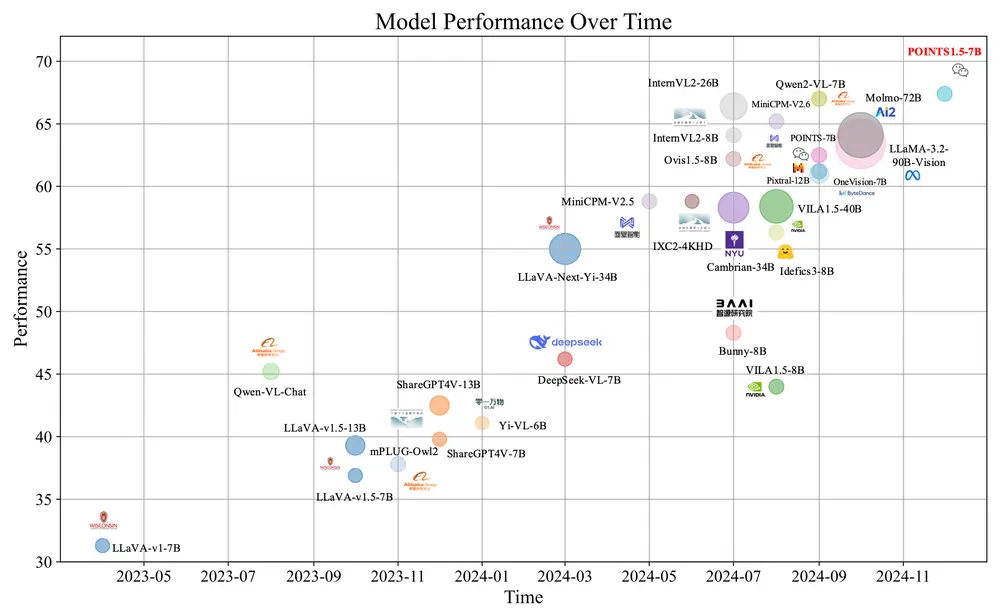
微信 AI 模式识别中心推出视觉语言模型POINTS1.5系列,旨在提升对真实世界应用的处理能力。POINTS1.5是POINTS1.0的增强版本,它通过引入几项关键创新,改进了模型在处理高分辨率图像、双语支持(特别是中文)以及视觉指令调整数据集的过滤方法方面的表现。例如,用户需要识别一张包含多种水果的图片,并希望模型能够描述这些水果的特点。POINTS1.5能够准确地识别出图片中的香蕉、菠萝、梨和苹果,并为每种水果提供详细的描述,包括它们的味道、营养价值和常见的食用方式。
- GitHub:https://github.com/WePOINTS/WePOINTS
- 模型:https://huggingface.co/WePOINTS/POINTS-1-5-Qwen-2-5-7B-Chat
主要功能:
- 高分辨率图像处理:POINTS1.5采用了NaViT风格的视觉编码器,能够处理任意分辨率的图像,无需将图像分割成小块(tiles)。
- 双语支持:模型增强了对中文的处理能力,通过结合手动和自动方法从互联网收集大量中文图像,并进行注释。
- 视觉指令调整数据集的过滤:提出了一套严格的过滤方法,以获得最终的视觉指令调整集,从而提高模型对图像内容的理解和指令执行能力。
主要特点:
- 模块化:POINTS1.5的设计是模块化的,可以与任何现有的图像生成和编辑模型结合使用。
- 无需训练:该方法不需要额外的训练,可以直接应用于现有的模型。
- 性能提升:在多个真实世界应用中表现出色,特别是在OpenCompass排行榜上,POINTS1.5-7B在不到10亿参数的模型中名列前茅。
工作原理:
POINTS1.5遵循LLaVA风格的架构,包括视觉编码器、MLP投影器和大型语言模型(LLM)。它首先使用视觉编码器处理输入图像,然后通过MLP投影器将视觉特征映射到文本空间,最后利用LLM生成与图像和文本提示相符的输出。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











