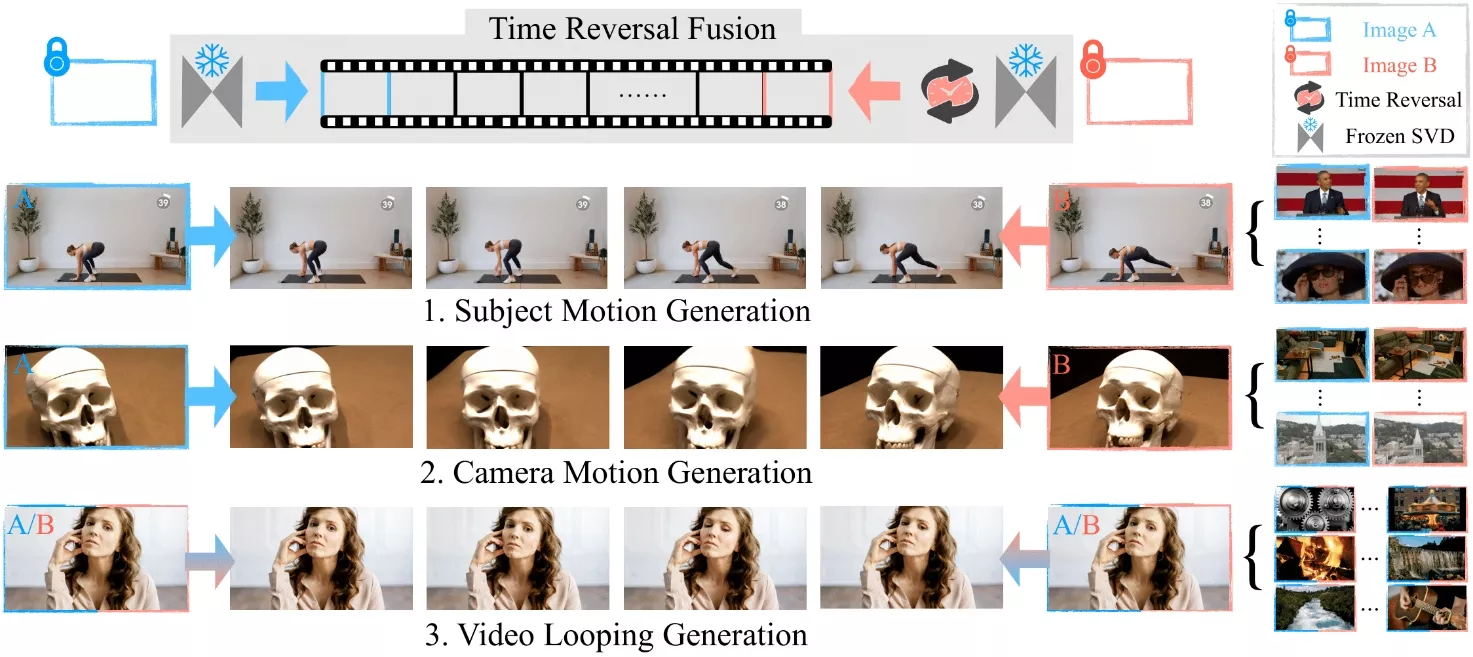
来自马克斯·普朗克智能系统研究所、Adobe和加州大学圣地亚哥分校的研究团队推出新型视频生成方法Time Reversal Fusion(时间反转融合,简称TRF),它能够控制视频内容在给定的起始和结束帧之间进行生成。它通过创新的采样策略和噪声注入技术,使得在不训练模型的情况下,也能够生成具有复杂动态和一致性视角的视频内容。
想象一下,你有两张照片,一张是一个跳跃的人在半空中的照片,另一张是这个人即将着地的照片。使用TRF,你可以生成一个视频,展示这个人从空中跳跃到着地的整个过程,即使这两张照片之间没有连续的帧。
主要功能和特点:
- 探索性中间帧生成: TRF能够在两个关键帧之间生成任意的相机和主题动作,而不需要额外的训练或微调。
- 时间反转融合策略: 通过结合时间正向和反向的去噪路径,TRF能够生成平滑的过渡帧,从而连接起始和结束帧。
- 无需训练: TRF利用了图像到视频(I2V)模型的内在泛化能力,无需对原始模型进行任何训练或微调。
工作原理:
- 双路径生成: TRF同时从起始帧和结束帧开始两个生成路径,一个正向生成,一个反向生成。
- 路径融合: 在每个去噪步骤中,TRF将正向和反向生成的输出进行融合,生成新的视频帧。
- 噪声注入: 为了确保帧之间的平滑过渡,TRF在融合过程中引入了额外的随机性,称为噪声注入。
具体应用场景:
- 动态主题生成: 可以生成展示人物或物体运动的视频,例如从跳跃到着地的过程。
- 相机运动生成: 能够合成从不同视角拍摄的静态场景的视频,填补两个视角之间的运动轨迹。
- 视频循环生成: 当起始帧和结束帧相同的时候,TRF可以生成循环播放的视频,例如一个波浪不断起伏的循环视频。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











