
美团 LongCat 团队近日开源了 LongCat-Flash-Omni —— 一款参数总量达 5600 亿、每 token 动态激活 270 亿参数 的 全模态大模型(Full-Modal LLM)。该模型在保持高容量的同时,实现了实时音视频交互能力,并在多个权威基准测试中接近甚至超越商业闭源模型,成为当前开源生态中少有的高性能、低延迟全模态解决方案。
- GitHub:https://github.com/meituan-longcat/LongCat-Flash-Omni
- 模型:https://huggingface.co/meituan-longcat/LongCat-Flash-Omni
关键亮点总结
- 560B MoE 全模态模型,每 token 仅激活 27B,兼顾容量与推理效率;
- 统一视觉-视频编码器 + 流式音频路径,实现低延迟实时交互;
- 128K 上下文支持长文档与复杂对话场景;
- 模态解耦并行架构,多模态 SFT 吞吐达纯文本训练的 90%+;
- 完全开源,为社区提供高性能全模态研究与部署基线。
核心目标:一个模型,四种感知
LongCat-Flash-Omni 旨在构建一个统一感知-理解-生成系统,能够同时:
- 听(实时语音输入)
- 看(图像与视频理解)
- 读(长文本/文档解析)
- 说(语音/文本同步输出)
关键突破在于:不通过多个独立模型拼接,而是在单一架构内实现跨模态无缝融合。
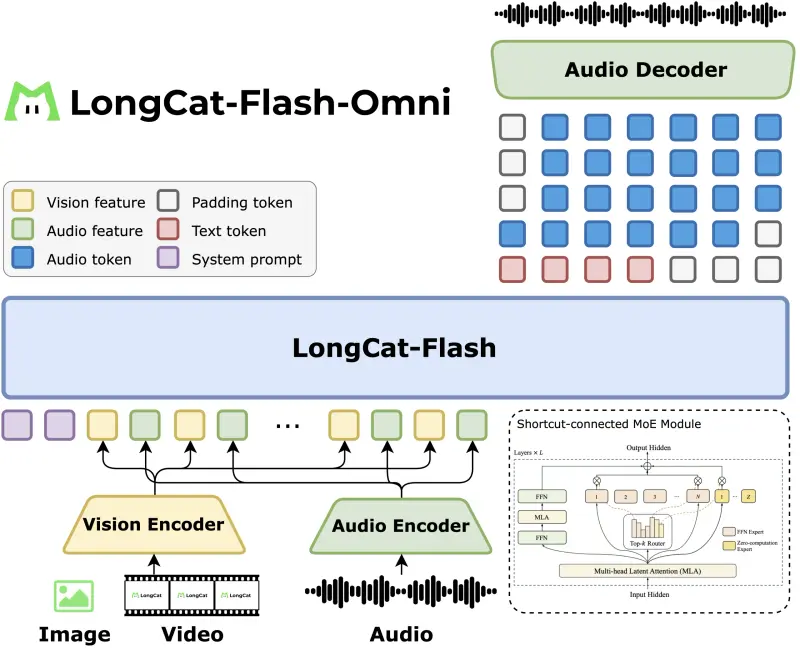
架构设计:模态感知 + 语言主干
模型采用“感知模块 + 固定语言主干”的扩展策略:
- 语言主干:复用 LongCat Flash 的 MoE 架构(560B 参数,27B 激活),支持 128K 上下文,适用于长对话与文档级理解;
- 视觉模块:LongCat ViT 编码器统一处理图像与视频帧,无需单独视频塔,降低架构复杂度;
- 音频模块:基于 LongCat Audio Codec,将语音编码为离散 token,LLM 可直接输出语音 token,实现端到端语音交互。
这种设计确保语言模型逻辑不变,仅通过“模态桥接”(ModalityBridge)融合多源信息,保障训练稳定性与推理一致性。
实时交互关键技术:流式特征交错
为实现低延迟音视频交互,团队提出 “1 秒块状特征交错” 机制:
- 视频默认 2 fps 采样,并根据总时长动态调整采样率(非固定规则);
- 音频、视频特征与时间戳被打包为 1 秒片段;
- LLM 以流式方式解码,同步生成文本或语音响应。
该策略在 GUI 操作、视频问答、实时 OCR 等任务中,既保留空间上下文,又控制延迟在可接受范围,支撑“任意模态输入 → 任意模态输出”的实时交互。
训练策略:渐进式课程学习
训练分阶段推进,确保模型稳健演进:
- 文本主干预训练(LongCat Flash)
- 文本-语音连续预训练
- 图像/视频多模态预训练
- 128K 上下文扩展
- 音频编码器对齐微调
这种课程学习路径有效避免了多模态训练初期的不稳定性,同时保留了强大的语言基础能力。
系统优化:模态解耦并行
为兼顾效率与扩展性,美团采用 模态解耦并行架构:
| 模块 | 并行策略 |
|---|---|
| 视觉/音频编码器 | 混合张量分片 + 激活重计算 |
| LLM 主干 | 管道并行 + 上下文并行 + 专家并行 |
| 模态桥接 | 嵌入对齐 + 梯度同步 |
关键成果:多模态监督微调(SFT),证明全模态训练未显著牺牲吞吐效率。
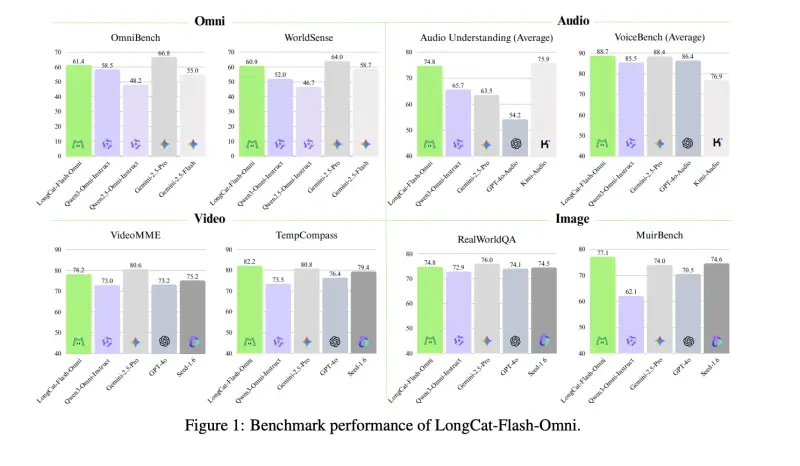
性能表现:开源中的 SOTA
| 基准 | LongCat-Flash-Omni | 对比模型 |
|---|---|---|
| OmniBench | 61.4 | Qwen 3 Omni Instruct(58.5),Gemini 2.5 Pro(66.8) |
| VideoMME | 78.2 | 接近 GPT-4o、Gemini 2.5 Flash |
| VoiceBench | 88.7 | 略超 GPT-4o Audio |
在视频与语音任务上,性能已逼近顶级闭源模型;综合多模态能力在开源领域处于领先地位。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











