由浙江大学和阿里巴巴达摩院的研究团队提出了VideoRefer Suite,旨在提升视频大语言模型(Video LLM)对视频中时空对象的理解能力,解决现有Video LLM在细粒度时空理解方面的不足以及缺乏高质量对象级视频指令数据和全面基准的问题。VideoRefer Suite通过提供大规模、高质量的对象级视频指令数据集(VideoRefer-700K)、一个具备空间-时间对象编码能力的视频LLM模型(VideoRefer),以及一个全面的评估基准(VideoRefer-Bench),来增强模型对视频中任意对象的感知和推理能力。
例如,我们有一个视频,其中包含了一个厨师在厨房中准备菜肴的过程。使用VideoRefer Suite,我们可以询问模型关于视频中特定对象(例如厨师使用的刀具)的具体动作(例如刀具是如何移动的),或者询问关于对象间关系的问题(例如刀具和砧板之间的关系)。VideoRefer Suite能够理解这些指令,并提供精确的答案。

主要功能
- 提供大规模高质量数据集:通过多智能体数据引擎精心策划了包含70万条数据的VideoRefer - 700K数据集,涵盖了详细描述、短描述和多轮问答(QA)对,为视频理解提供了丰富的对象级指令数据,如对视频中特定对象的外观、动作、关系等进行详细描述的文本数据。
- 实现精准时空对象理解:提出的VideoRefer模型配备了通用的时空对象编码器,能够在视频的任何指定时间戳对用户定义的区域进行细粒度感知、推理和检索,例如准确回答关于视频中对象在不同时刻的状态、位置变化以及与其他对象关系的问题。
主要特点
- 数据引擎驱动的高质量数据集:多智能体数据引擎利用多种专家模型协同工作,确保生成的数据集准确性高、相关性强,数据类型丰富多样,包括多种类型的对象级视频指令数据,能有效支持模型对视频内容的深入理解。
- 通用的时空对象编码器:模型中的时空对象编码器具有单帧和多帧两种模式,既能在单帧内精确捕捉对象的空间特征,又能跨多帧聚合时间信息,从而生成灵活且丰富的区域表示,有效处理各种时空视频理解任务。
- 全面的基准评估:开发的VideoRefer - Bench基准包含描述生成(VideoRefer - BenchD)和多项选择问答(VideoRefer - BenchQ)两个子基准,能从多个维度全面评估模型在基于视频的区域理解方面的能力,涵盖了对象描述的准确性、时间动态性、关系推理以及未来预测等多个方面。
工作原理
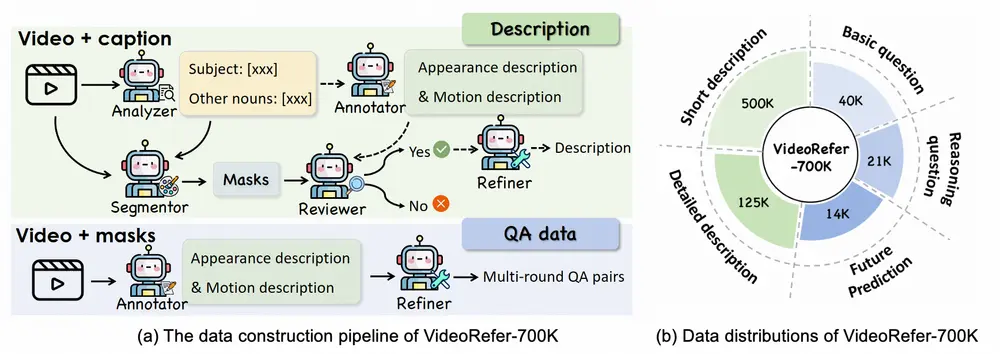
1、数据集构建(VideoRefer - 700K)
- 多智能体数据引擎协作:利用分析器(Analyzer)提取视频场景中的名词(包括主语和其他相关名词),标注器(Annotator)生成对象级的详细描述(通过强调动态动作和静态外观分别查询模型两次),分割器(Segmentor)为提取的名词生成像素级掩码(先从视频中随机选帧并使用GroundingDINO和HQSAM生成掩码,再为每帧生成掩码),审查器(Reviewer)验证掩码与描述的对应关系(使用Osprey提供区域级描述并评估与标注器描述是否一致,保留40%准确样本),精炼器(Refiner)总结和精炼标注器生成的描述以消除重复和幻觉。
- 生成多种数据类型:通过上述流程生成对象级详细描述(12.5万条)、短描述(50万条,用于与LLM预训练对齐对象级编码器)和QA对(7.5万条,涵盖基本问题、推理问题和未来预测,基于多个数据集生成对象级描述后再生成QA对)。
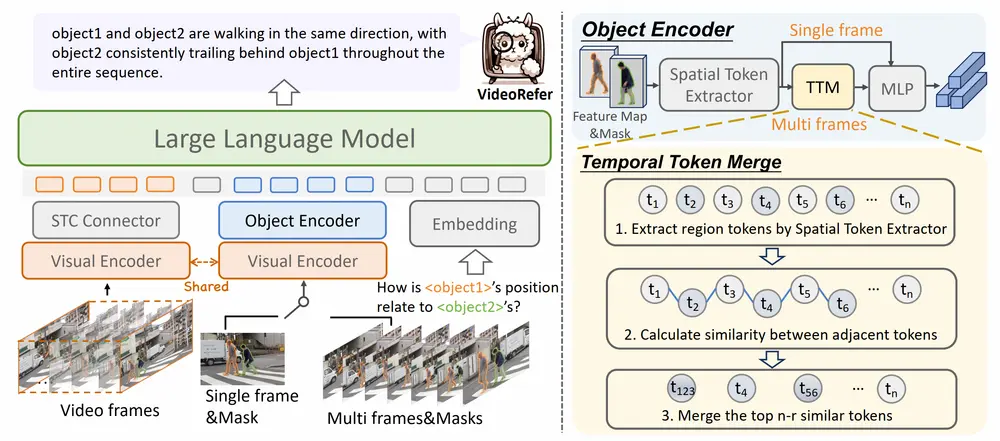
2、模型架构(VideoRefer)
- 基于VideoLLaMA2构建:在已有强大通用场景级视频理解能力的VideoLLaMA2基础上,引入时空对象编码器(REnc)来获取对象级表示。
- 时空对象编码器工作方式
- 单帧模式:输入随机选择的一帧及用户指定区域,通过共享视觉编码器提取图像特征,调整对象掩码形状后进行掩码池化操作获取对象级空间特征,再经MLP层生成对象级令牌。
- 多帧模式:输入视频中的多个选定帧及其对应区域,先提取帧级特征,用空间令牌提取器生成每帧的对象级令牌,然后通过提出的时间令牌合并模块(Temporal Token Merge Module)计算相邻令牌间的余弦相似度,选择相似度较高的部分令牌对进行合并,经平均池化和MLP层生成最终的对象令牌,确保空间完整性和时间连贯性。
3、基准评估(VideoRefer - Bench)
- VideoRefer - BenchD:包含400个精心策划的数据条目,基于Panda - 70M数据集构建测试集,通过人工检查和利用GPT - 4o模型的评估管道,从主体对应、外观描述、时间描述和幻觉检测四个维度对模型生成的描述进行0 - 5分的评分。
- VideoRefer - BenchQ:包含198个来自不同数据集的视频,注释了1000个高质量多项选择题,涵盖基本问题、顺序问题、关系问题、推理问题和未来预测等类型,每个QA对与特定视频区域明确关联,通过计算模型回答的准确率来评估其在解释视频对象方面的能力。
具体应用场景
- 视频内容理解与分析:能够对视频中的对象进行精准描述、关系分析和未来预测,例如在监控视频分析中,理解人员和物体的行为、关系,预测潜在事件;在视频内容审核中,判断视频内容是否符合规定,如检测暴力、色情等不良内容涉及的对象和行为。
- 人机交互与智能视频编辑:辅助用户与视频进行交互,如在视频编辑软件中,根据用户对视频中对象的指定和操作意图,自动生成编辑建议或执行相应编辑操作,如添加特效、剪辑片段等;在智能视频检索中,用户可以通过描述对象的特征和行为来检索相关视频。
- 智能视频辅助创作:为视频创作者提供创意启发和辅助,例如在影视创作中,帮助编剧构思情节,通过分析已有视频素材中的对象和场景关系,提供可能的剧情发展方向;在广告创作中,分析产品视频中对象的展示效果,优化广告创意。