JoyCaption,一个从零开始构建的免费、开放且未经审查的视觉语言模型(VLM),旨在助力社区训练SD或Flux模型。它不仅免费开放,还提供训练脚本和丰富的构建细节,就像bigASP一样。
- Demo:https://huggingface.co/spaces/fancyfeast/joy-caption-alpha-one
- Demo:https://huggingface.co/spaces/fancyfeast/joy-caption-alpha-two
- GitHub:https://github.com/fpgaminer/joycaption
- 模型下载:https://huggingface.co/fancyfeast/llama-joycaption-alpha-two-hf-llava
ComfyUI节点:
目前有多款节点支持JoyCaption,大家可以根据自己的需求进行选择。
- Comfyui_JC2:https://github.com/TTPlanetPig/Comfyui_JC2
- JoyCaptionAlpha Two for ComfyUI:https://github.com/EvilBT/ComfyUI_SLK_joy_caption_two
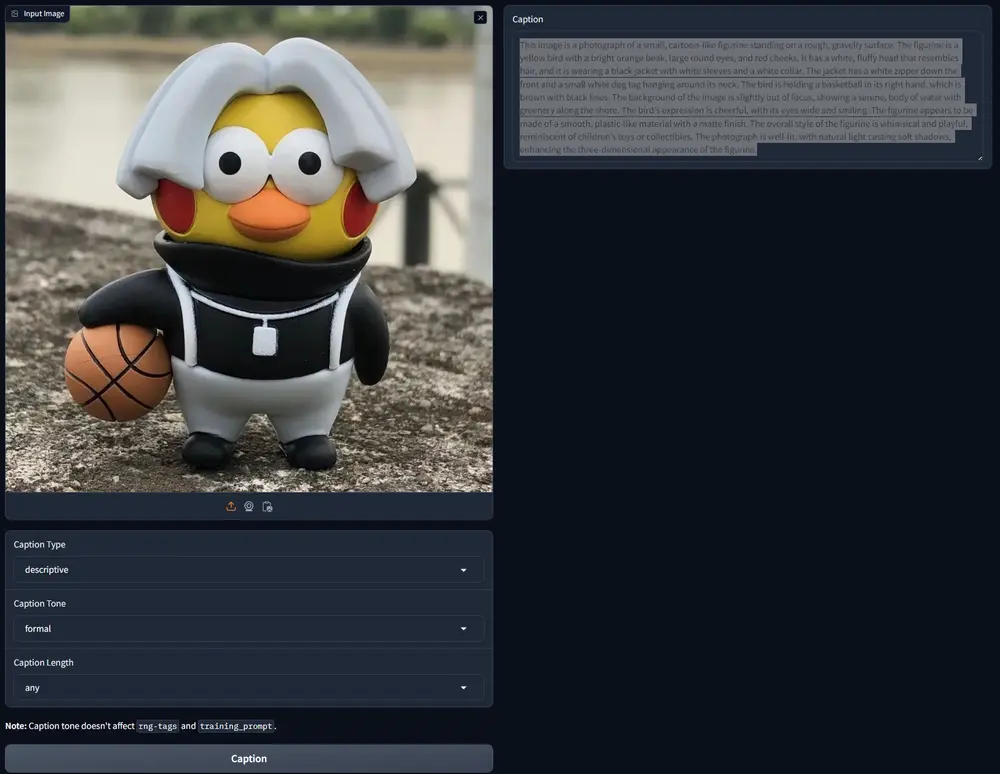
特点概览
- 自由和开放:免费发布,无限制权重,附带训练脚本。
- 内容无审查:平等覆盖适宜和不适宜的内容,不回避任何概念。
- 多样性:欢迎各种风格和内容,无论是数字艺术、照片般真实、动漫还是Furry,JoyCaption都适合每个人。
- 最小过滤:训练了大量图像,以理解我们世界的几乎所有方面,除了非法内容。
最新动态
自Pre-Alpha版本发布以来,作者根据社区反馈进行了多项改进,包括扩展数据集,增加了对动漫/电子游戏角色、经典艺术、电影名称等的识别能力。
新功能
- 控制字幕长度:现在可以控制JoyCaption生成的字幕长度,从20到260个词,或选择“任何”长度。
- 风格选择:可以选择与Pre-Alpha版本相同的正式风格,或尝试新的“非正式”风格。
- 字幕类型:新增“描述性”和“训练提示”两种字幕类型,后者尝试模仿用户编写稳定扩散提示的方式。
开发细节
过去一个月,作者手动编写了2000个训练提示字幕,尽管遇到挑战,但这些努力带来了新的字幕长度和语调控制功能。
警告
- 训练提示模式:仍在完善中,使用时需谨慎。
- 非正式风格:虽然有助于扩展模型的词汇,但风格上仍有改进空间。
- 数据集扩展:虽然在电影、艺术和角色识别方面有所改善,但OCR和艺术家识别方面仍需加强。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











