GOT-OCR 模型是一个参数量达 580M 的OCR系统,专为识别和处理各种字符而设计。该模型配备了高压缩编码器和长上下文解码器,能够精准处理各种场景和文档风格的图像。它支持多页和动态分辨率的 OCR,提升了其应用的广泛性。(官方详解)
- GitHub:https://github.com/Ucas-HaoranWei/GOT-OCR2.0
- 模型:https://huggingface.co/stepfun-ai/GOT-OCR2_0
- Demo:https://modelscope.cn/studios/stepfun-ai/GOT_official_online_demo
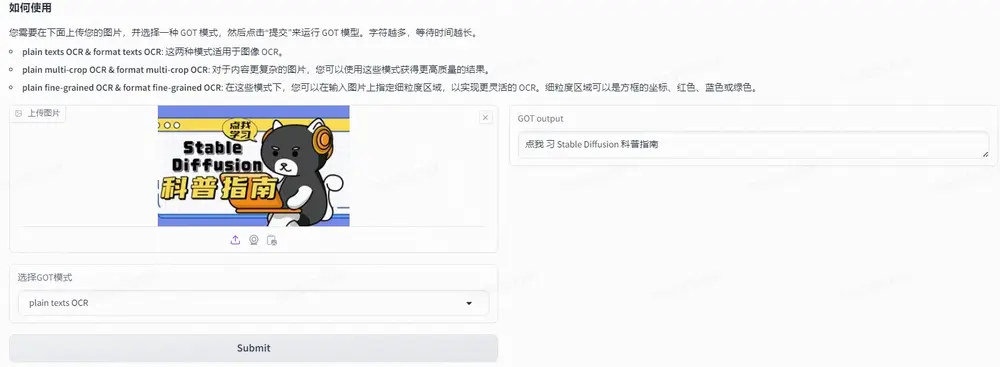
主要特点
- 普通文本 OCR:从图像中提取文本信息。
- 格式化文本 OCR:保留文本的原始排版格式,包括表格和公式。
- 细粒度 OCR:提供基于区域和颜色的 OCR,以实现对特定区域的精确识别。
- 多裁剪 OCR:能够识别图像内多个裁剪区域的文本。
支持的内容类型
- 普通文本
- 数学公式或化学分子结构式
- 表格和图表
- 乐谱
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











