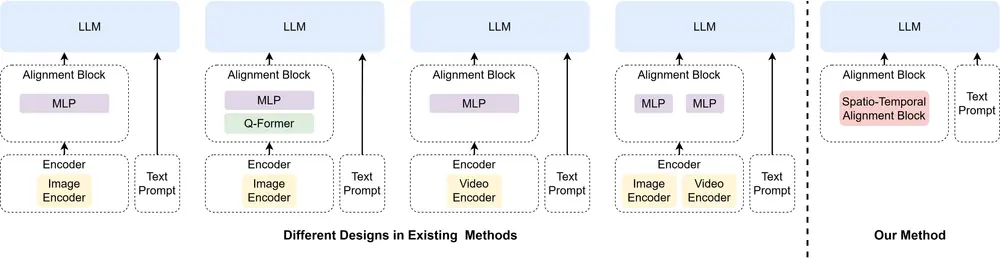
视频与文本之间的细粒度对齐是一个具有挑战性的问题,因为视频中存在复杂的空间和时间动态。现有的基于视频的大型多模态模型(LMMs)虽然可以处理基本对话,但在视频中进行精确的像素级定位方面存在困难。
大型多模态模型VideoGLaMM
为了解决这一问题,穆罕默德·本·扎耶德人工智能大学、天津大学、林雪平大学、澳大利亚国立大学和卡内基梅隆大学的研究人员提出了VideoGLaMM,这是一个专为用户提供的文本输入进行视频中细粒度像素级定位而设计的大型多模态模型。这个模型能够理解视频中的复杂空间和时间动态,并根据用户提供的文本输入在像素级别上进行精确的视觉定位。
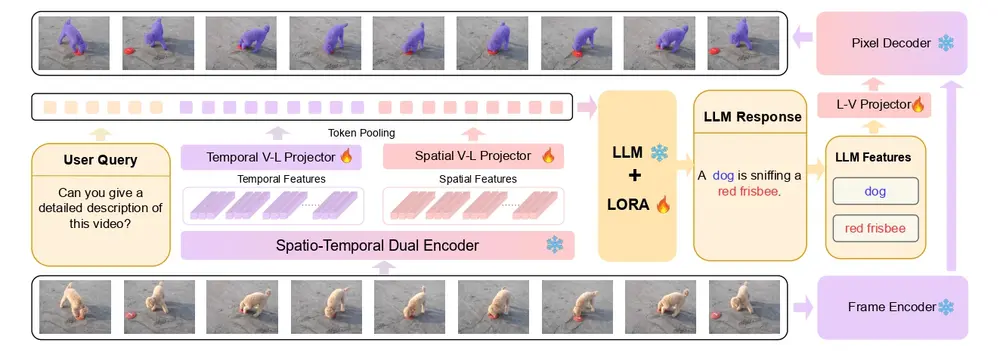
例如,给定一个视频和用户查询“视频中的狗在做什么?”VideoGLaMM能够生成文本回应,并在视频中精确地定位并标记出狗的行为,例如“一只狗在嗅一个红色的飞盘”,同时生成与文本描述相对应的像素级掩码(mask),显示出视频中狗和飞盘的确切位置。

主要功能
像素级视觉定位:模型能够将文本响应与视频中的具体对象和区域精确对应起来。 细粒度对齐:模型处理空间和时间特征,确保生成的输出在空间(每一帧中发生了什么)和时间(事物随时间如何变化)上都与文本指令同步。 多模态交互:模型结合了大型语言模型(LLM)、双视觉编码器和时空解码器,通过可调节的视觉-语言(V→L和L→V)适配器实现紧密对齐。
主要特点
双编码器结构:模型使用独立的图像和视频编码器分别提取空间和时间特征,以获得局部和全局属性。 端到端对齐机制:通过在训练中微调LLM的LoRA参数和V→L、L→V适配器,模型能够将空间和时间数据无缝结合,提高视觉定位能力。 细粒度基准数据集:为了实现细粒度对齐,研究者们通过半自动注释流程创建了一个包含38k视频-QA三元组和大约671k精细掩码的基准数据集。
工作原理
VideoGLaMM的架构包括以下几个关键组件:
双时空编码器:一个编码器专注于从图像中提取空间细节,另一个编码器捕获视频序列中的时间信息。 V→L适配器:将视觉特征映射到LLM的潜在空间中,实现视觉和语言模态的对齐。 大型语言模型(LLM):将文本特征与空间和时间视觉特征结合,输出包含空间和时间线索的响应。 像素解码器:接收LLM的输出,并结合输入视频帧的特征,生成与LLM输出相对应的细粒度对象掩码。
数据集
为了训练和评估VideoGLaMM,研究人员策划了一个多模态数据集,该数据集使用半自动注释管道生成:
视频-QA三元组:38,000个视频-QA三元组。 对象标注:83,000个对象标注。 掩码标注:671,000个掩码标注。
这些数据集涵盖了详细的视觉基础对话,提供了丰富的训练和评估材料。
评估任务
研究人员在三个具有挑战性的任务上评估了VideoGLaMM:
1、基础对话生成:
目标:生成与视频内容相关的对话。 结果:VideoGLaMM 在生成自然和相关的对话方面表现优异。
2、视觉定位:
目标:根据文本指令在视频中进行精确的像素级定位。 结果:VideoGLaMM 能够生成精确的掩码,实现细粒度的像素级定位。
3、引用视频分割:
目标:根据文本指令对视频中的特定对象进行分割。 结果:VideoGLaMM 在分割任务上表现出色,能够准确地分割出指定的对象。
实验结果表明,VideoGLaMM 在所有三个任务上始终优于现有方法,特别是在细粒度的像素级定位方面表现突出。
应用前景
VideoGLaMM 的提出为视频与文本之间的细粒度对齐提供了新的解决方案,具有广泛的应用前景:
内容创作:电影和动画制作中,创作者可以使用VideoGLaMM生成精确的视觉效果和对话。 虚拟现实和增强现实:生成逼真的3D和4D场景,提升虚拟现实和增强现实的沉浸感。 自动驾驶和机器人:生成逼真的3D环境,用于自动驾驶和机器人的训练和测试。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











