
智源研究院推出Emu3,这是一个全新的多模态系列模型,它仅使用下一个词元(Token)预测这一建模范式进行训练,达到了最先进的水平。Emu3 通过一个 Transformer 模型在视频、图像和文本令牌的混合数据上进行训练,以预测下一个令牌。在有视频上下文的情况下,Emu3 能够自然地扩展视频并预测接下来的发生。该模型可以模拟物理世界中的环境、人物和动物的某些方面。
- 项目主页:https://emu.baai.ac.cn/about
- GitHub:https://github.com/baaivision/Emu3
- 模型:https://huggingface.co/collections/BAAI/emu3-66f4e64f70850ff358a2e60f
想象一下,你有一台超级聪明的机器,它可以观看视频、阅读文字,甚至根据你给出的文字提示创造出新的图像和视频。Emu3就是这样一种机器,不过它是一套AI模型,而非真实的机器。比如,你给出一个文本提示:“一只小猫在软软的沙发上打盹”。Emu3可以生成一张图片,展示这个场景。或者,你给它一个视频,它能够预测视频中的小猫接下来可能会伸懒腰。通过这种方式,Emu3能够成为艺术家、设计师、内容创作者以及任何需要图像和视频生成工具的人的得力助手。
主要功能
Emu3的主要功能包括:
- 图像生成:根据文本提示生成图片。
- 视频生成:不仅生成视频,还能预测视频中接下来会发生什么。
- 视觉-语言理解:理解图像内容并用语言描述,或者根据图像内容回答有关问题。
主要特点
Emu3的一些关键特点有:
- 多模态能力:能够处理和理解图像、视频和文本。
- 无需扩散模型或组合方法:它不需要其他复杂模型的帮助。
- 开源:它的技术和模型是公开的,这意味着任何人都可以查看、使用和改进它。
工作原理
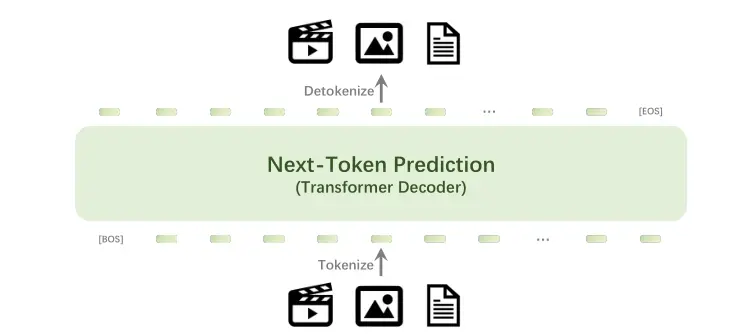
Emu3的工作原理大致如下:
- 将数据转换为标记:无论是图像、视频还是文本,Emu3都会将它们转换成一系列的标记,就像把一句话分成单词一样。
- 训练单一变换器:Emu3使用一个变换器(一种人工智能算法)来学习这些标记的模式。
- 预测下一个标记:给定一系列标记后,Emu3的任务是预测接下来最可能出现的标记。
具体应用场景
Emu3可以应用在许多场景中,例如:
- 内容创作:帮助艺术家和设计师快速生成图像和视频概念。
- 自动字幕生成:为视频自动生成描述性的字幕。
- 视觉问答:回答有关图像内容的问题,比如“图片中的人在做什么?”。
- 虚拟现实和游戏:创造逼真的虚拟环境和游戏体验。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











