
图像到视频生成技术已经取得了显著的进步,能够生成高度逼真的视频。然而,调整生成视频中的特定元素,如物体运动或相机移动,通常需要繁琐的试错过程,例如使用不同的随机种子重新生成视频。最近的技术通过微调预训练模型以遵循条件信号(如边界框或点轨迹)来解决这个问题,但这种微调过程计算成本高昂,并且需要带有标注物体运动的数据集,这可能难以获取。
SG-I2V 框架
多伦多大学和矢量研究所的研究人员提出了SG-I2V(Self-Guided Image-to-Video Generation),这是一个自引导的可控图像到视频生成框架,它用于在图像到视频的生成过程中实现对象和相机运动的控制。SG-I2V 的主要特点是通过仅依赖预训练图像到视频扩散模型中的知识,提供零样本控制,而无需微调或外部知识。
例如,给定一张静态图片,用户可以通过指定一系列边界框和相关的轨迹来控制图片中对象的运动。SG-I2V框架能够利用这些信息,在不需要微调或依赖外部知识的情况下,生成一个视频,其中对象按照指定的轨迹移动,从而实现零样本(zero-shot)的控制。

主要功能
- 零样本控制:用户无需进行微调,即可控制视频中对象的运动和相机的动态。
- 对象和相机运动控制:通过指定边界框和轨迹,用户可以控制视频中对象的移动和相机的视角变化。
主要特点
- 自引导(Self-Guided):完全依赖于预训练的图像到视频扩散模型中的知识,不需要额外的微调或外部知识。
- 零样本(Zero-Shot):在没有看到特定类型视频之前,模型就能够根据用户的输入生成具有所需运动的视频。
- 视觉质量和运动保真度:在视觉质量和运动控制的准确性方面,与监督模型相比具有竞争力。
工作原理
SG-I2V的工作原理包括以下几个关键步骤:
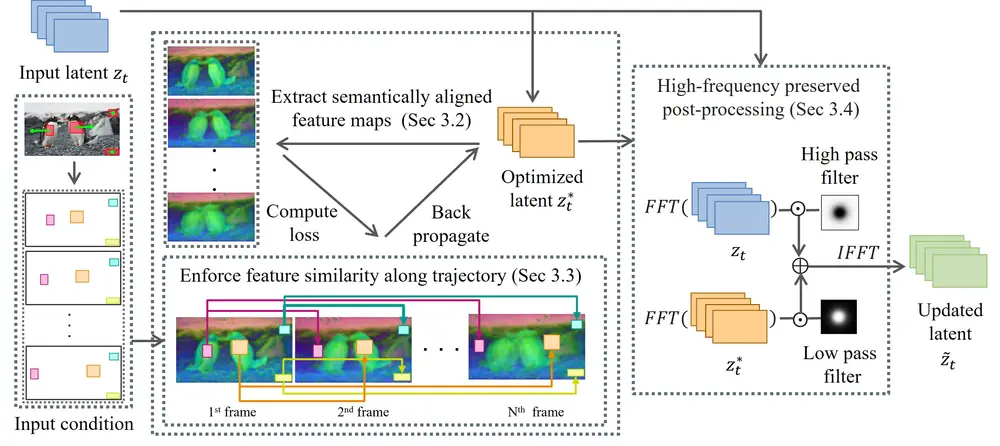
- 特征图提取与对齐:从预训练的视频扩散模型中提取特征图,并通过对齐操作使得特征图在时间维度上具有语义对应性。
- 潜在代码优化:通过优化潜在代码(latent code),使得特征图在边界框轨迹上的特征相似度增加,从而控制视频中对象的运动。
- 高频保持后处理:为了保持生成视频的高质量,采用基于频率的后处理方法,保留原始潜在代码的高频噪声成分。
实验结果
研究人员在多个数据集上进行了广泛的实验,验证了SG-I2V的有效性。实验结果表明:
- 视觉质量:SG-I2V 生成的视频在视觉质量上与监督模型相当,甚至在某些情况下超过了监督模型。
- 运动保真度:SG-I2V 能够精确控制视频中的物体运动和相机移动,保持了高运动保真度。
- 灵活性:用户可以通过简单的条件信号输入,轻松调整生成视频中的特定元素,而无需复杂的微调过程。
应用前景
SG-I2V 的提出为图像到视频生成提供了一种新的、高效的方法,具有广泛的应用前景:
- 内容创作:电影和动画制作中,创作者可以轻松调整视频中的物体运动和相机移动,提高制作效率和效果。
- 虚拟现实和增强现实:生成逼真的3D和4D场景,提升虚拟现实和增强现实的沉浸感。
- 自动驾驶和机器人:生成逼真的3D环境,用于自动驾驶和机器人的训练和测试。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











