
在企业招聘中,自动化处理海量简历是刚需,但简历格式千奇百怪——多栏排版、图文混排、表格嵌套,传统文本提取工具常会打乱语义顺序,导致关键信息错位。
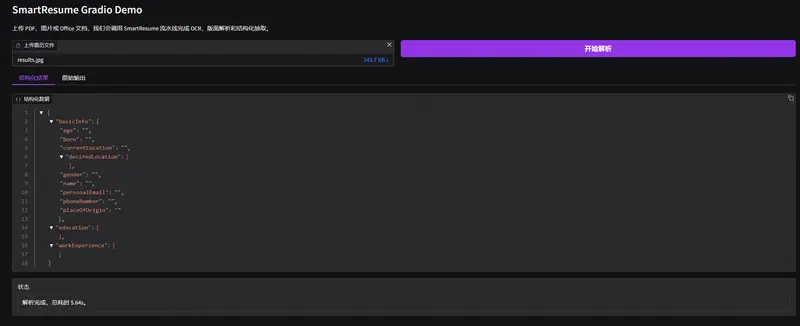
针对这一难题,阿里巴巴企业智能团队发布了 SmartResume:一个结合版面理解与大模型的智能简历解析系统。它不仅能准确还原复杂简历的阅读逻辑,还能高效提取结构化字段(如姓名、联系方式、工作经历等),并支持远程 API 调用或本地模型部署。
- GitHub:https://github.com/alibaba/SmartResume
- 模型:https://huggingface.co/Alibaba-EI/SmartResume
- Demo:https://modelscope.cn/studios/Alibaba-EI/SmartResumeDemo/summary
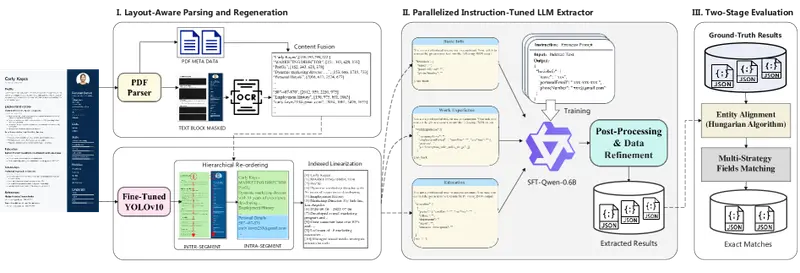
核心能力:不只是 OCR,更是“版面理解”
- 布局感知解析
系统融合 PDF 元数据与 OCR 识别结果,使用 YOLOv10 检测简历中的文本块、图像、标题等区域,再按人类阅读习惯重新排序,生成连贯的线性文本。即使面对双栏简历、侧边栏联系方式、嵌入式头像等复杂布局,也能正确重组语义顺序。 - 高效 LLM 信息提取
传统方案依赖通用大模型,成本高、延迟大。SmartResume 将任务拆解为多个并行子任务(如“提取教育经历”“识别工作公司”),并引入索引指针机制:模型不生成完整句子,而是返回原文中的起止位置索引。这种方式大幅降低计算量,同时提升内容保真度。实测显示:一个仅 0.6B 参数的微调小模型,在保持顶尖精度的同时,推理延迟仅 1.54 秒,比 Claude-4 等商业大模型快 3–4 倍。
- 自动化评估体系
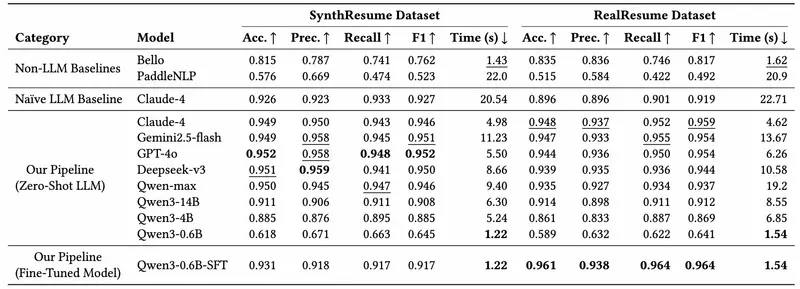
系统配套构建了 SynthResume(合成) 与 RealResume(真实) 两个数据集,并采用两阶段评估:- 使用匈牙利算法对预测项与真实项进行最优匹配;
- 对每个字段(如“公司名称”“职位”)采用多策略逻辑评分。
在复杂字段(如“工作职责描述”)上,准确率从基线的 0.136 提升至 0.846。
已落地,且开源
SmartResume 目前已集成至阿里巴巴智能 HR 平台,服务于多个业务线的实时简历处理场景,支持高吞吐、低延迟的在线服务。
团队表示,完整系统代码与评估数据集将开源,旨在推动简历解析领域的标准化研究与工业应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











