
随着智能任务日益复杂,视觉语言大模型(VLM)正从基础的多模态感知迈向更高层次的推理能力提升。为了应对这一趋势,智谱AI 与清华大学联合推出了新一代 VLM 开源模型 —— GLM-4.1V-9B-Thinking。
该模型基于 GLM-4-9B-0414 基座架构,并引入全新的「思考范式」机制,采用课程采样强化学习(Reinforcement Learning with Curriculum Sampling, RLCS),全面增强其推理能力,在多个任务中表现卓越。

在仅拥有 90 亿参数的情况下,GLM-4.1V-9B-Thinking 在 18 项榜单任务中持平甚至超越 Qwen-2.5-VL-72B(参数量为其 8 倍),成为当前 10B 级别视觉语言模型中的佼佼者。
与此同时,研究团队还同步开源了基座模型 GLM-4.1V-9B-Base,为更多研究人员探索视觉语言模型的能力边界提供支持。
模型信息
模型下载地址
| 模型 | 下载地址 | 模型类型 |
|---|---|---|
| GLM-4.1V-9B-Thinking | 🤗Hugging Face 🤖 ModelScope | 推理模型 |
| GLM-4.1V-9B-Base | 🤗Hugging Face 🤖 ModelScope | 基座模型 |
模型算法代码可以查看 transformers 的完整实现。
运行要求
推理
| 设备(单卡) | 框架 | 最低显存占用 | 速度 | 精度 |
|---|---|---|---|---|
| NVIDIA A100 | transformers | 22GB | 14 - 22 Tokens / s | BF16 |
| NVIDIA A100 | vLLM | 22GB | 60 - 70 Tokens / s | BF16 |
微调
该部分数据使用 LLaMA-Factory 提供的图片微调方案进行测试。
| 设备(集群) | 策略 | 最低显存占用 / 需要卡数 | 批大小 (per GPUs) | 冻结情况 |
|---|---|---|---|---|
| NVIDIA A100 | LORA | 21GB / 1卡 | 1 | 冻结 VIT |
| NVIDIA A100 | FULL ZERO2 | 280GB / 4卡 | 1 | 冻结 VIT |
| NVIDIA A100 | FULL ZERO3 | 192GB / 4卡 | 1 | 冻结 VIT |
| NVIDIA A100 | FULL ZERO2 | 304GB / 4卡 | 1 | 不冻结 |
| NVIDIA A100 | FULL ZERO3 | 210GB / 4卡 | 1 | 不冻结 |
使用 Zero2 微调可能出现 Loss 为 0 的情况,建议使用 Zero3 进行微调。
✅ 相较于上一代 CogVLM2 和 GLM-4V 的主要改进
| 改进方向 | 内容说明 |
|---|---|
| 首个推理型 VLM 模型 | 不局限于数学领域,在多个子领域均达到国际领先水平。 |
| 长上下文支持 | 支持长达 64K token 的上下文长度。 |
| 图像分辨率与比例支持 | 支持任意长宽比、最高 4K 分辨率图像输入。 |
| 双语支持 | 提供中英文双语开源版本,满足全球开发者需求。 |
主要功能
GLM-4.1V-9B-Thinking 是一个面向通用多模态理解和推理的新一代视觉语言模型,具备以下核心能力:
- 多模态理解与推理:可处理图像、视频、文本等多种模态信息,完成复杂推理任务。
- 科学问题解决:在数学、物理、化学等领域表现出色,能解析图表与公式并生成详细解题步骤。
- 视频理解:准确描述视频内容,回答相关问题,实现动态场景理解。
- 内容识别:对图像和视频进行精准标注与描述,适用于内容审核、自动摘要等任务。
- 代码生成能力:如根据 UI 设计图生成 React 组件代码,提升开发效率。
- GUI 代理交互:能够模拟用户行为,与图形界面进行交互并执行指定操作。
- 长文档理解:处理多页 PDF 或扫描文档,提取关键信息并进行逻辑推理。
主要特点
- 大规模预训练:通过海量多模态数据集(图像-文本对、学术论文、图表、视频等)进行基础训练,构建强大语义理解能力。
- 强化学习驱动:采用课程采样(Curriculum Sampling, CS)与动态采样扩展(Dynamic Sampling Expansion, DSE),逐步提升模型推理能力。
- 多模态数据兼容性:支持图像、视频、长文本等多样化输入形式。
- 跨领域泛化能力:在科学、图表分析、文档理解、GUI 操作等多个领域均表现出良好的迁移能力。
- 高效推理机制:通过模型压缩与推理优化,在保持高性能的同时降低资源消耗。
工作原理详解
阶段一:大规模预训练
- 使用包含图像-文本对、学术文献、图表和视频在内的多模态数据集进行预训练;
- 通过混合训练策略提升模型对不同模态的理解能力。
阶段二:监督微调(SFT)
- 引入长链推理数据,训练模型生成多步推理过程;
- 对输出格式进行规范化设计,为后续强化学习打下基础。
阶段三:强化学习(RL)
- 课程采样(Curriculum Sampling):根据模型当前能力动态调整训练样本难度,提升训练效率;
- 动态采样扩展(DSE):通过调节样本分布多样性,增强模型鲁棒性;
- 多领域强化训练:在多个垂直领域(如数学、编程、文档分析)进行强化学习,全面提升泛化能力。
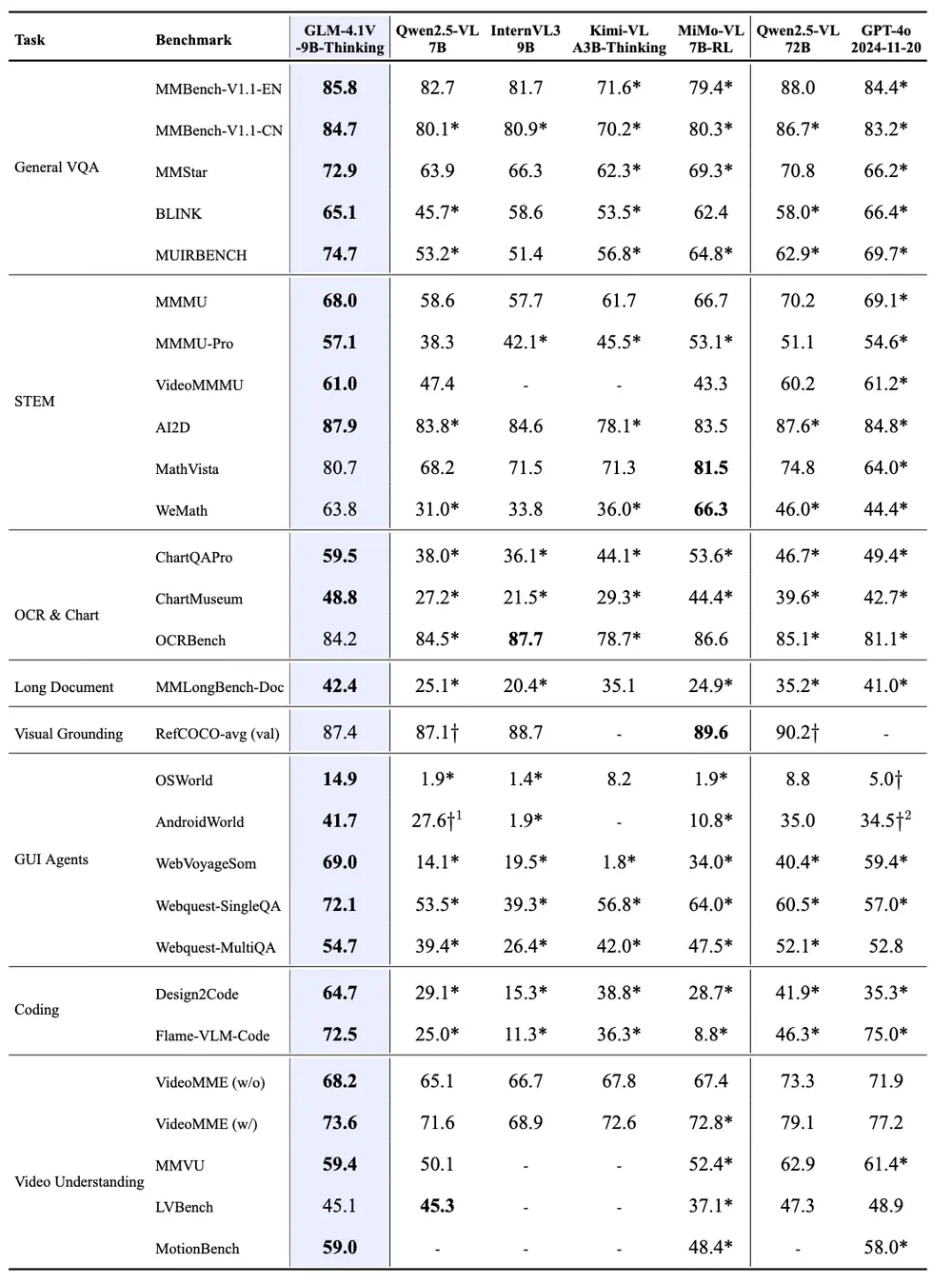
性能评估结果
GLM-4.1V-9B-Thinking 引入了「思维链(Chain-of-Thought)」机制,显著提升了回答的准确性、内容丰富度和可解释性。在总计 28 项评测任务中:
- 23 项任务达到 10B 级别模型最佳性能;
- 18 项任务超越 Qwen-2.5-VL-72B(参数量是其 8 倍);
- 多项任务表现接近甚至超过部分闭源模型(如 GPT-4o)。
🎯 应用示例
- 科学问题求解:面对复杂的数学或物理题目,模型能够理解图表与公式,生成分步推理过程并给出最终答案。
- 视频理解:模型可以逐帧解析视频内容,生成连贯描述,并回答诸如“视频中发生了什么”、“人物做了哪些动作”等问题。
- 长文档理解:针对多页 PDF、扫描件或表格文档,模型能提取关键信息并进行逻辑推理,例如从财报中总结财务状况、从法律文件中提取条款等。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











