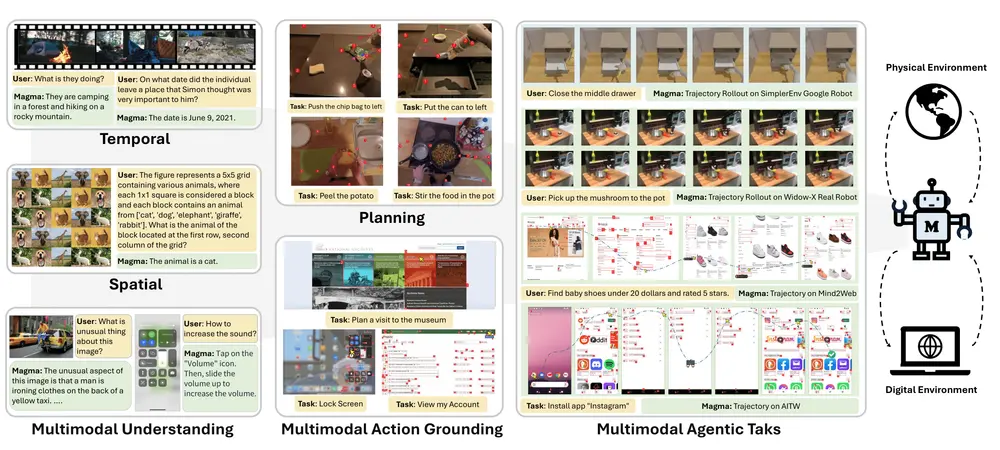
腾讯、上海交通大学与清华大学联合推出 POINTS-Reader —— WePOINTS 家族最新成员,一款专为文档图像转文本设计的轻量级视觉-语言模型(VLM)。
它不追求参数规模,也不依赖教师模型“蒸馏”,而是通过一套两阶段自进化框架,在保持结构极简的同时,实现对中英文复杂文档(含表格、公式、多栏排版)的高精度端到端识别。

更重要的是:输入一张图,输出一段文本,无需后处理 —— 所见即所得,开箱即用。
为什么值得关注?
当前主流文档识别方案,普遍存在两个痛点:
- 依赖蒸馏:用大模型生成伪标签训练小模型,导致小模型性能被“教师”上限锁定;
- 后处理复杂:OCR 输出需额外解析、排版、纠错,流程繁琐,部署成本高。
POINTS-Reader 的目标很明确:
✅ 摆脱蒸馏依赖
✅ 端到端直接输出最终文本
✅ 轻量高效,适合工业部署
核心设计:极简架构 + 自进化训练
1. 模型结构极简
- 基于 POINTS1.5 架构,仅将语言模型从 Qwen2.5-7B 替换为 Qwen2.5-3B;
- 视觉编码器沿用 600M 参数的 NaViT(平衡精度与吞吐);
- 输入 = 固定提示词 + 文档图像
输出 = 一段结构化文本(含普通文字、表格、公式)
举例:输入一张含表格和公式的 PDF 截图 → 输出一段 Markdown 格式文本,可直接粘贴使用。
2. 两阶段自进化训练框架
第一阶段:统一格式预热(UWS)
- 合成数据生成:利用大语言模型自动生成海量带结构的文档样本(文本+表格+公式);
- 格式标准化:所有元素统一为可解析的中间表示(如 Markdown / LaTeX);
- 模型微调:在合成数据上训练基础模型,获得初步文档理解能力。
第二阶段:迭代自改进(ISS)
- 真实数据标注:用预热模型处理真实文档,生成初始标注;
- 智能过滤:通过规则+置信度过滤低质量样本;
- 重训练迭代:用高质量样本重新训练模型 → 生成更优标注 → 再训练 → 循环提升。
✅ 关键优势:
- 不依赖外部教师模型,避免性能天花板;
- 数据与模型同步进化,越训越准;
- 方法通用,可迁移至其他 VLM 任务。
性能表现
在 OmniDocBench 基准测试中:
| 语言 | 得分(越低越好) |
|---|---|
| 英文 | 0.133 |
| 中文 | 0.212 |
注:该分数为“编辑距离误差率”,数值越低表示识别越准。
尽管模型参数量远小于多数竞品,但在复杂版式文档(含表格、公式、混合排版)上的表现,已超越部分更大规模的公开与闭源模型。
高吞吐推理支持
为满足工业级部署需求,POINTS-Reader 已适配主流推理框架:
- SGLang:已支持,实测吞吐表现优异;
- vLLM:即将支持,进一步优化并发与显存效率。
选择 600M ViT 而非更大视觉编码器,正是为了在精度与速度之间取得最佳平衡 —— 尤其在批量处理场景下,吞吐优势明显。
适用场景
- 企业文档自动化录入(合同、报表、发票)
- 教育资料数字化(试卷、讲义、论文)
- 科研文献结构化提取(含公式与表格)
- 政府/金融行业非结构化数据处理
- 移动端或边缘设备轻量部署
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











