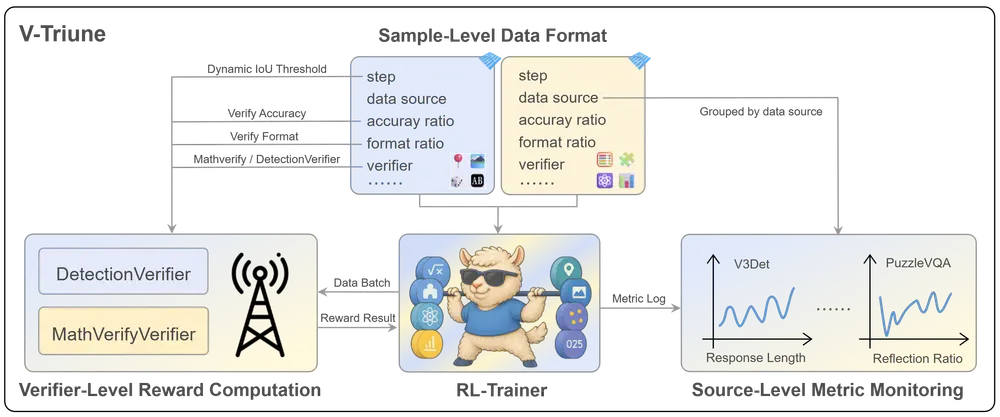
MiniMax推出视觉三重统一强化学习(RL)系统 V-Triune ,使视觉语言模型能够在单一训练流程中联合学习视觉推理和感知任务。该系统通过整合三个互补组件——样本级数据格式化(Sample-Level Data Formatting)、验证器级奖励计算(Verifier-Level Reward Computation)和源级指标监控(Source-Level Metric Monitoring)——实现了对视觉推理和感知任务的统一训练。
- GitHub:https://github.com/MiniMax-AI/One-RL-to-See-Them-All
- 模型:https://huggingface.co/One-RL-to-See-Them-All
例如,在一个复杂的视觉场景中,模型需要同时完成数学问题的解答(视觉推理任务)和物体检测(视觉感知任务)。V-Triune 系统能够让模型在同一个训练框架下,既学会如何通过逻辑推理解决数学问题,又能准确地检测出场景中的物体。

主要功能
- 联合训练视觉推理和感知任务:V-Triune 系统能够在一个统一的训练流程中同时处理视觉推理(如数学问题解答、图表理解)和视觉感知(如物体检测、目标定位)任务。
- 动态奖励机制:引入动态 IoU(Intersection over Union)奖励机制,针对视觉感知任务提供自适应、渐进式的反馈,确保模型在训练过程中获得稳定的性能提升。
- 数据格式化与验证器定制:通过样本级数据格式化,允许每个样本定义自己的奖励设置和验证器,提高了系统的灵活性和可扩展性。
- 源级指标监控:在数据源级别监控训练指标,帮助诊断数据问题,确保多任务、多源学习的稳定性。
主要特点
- 统一性:首次将视觉推理和感知任务整合到一个强化学习框架中,打破了以往研究中任务领域的限制。
- 灵活性:通过样本级数据格式化和验证器级奖励计算,系统能够灵活处理多样化的任务和数据源。
- 稳定性:动态 IoU 奖励机制和源级指标监控确保了训练过程的稳定性,即使在复杂的多任务场景下也能保持良好的性能。
- 可扩展性:系统设计允许轻松添加新任务或更新奖励逻辑,无需修改核心训练流程。
工作原理
- 样本级数据格式化:每个样本可以定义自己的奖励设置和验证器,使得系统能够灵活处理不同任务的需求。
- 验证器级奖励计算:将奖励计算任务分配给专门的验证器,每个验证器负责特定任务组的奖励生成,提高了系统的模块化和可扩展性。
- 动态 IoU 奖励机制:针对视觉感知任务,动态调整 IoU 奖励阈值,从宽松到严格逐步引导模型学习,确保早期学习信号的有用性和后期的高精度结果。
- 源级指标监控:在数据源级别监控训练指标,实时诊断数据问题,确保多任务、多源学习的稳定性。
测试结果
在 MEGA-Bench Core 基准测试中,V-Triune 系统训练的 Orsta 模型在 7B 和 32B 的不同变体上均取得了显著的性能提升,改进范围从 +2.1% 到 +14.1%。这些性能提升不仅体现在视觉推理任务上,也体现在视觉感知任务上,如物体检测、目标定位等。此外,Orsta 模型在其他下游任务(如 MMMU、MathVista、COCO 和 CountBench)上也表现出色,验证了 V-Triune 方法的有效性和可扩展性。
应用场景
- 智能视觉问答系统:能够同时处理复杂的推理问题和精确的视觉感知任务,为用户提供更准确、更全面的答案。
- 自动驾驶辅助系统:在复杂的交通场景中,模型可以同时进行物体检测、目标定位和场景理解,提高自动驾驶的安全性和可靠性。
- 智能教育工具:在教育场景中,模型可以辅助学生解决数学问题、理解图表和科学问题,提供个性化的学习支持。
- 工业自动化:在工业生产中,模型可以用于质量检测、目标定位和缺陷识别,提高生产效率和产品质量。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











