
智谱AI又放出一款实用开源模型——GLM-OCR,这是一款专为复杂文档理解打造的多模态OCR模型,不仅在权威基准测试中拿下综合第一,还做到了轻量高效、易部署,关键是完全开源,个人和企业都能免费使用。
- GitHub:https://github.com/zai-org/GLM-OCR
- Hugging Face:https://huggingface.co/zai-org/GLM-OCR
- 魔塔:https://modelscope.cn/models/ZhipuAI/GLM-OCR
不同于传统OCR只做简单文字识别,GLM-OCR基于GLM-V编码器-解码器架构构建,还引入了多令牌预测(MTP)损失和稳定全任务强化学习,既能提升训练效率,又能大幅提高识别准确率和泛化能力。
它的核心组件也很能打:集成了大规模图文预训练的CogViT视觉编码器、轻量级跨模态连接器(支持高效令牌下采样),还有GLM-0.5B语言解码器,再搭配PP-DocLayout-V3的两阶段流程(先做版面分析,再并行识别),面对各种复杂文档版式,都能输出稳健高质量的识别结果。
先划重点:GLM-OCR的4大核心亮点
- 业界领先性能,综合排名第一
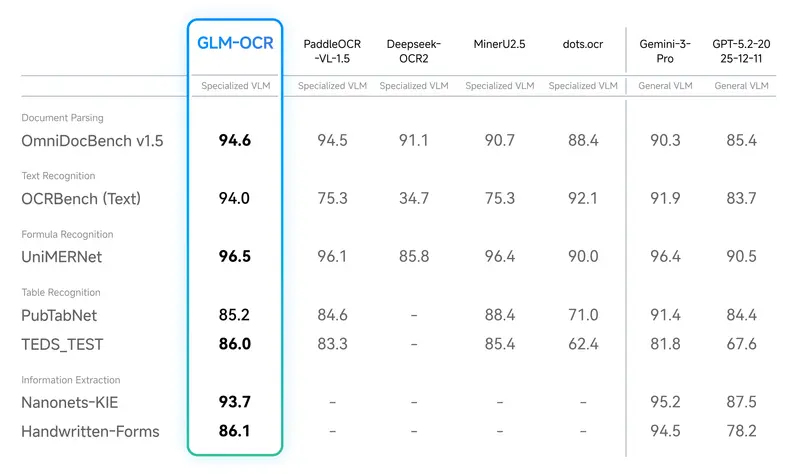
在OmniDocBench V1.5基准测试中,GLM-OCR拿下了94.62分的好成绩,综合排名第一。而且不只是普通文字识别,在公式识别、表格识别、信息抽取这些核心文档理解任务上,都达到了当前最优水平,实力在线。
- 针对真实场景优化,专治各种“疑难杂症”
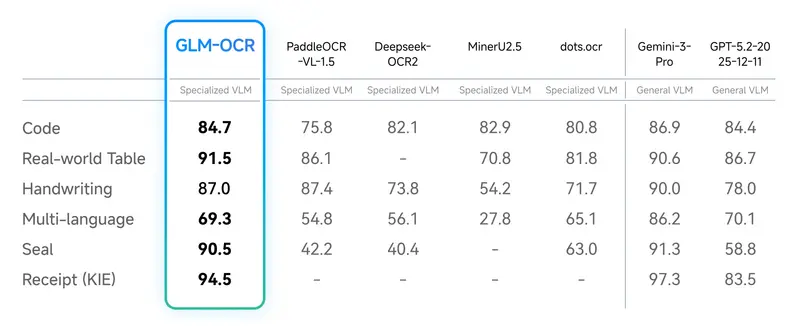
这款模型不是只在实验室数据上表现好,而是专门针对实际业务场景做了优化。面对复杂表格、满是代码的技术文档、带印章的官方文件,甚至其他排版怪异的挑战性文档,都能保持稳定的识别效果,不用再担心特殊场景下识别翻车。
- 轻量高效,部署门槛低
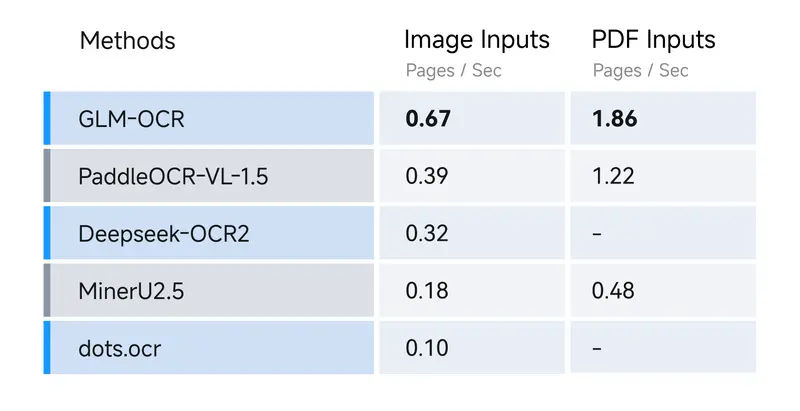
整个模型只有0.9B参数,属于轻量级模型,还支持vLLM、SGLang、Ollama多种部署方式,能显著降低推理延迟和计算成本。不管是做高并发的线上服务,还是部署在边缘设备上,都能轻松hold住,对小型团队和个人开发者非常友好。
- 完全开源,易用性拉满
GLM-OCR全程开源,还配备了完整的SDK和推理工具链,安装简单,一行命令就能调用,而且能无缝集成到现有生产流水线中,不用做大量二次开发,快速就能落地使用。
4种部署/使用方式,按需选择(附详细步骤)
GLM-OCR提供了多种使用方式,不管你是想快速试玩,还是要部署到生产环境,都能找到对应的方法,下面一步步给大家讲清楚。
方式1:vLLM(推荐,高并发场景首选)
vLLM的优势是推理速度快、支持高并发,适合搭建线上服务。
- 先安装vLLM(可选夜间版,功能更新更全):
pip install -U vllm --extra-index-url https://wheels.vllm.ai/nightly - 也可以用Docker快速部署,不用手动配置环境:
docker pull vllm/vllm-openai:nightly - 启动服务(记得安装最新版transformers):
pip install git+https://github.com/huggingface/transformers.git VLLM_USE_MODELSCOPE=true vllm serve zai-org/GLM-OCR --allowed-local-media-path / --port 8080启动成功后,就能通过8080端口调用GLM-OCR的接口了。
方式2:SGLang(灵活,支持自定义推理流程)
SGLang适合需要定制化推理逻辑的场景,同样支持Docker快速部署。
- Docker拉取镜像:
docker pull lmsysorg/sglang:dev - 也可以从源码构建安装:
pip install git+https://github.com/sgl-project/sglang.git#subdirectory=python - 启动服务:
pip install git+https://github.com/huggingface/transformers.git SGLANG_USE_MODELSCOPE=true python -m sglang.launch_server --model zai-org/GLM-OCR --port 8080
方式3:Ollama(最简单,新手快速试玩首选)
Ollama的操作门槛最低,不用敲复杂命令,适合新手快速体验GLM-OCR的效果。
- 先去Ollama官网下载并安装对应系统的客户端(支持Windows、macOS、Linux);
- 打开终端,输入以下命令直接调用模型:
ollama run glm-ocr - 识别本地图片:直接把图片拖入终端,或者手动输入图片路径即可:
ollama run glm-ocr Text Recognition: ./image.png几秒钟后就能看到识别结果,非常方便。
方式4:Transformers(灵活定制,二次开发首选)
如果想做二次开发,或者把GLM-OCR集成到自己的Python项目中,可以用Transformers直接调用模型。
- 先安装依赖:
pip install git+https://github.com/huggingface/transformers.git - 示例代码(复制就能运行,记得替换
test_image.png为你的图片路径):from modelscope import AutoProcessor, AutoModelForImageTextToText import torch # 模型路径 MODEL_PATH = "ZhipuAI/GLM-OCR" # 构建请求消息(指定图片和任务类型) messages = [ { "role": "user", "content": [ { "type": "image", "url": "test_image.png" }, { "type": "text", "text": "Text Recognition:" } ], } ] # 加载处理器和模型 processor = AutoProcessor.from_pretrained(MODEL_PATH) model = AutoModelForImageTextToText.from_pretrained( pretrained_model_name_or_path=MODEL_PATH, torch_dtype="auto", device_map="auto", ) # 预处理输入数据 inputs = processor.apply_chat_template( messages, tokenize=True, add_generation_prompt=True, return_dict=True, return_tensors="pt" ).to(model.device) inputs.pop("token_type_ids", None) # 生成识别结果 generated_ids = model.generate(**inputs, max_new_tokens=8192) output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False) # 打印结果 print(output_text)
重要提示:两种提示词场景,按需使用
GLM-OCR目前支持两种提示词场景,大家要根据自己的需求选择,尤其是信息抽取场景,有严格的格式要求。
场景1:文档解析(提取原始内容,简单易用)
主要用于提取文档中的原始文字、公式、表格,不需要复杂格式,直接使用指定关键词即可,支持的任务包括:
- 文字识别:
Text Recognition: - 公式识别:
Formula Recognition: - 表格识别:
Table Recognition:
只需在提示词中加入上述关键词,模型就会返回对应的原始内容,适合快速提取信息。
场景2:信息抽取(提取结构化信息,需遵循JSON Schema)
如果想把文档中的信息提取成结构化数据(方便后续存入数据库、做数据分析),就需要使用这种场景,而且提示词必须严格遵循JSON Schema格式。
示例:提取身份证个人信息(提示词模板)
请按下列JSON格式输出图中信息:
{
"id_number": "",
"last_name": "",
"first_name": "",
"date_of_birth": "",
"address": {
"street": "",
"city": "",
"state": "",
"zip_code": ""
},
"dates": {
"issue_date": "",
"expiration_date": ""
},
"sex": ""
}
⚠️ 注意:使用这个场景时,模型输出会严格遵循你定义的JSON Schema,这样才能保证下游系统能正常处理数据,避免格式错误。
额外福利:GLM-OCR SDK,提升开发效率
为了让大家更高效地使用GLM-OCR,智谱AI还提供了专门的SDK,封装了更多实用功能,比如批量处理、格式转换等。更多详情和使用方法,可以查看GLM-OCR的官方GitHub仓库,里面有完整的文档和示例代码。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











