
在互联互通的世界中,跨多种语言和媒介的有效沟通变得越来越重要。多模态AI在结合图像和文本以实现不同语言的无缝检索和理解方面面临着诸多挑战。现有的模型在英语中表现良好,但在其他语言中则表现不佳。此外,同时处理文本和图像的高维数据在计算上非常密集,限制了非英语使用者和需要多语言背景场景的应用。
- 官方介绍:https://jina.ai/news/jina-clip-v2-multilingual-multimodal-embeddings-for-text-and-images
- 模型:https://huggingface.co/jinaai/jina-clip-v2
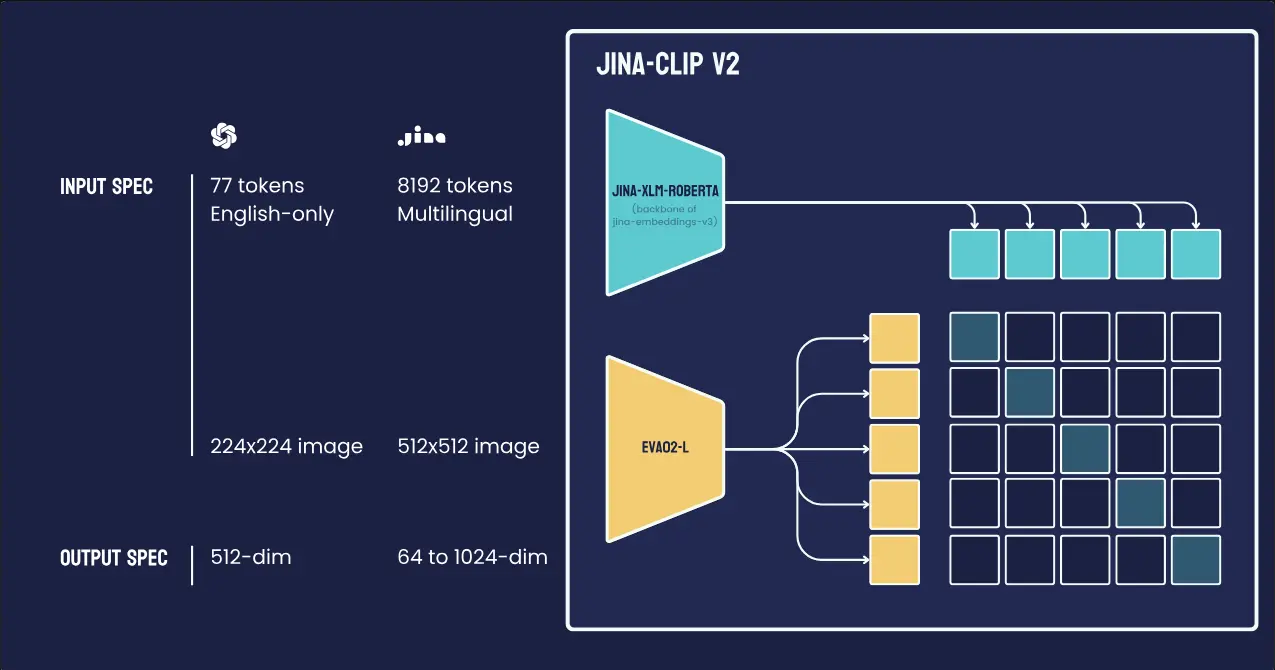
为了解决这些问题,Jina AI 推出了 Jina-CLIP v2——一款拥有90亿参数的多语言多模态嵌入模型,能够在89种语言中将图像与文本连接起来。Jina-CLIP v2 支持广泛的语言,解决了之前限制访问高级多模态人工智能技术的局限性。它能够处理512×512分辨率的图像,并处理最多8000个令牌的文本,有效地解决了将图像与多语言文本连接的问题。
技术细节
Jina-CLIP v2是基于 Jina-CLIP v1 和Jina-Embeddings v3 构建的新型通用多语言多模态嵌入模型,具有几项关键改进。

性能提升
文本-图像和文本-文本检索任务:Jina-CLIP v2 在这些任务中比 v1 提升了3%的性能。 多语言长上下文密集检索器:v2 的文本编码器可以作为一个有效的多语言长上下文密集检索器,其性能与我们的前沿模型 Jina-Embeddings v3 相当(目前是 MTEB 上参数小于1B的最佳多语言嵌入)。
多语言支持
89种语言:由 Jina-Embeddings v3 驱动的文本塔,Jina-CLIP v2 支持89种语言的多语言图像检索。 性能提升:在多语言图像检索任务中,Jina-CLIP v2 比 nllb-clip-large-siglip 显示出高达4%的改进。
更高的图像分辨率
512x512输入图像分辨率:v2 现在支持512x512的输入图像分辨率,显著高于 v1 的224x224。这种更高的分辨率使得对细节图像的处理更好,特征提取更佳,对细粒度视觉元素的识别更准确。
俄罗斯套娃表示
灵活的嵌入维度:v2 允许用户将文本和图像嵌入的输出维度从1024截断到64,减少了存储和处理开销,同时保持强大的性能。这种灵活性使得模型适用于各种应用场景,从计算密集型的深度学习任务到轻量级的移动应用程序。
技术细节
灵活性和效率
Jina-CLIP v2 以其灵活性和效率而著称。它不仅能够在大规模维度上生成嵌入,还能在小规模上生成嵌入。其 Matryoshka 表示法功能将嵌入维度减少到64维,允许用户根据具体需求调整嵌入过程,无论是计算密集型的深度学习任务还是轻量级的移动应用程序。
文本编码器
模型的文本编码器可以作为密集检索器独立运行,与 jina-embeddings-v3 的性能相匹配——jina-embeddings-v3 是在多语言文本嵌入基准(MTEB)下1亿参数以下多语言嵌入的当前领导者。这种多功能性使得 Jina-CLIP v2 适用于各种用例,从多语言搜索引擎到上下文感知推荐系统。
减少偏见
Jina-CLIP v2 在减少语言模型中的偏见方面迈出了重要一步,特别是对于那些依赖不太广泛使用的语言的用户。在评估中,该模型在多语言检索任务中表现良好,展示了其与专业文本模型相匹配或超越其性能的能力。
Matryoshka 表示法
Matryoshka 表示法确保了嵌入计算可以在不牺牲准确性的情况下高效完成,使得在资源受限环境中部署成为可能。这种表示法通过逐步减少嵌入维度,保留了必要的上下文信息,同时降低了计算复杂度。
应用场景
Jina-CLIP v2 能够在89种语言中连接文本和图像,为公司和开发人员创造了新的可能性,使他们能够创建易于不同用户访问且保持上下文准确性的AI。这可以对以下应用产生重大影响:
电子商务:通过多语言图像和文本搜索,提高用户体验和购物满意度。 内容推荐:提供个性化的多语言内容推荐,增强用户参与度。 视觉搜索系统:实现跨语言的图像和文本搜索,帮助用户快速找到所需信息。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...





