
要让机器人走进真实世界,完成诸如“把苹果放进桌上的红碗”这样的任务,仅靠预设程序远远不够。它必须具备两项关键能力:
- 理解复杂语义——分辨“红碗”是颜色还是材质?“桌上”是否包含边缘?
- 生成精确动作——如何抓取、移动路径、避障、放置力度?
然而,当前大多数视觉-语言-动作(Vision-Language-Action, VLA)模型在这两者之间难以兼顾:要么偏重推理而动作粗糙,要么依赖特定任务数据、泛化能力弱,甚至在训练中遗忘原有的视觉语言理解能力。
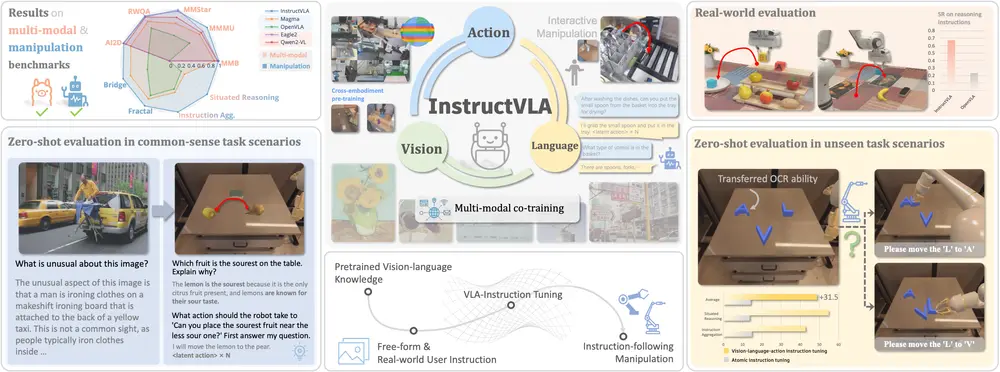
为解决这一矛盾,来自中国科学技术大学、浙江大学、上海市人工智能实验室的研究团队提出 InstructVLA ——一种端到端的 VLA 模型,首次在不牺牲多模态推理能力的前提下,实现领先的机器人操控性能。
它的核心突破在于:将动作生成视为“指令遵循”的一部分,而非独立模块。通过一种全新的训练范式,InstructVLA 实现了语言理解与动作控制的深度融合。
问题本质:为什么现有 VLA 模型“顾此失彼”?
传统 VLA 模型通常采用两阶段设计:
- 视觉语言模型(VLM)负责理解指令和场景;
- 动作模型基于 VLM 输出生成控制信号。
但这种“拼接式”架构存在明显短板:
- 知识遗忘:微调过程中,VLM 的原始语义理解能力容易退化;
- 任务割裂:语言推理与动作生成脱节,导致“想得到,做不对”;
- 泛化受限:依赖特定环境的操控数据,难以适应新指令或新场景。
InstructVLA 的目标,正是打破这一瓶颈,构建一个既能“思考”又能“动手”的统一模型。
核心创新:VLA-IT 训练范式
InstructVLA 的关键在于其提出的 视觉-语言-动作指令调优(Vision-Language-Action Instruction Tuning, VLA-IT) 范式。该方法通过联合优化语言推理与动作生成,实现真正的多模态协同。
1. 多模态数据融合训练
模型在两类数据上共同训练:
- 标准 VLM 语料库:保持强大的图文理解与语言推理能力;
- 65 万条 VLA-IT 样本:涵盖多样化指令、场景描述与高质量动作轨迹,覆盖抓取、放置、开合、堆叠等常见操作。
这种联合训练策略有效防止了预训练知识的“灾难性遗忘”,同时将动作能力自然嵌入到指令理解流程中。
2. 混合专家(MoE)架构:动态切换推理与执行
InstructVLA 采用 Mixture-of-Experts(MoE)框架,允许模型根据任务需求动态分配资源:
- 面对“请描述这个场景”类问题,激活语言推理专家;
- 接到“把左边的积木放进盒子”指令时,自动切换至动作生成路径。
这种机制使模型在复杂任务中具备灵活的决策能力,避免“一刀切”的模式切换。
3. 动作专家 + VLM 协同解码
最终动作由一个基于 流量匹配(Flow Matching) 的动作专家解码生成,但其输入来自 VLM 提供的语义丰富表征。这意味着:
- 动作不仅基于像素或坐标,更理解“为什么这么做”;
- 指令中的隐含逻辑(如“小心轻放”)可被转化为力控参数。
评估体系:更贴近真实需求的基准测试
为了全面评估模型能力,研究团队构建了两个关键资源:
✅ VLA-IT 数据集:65 万条高质量人-机交互样本
- 包含自然语言指令、视觉观测、动作序列三元组;
- 覆盖家庭、办公、实验室等多种场景;
- 支持细粒度指令理解(如空间关系、属性识别、时序分解)。
✅ SimplerEnv-Instruct:80 个零样本任务的挑战性基准
不同于传统闭环控制任务,该基准强调:
- 高级语义理解:如“把上次拿的物体放回去”
- 情境推理:需结合历史状态判断当前动作
- 子任务分解:如“打开抽屉→取出杯子→倒水”
这一设置更贴近真实人机交互场景,测试模型是否真正“理解”指令。
实验结果:全面领先,泛化能力强
1. 在 SimplerEnv 上的表现
| 模型 | 成功率 |
|---|---|
| SpatialVLA | 基线 |
| InstructVLA | +30.5% |
在标准操控任务中,InstructVLA 显著优于现有方法,验证其动作精度优势。
2. 在 SimplerEnv-Instruct 上的零样本性能
| 对比对象 | 相对提升 |
|---|---|
| 微调后的 OpenVLA | +92% |
| GPT-4o 辅助动作专家 | +29% |
这表明 InstructVLA 不仅能执行明确指令,还能处理需要上下文记忆和逻辑推理的复杂任务。
3. 真实世界部署表现
- 在 WidowX-250 机械臂上的零样本任务中,成功率比 OpenVLA 高出 23.3%
- 在 Franka Research 3 机械臂上进行小样本适配后,快速掌握新任务
说明模型具备良好的跨平台迁移能力。
4. 多模态理解能力保留
在 MMMU 等标准多模态理解评测中,InstructVLA 准确率达 44.8%,超过 Eagle2、Qwen2-VL 等专用 VLM 模型,证明其未因引入动作训练而损失语义能力。
工作流程简述
InstructVLA 的运行流程如下:
- 输入:一张环境图像 + 自然语言指令(如“把绿色方块移到蓝色圆圈右边”)
- 语义解析:VLM 分析图像内容,理解物体、空间关系与任务目标
- 路径规划:MoE 框架决定是否调用动作专家,生成潜在动作序列
- 动作解码:流量匹配模型将语义指令映射为连续控制信号
- 执行与反馈:机器人执行动作,系统可闭环调整后续行为
整个过程无需任务特定代码,完全由模型自主完成。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











