
谷歌近日推出了一款面向医疗领域的开源模型系列 —— MedGemma,该模型基于 Gemma 3 构建,在医学图像识别与文本理解方面表现出色,标志着医疗 AI 在开源方向上的重要进展。
MedGemma 提供两种变体:
- MedGemma 4B(40亿参数):多模态版本,支持 X 光、CT 图像分析等任务。
- MedGemma 27B(270亿参数):纯文本版本,专注于医疗文档处理与临床推理。
这两款模型均在多种临床相关基准测试中表现优异,开发者可基于其进行适配,开发用于辅助诊断、病历分析、患者分诊等场景的医疗 AI 应用。
- GitHub:https://github.com/Google-Health/medgemma
- 模型:https://huggingface.co/collections/google/medgemma-release-680aade845f90bec6a3f60c4
- Demo:https://huggingface.co/spaces/google/rad_explain
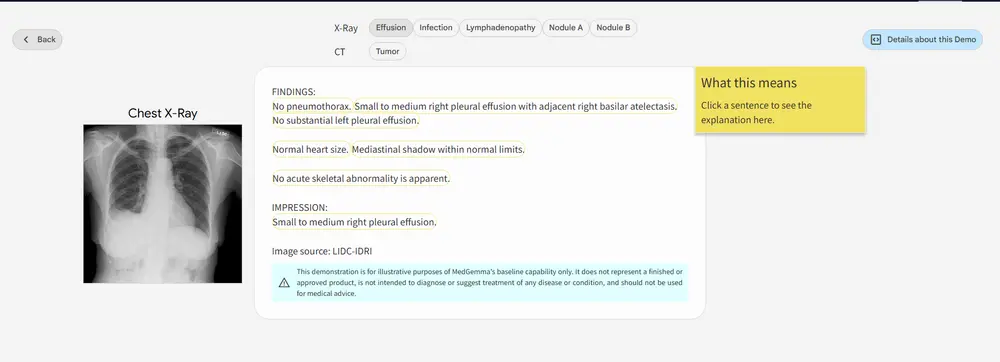
模型架构与训练数据
MedGemma 4B(多模态)
该版本采用 SigLIP 图像编码器,并结合一个强大的大语言模型组件,使其能够同时理解和描述医疗图像内容。
训练数据包括大量去标识化的医学图像资料,涵盖:
- 胸部 X 光片
- 皮肤病图像
- 眼科图像
- 组织病理切片
此外,语言模型部分也在这些图像所附带的报告和注释上进行了训练,使模型具备跨模态理解能力。
版本说明:
- -pt(预训练):适用于希望从头开始实验的开发者。
- -it(指令调整):更适合大多数应用场景,已针对自然语言交互进行优化。
MedGemma 27B(纯文本)
仅在医疗文本上训练,专注于理解医学术语、电子病历、影像报告等内容。该版本仅提供 指令调整版(-it),并针对推理效率进行了优化。
主要功能与适用场景
1. 医疗图像分类
MedGemma 4B 可用于放射学、数字病理、眼科和皮肤图像的自动分类任务。虽然其性能在公开数据集上表现良好,但开发者仍需根据实际需求进行验证和调优。
2. 医疗图像解读
该模型可以生成对图像的自然语言描述,适用于自动生成影像报告、辅助医生快速获取关键信息。尽管当前版本尚未达到临床级精度,但通过微调可进一步提升实用性。
3. 医疗文本理解与临床推理
MedGemma 27B 更适合处理复杂医学文本,如患者访谈记录、电子健康档案(EHR)、医嘱摘要等任务。它可用于:
- 自动化问诊系统
- 分诊建议生成
- 临床决策支持
- 医疗知识问答系统
对于多数任务,推荐使用更大参数量的 MedGemma 27B 以获得更好的准确性。
如何适配与优化 MedGemma
作为一款为开发者设计的工具,MedGemma 需要根据具体任务进行适配和调优。以下是几种常见方法:
1. 提示工程 / 上下文学习(Prompt Engineering)
在某些简单任务中,只需精心设计提示词(prompt),就能获得令人满意的输出结果。开发者还可以利用上下文学习(few-shot learning)来引导模型完成特定任务。
✅ 建议:即使是提示工程,也应经过充分验证,确保输出可靠。
2. 微调(Fine-tuning)
开发者可以通过微调进一步提升模型在特定任务中的表现。例如:
- 使用 LoRA(低秩适配)技术进行高效微调
- 对图像编码器与语言解码器联合训练
- 添加新任务类型,如疾病预测、治疗建议生成等
谷歌官方提供了微调 Notebook 示例,帮助开发者快速入门。
3. 代理编排(Agent Orchestration)
MedGemma 可集成到更复杂的 AI 系统中,作为局部智能单元发挥作用。例如:
- 结合网络搜索获取最新指南
- 利用 FHIR 协议生成/解析医疗数据
- 与 Gemini Live 或 Gemini 2.5 Pro 联合使用,实现语音交互或函数调用
- 在本地解析敏感数据后,向云端模型发送匿名请求
📊 性能评估与未来展望
目前,MedGemma 的多个变体已在多个公开及内部数据集上进行了评估,整体表现优于同规模模型。完整的技术白皮书即将发布,届时将披露更多细节。
开发者可根据自身需求选择合适的模型版本,并结合业务场景进行定制化训练,以满足实际应用需求。
🔒 使用条款与注意事项
MedGemma 的使用需遵守 Google 的 Health AI Developer Foundations 使用条款。开发者在部署至生产环境前,务必进行严格的性能测试与合规性审查。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











