百度飞桨团队近日开源 PaddleOCR-VL(0.9B)——一款专为复杂版式文档智能解析设计的视觉语言模型(VLM)。该模型以仅 9亿参数的轻量级架构,实现了对文本、表格、数学公式、图表及手写体的高精度端到端识别,并支持 109 种语言,同时兼顾部署所需的低延迟与内存效率。
- 项目主页:https://ernie.baidu.com/blog/zh/posts/paddleocr-vl
- 模型:https://huggingface.co/collections/PaddlePaddle/paddleocr-vl
核心目标:真实世界文档的结构化还原
传统 OCR 工具在处理以下场景时常表现不佳:
- 多栏混排版式(如学术论文、财报)
- 小语种文字(如泰语、阿拉伯语、藏文)
- 数学公式与手写批注共存
- 图表与表格嵌套
PaddleOCR-VL 旨在将这些复杂文档直接转换为结构化 Markdown 或 JSON,保留原始逻辑与语义,满足企业级文档自动化、知识抽取、档案数字化等需求。

系统架构:两阶段流水线,兼顾精度与效率
为避免端到端 VLM 在长序列解码中的延迟激增与输出不稳定,团队采用解耦式两阶段设计:
第一阶段:PP-DocLayoutV2(版面分析)
- 基于 RT-DETR 检测器,精准识别页面中的文本块、表格、公式、图表、手写区等区域;
- 通过指针网络预测人类阅读顺序(Reading Order),解决多栏、图文穿插场景下的逻辑流重建问题。
第二阶段:PaddleOCR-VL-0.9B(元素识别)
- 接收布局结果,对每个区域进行细粒度内容识别;
- 输出统一聚合为 Markdown(保留结构) 与 JSON(供程序解析)。
此设计显著降低了端到端模型在密集页面上的长上下文压力,提升系统稳定性与响应速度。
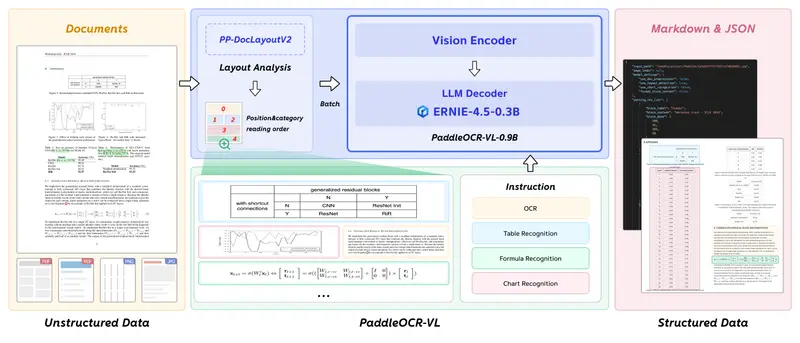
模型创新:NaViT + ERNIE-4.5 轻量协同
PaddleOCR-VL-0.9B 的核心架构融合多项前沿技术:
| 组件 | 技术 | 优势 |
|---|---|---|
| 视觉编码器 | NaViT 风格动态高分辨率编码器 | 支持原生分辨率序列打包,避免传统缩放导致的细节丢失与“幻觉” |
| 投影层 | 2层 MLP | 高效对齐视觉与语言表征 |
| 语言解码器 | ERNIE-4.5-0.3B | 轻量级但强大的中文/多语言理解能力 |
| 位置编码 | 3D-RoPE(三维旋转位置编码) | 精确建模页面中的空间-序列双重关系 |
实验表明,原生分辨率处理相比固定缩放或分块策略,在密集文本区域识别准确率提升显著,尤其对小字号、低质量扫描件效果突出。
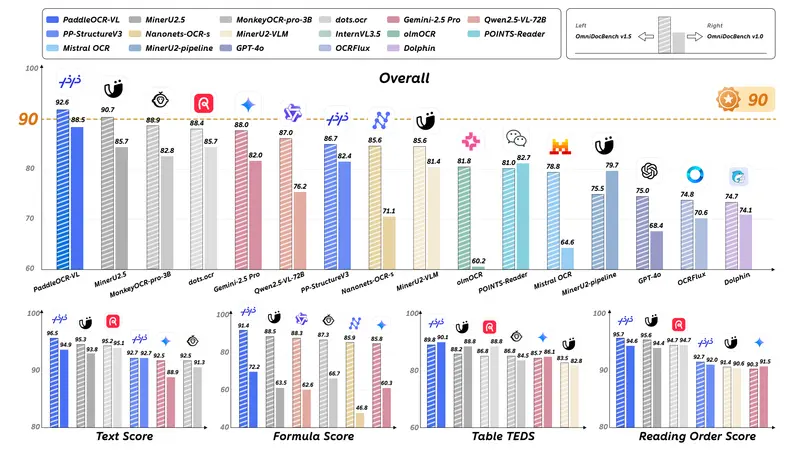
性能表现:SOTA 精度 + 部署友好
在权威基准 OmniDocBench v1.5 上,PaddleOCR-VL 表现如下:
- 文本识别:编辑距离(Edit Distance)达当前最优;
- 公式识别:Formula-CDM 指标领先;
- 表格解析:TEDS 与 TEDS-S(结构相似度)保持 SOTA;
- 阅读顺序:顺序预测准确率显著优于端到端方案;
- 手写/图表:在内部评测中展现强泛化能力。
同时,模型支持 vLLM / SGLang 等推理加速框架,可在消费级 GPU 上实现秒级文档解析,满足生产环境需求。
核心亮点总结
- 9亿参数轻量模型:精度与效率平衡,适合边缘/云端部署;
- 端到端结构化输出:直接生成 Markdown/JSON,无需后处理;
- 109 种语言支持:覆盖主流及小语种,适配全球化场景;
- 复杂元素全覆盖:文本、表格、公式、图表、手写体一体化识别;
- 开源可商用:基于飞桨生态,提供完整训练与推理工具链。
技术意义:文档智能的实用化突破
PaddleOCR-VL 的发布标志着文档 AI 从“能识别”迈向“可部署、可信任、可集成”:
- NaViT 动态分辨率解决了视觉细节丢失问题;
- 两阶段流水线平衡了端到端理想与工程现实;
- ERNIE 轻量解码器确保多语言语义准确性;
- 结构化输出+推理优化打通了从模型到产品的最后一公里。
对于金融、法律、教育、政务等高度依赖非结构化文档的行业,PaddleOCR-VL 提供了一个开箱即用、高精度、低成本的智能文档解析解决方案。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











