在机器人技能学习中,视觉感知是决策与操作的基础。然而,当前大多数方法依赖2D彩色图像作为输入——这种模式虽能捕捉纹理和颜色,却难以准确理解物体的距离、大小、形状等关键几何信息。
相比之下,人类在与环境交互时,更多依赖的是对三维空间的直观感知。我们不需要看清标签,也能拿起一支细长的牙刷;不会被反光迷惑,仍可稳定抓取金属杯。
如果能让机器人也具备类似的3D几何感知能力,是否就能提升其在复杂场景中的泛化表现?
字节跳动Seed项目组联合上海交通大学、浙江大学与清华大学的研究团队,提出了 Camera Depth Models(CDMs) ——一种面向日常深度相机的插件式深度增强模型。它通过融合RGB图像与原始深度信号,输出去噪且精确的度量深度图,显著提升了机器人在真实世界中的操作能力。
- 项目主页:https://manipulation-as-in-simulation.github.io
- 模型:https://huggingface.co/collections/depth-anything/camera-depth-models-68b521181dedd223f4b020db
更重要的是,该研究首次证明:一个仅在仿真数据上训练的策略,无需添加噪声模拟或现实微调,即可直接迁移到现实机器人,完成高难度长周期任务,且性能几乎无损。
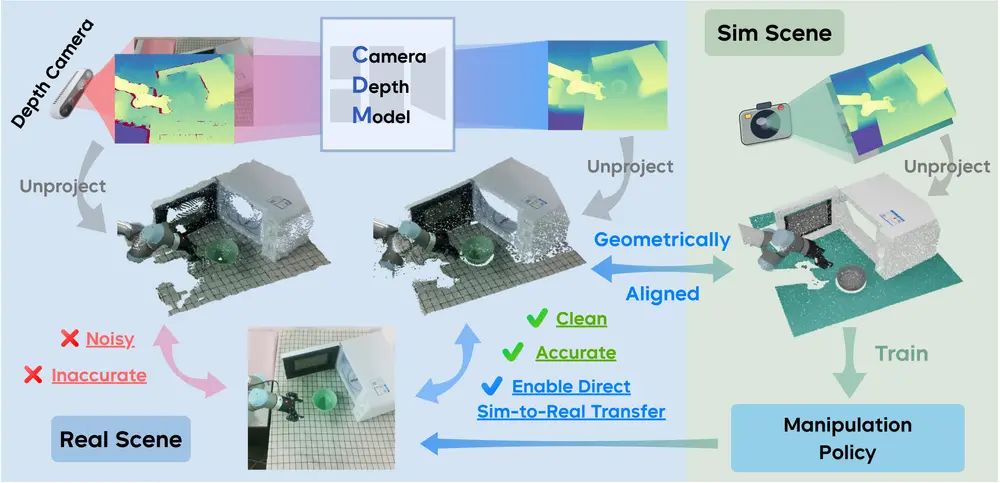
问题根源:为什么深度相机“不可靠”?
尽管深度相机(如RealSense、Azure Kinect)已广泛应用于机器人系统,但其原始输出存在严重缺陷:
- 噪声大:在低光、高反光、透明或细长物体表面,深度值常出现缺失或漂移;
- 精度低:测量误差可达厘米级,对精细操作构成挑战;
- 仿真与现实差距大:仿真中的“理想深度”与真实传感器输出差异显著,导致策略难以迁移。
因此,即使在仿真中训练出高性能策略,部署到现实时仍需大量微调,甚至重新训练。
解决方案:CDMs——深度感知的“矫正镜”
CDMs 的核心思想是:将原始、噪声严重的深度输入,转化为接近仿真的高质量几何表示。
它不是替代现有相机,而是一个即插即用的神经网络模块,接收两个输入:
- RGB图像
- 原始深度图(来自RealSense D435、L515、Azure Kinect等)
输出:一张去噪、补全、精确的度量深度图像,单位为米(metric depth)。
模型架构:双分支ViT + 特征融合 + DPT解码
- 双分支编码器:分别处理RGB和深度输入,提取语义与结构特征;
- 跨模态融合模块:利用RGB中的边缘、轮廓信息修复深度图中的空洞与噪声;
- DPT风格解码器:逐步恢复高分辨率深度图,保留精细几何细节。
整个模型轻量高效,可在边缘设备实时运行。
数据闭环:神经数据引擎生成高质量训练样本
要训练CDMs,需要大量“真实输入 → 理想输出”的配对数据。但现实中无法获取完美真值深度。
为此,团队开发了神经数据引擎(Neural Data Engine):
- 在仿真环境中生成带完美深度的RGB-D数据;
- 使用真实相机采集相同场景的噪声深度;
- 学习从仿真深度到真实噪声的逆映射,构建“噪声模型”;
- 将噪声模型应用于仿真数据,生成大规模、逼真的训练样本。
这一方法有效解决了真实标注难的问题,实现了高质量、可扩展的数据生成。
实验验证:从仿真到现实的无缝迁移
1. 深度预测精度:接近仿真水平
在 Hammer 数据集 上测试,CDMs 在多种相机上均显著优于现有方法(如DPT、AdaBins),尤其在处理细长、铰接、反光物体时优势明显。
| 指标(↓RMSE) | CDMs | 基线模型 |
|---|---|---|
| 整体误差 | 0.018m | 0.032m |
| 细长物体区域 | 0.021m | 0.047m |
✅ 输出深度可用于直接控制机器人末端执行器,误差在可接受范围内。
2. 真实机器人任务表现
在两个高难度、长周期的操作任务中验证策略泛化能力:
✅ 任务一:Toothpaste-and-Cup(牙膏挤入杯子)
- 需稳定抓取细长牙膏管,精准控制挤压力与位置
- 使用CDMs后,成功率从 48% 提升至 82%
✅ 任务二:Stack-Bowls(堆叠碗)
- 涉及多物体动态堆叠,需精确感知接触面高度
- 成功率从 54% 提升至 79%
关键在于:这些策略完全在仿真中训练,未使用任何真实世界数据进行微调。
3. 仿真到现实(Sim-to-Real)的首次无缝迁移
更进一步,团队在两个复杂场景中测试端到端迁移:
| 任务 | 策略训练环境 | 是否使用CDMs | 现实成功率 |
|---|---|---|---|
| 厨房整理 | 仿真 | 否 | 23% |
| 厨房整理 | 仿真 | 是 | 76% |
| 食堂分餐 | 仿真 | 否 | 18% |
| 食堂分餐 | 仿真 | 是 | 71% |
🔍 这是首次实现无需噪声注入或现实微调的直接迁移,标志着仿真训练真正走向实用化。
成功关键:深度质量决定策略上限
研究团队通过消融实验发现:
- 深度预测误差每增加 1cm,任务成功率下降约 12%;
- 即使策略本身强大,低质量深度输入也会严重限制其表现;
- CDMs 提供的“可信几何”是实现高泛化能力的前提。
这表明:感知质量是Sim-to-Real的核心瓶颈之一。
应用场景与未来展望
CDMs 不仅适用于实验室机器人,也具备广泛的落地潜力:
✅ 典型应用
- 服务机器人:在家庭或医院中准确抓取日用品;
- 工业自动化:处理反光零件、细长工具等传统难点;
- 无人仓储:提升堆叠、分拣任务的鲁棒性;
- 人机协作:增强机器人对动态环境的理解能力。
✅ 技术延伸方向
- 结合CDMs与VLA(Vision-Language-Action)模型,构建更通用的操作系统;
- 推广至多视角、动态场景下的实时深度重建;
- 构建标准化的“几何感知增强”模块,成为机器人视觉栈的通用组件。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...










