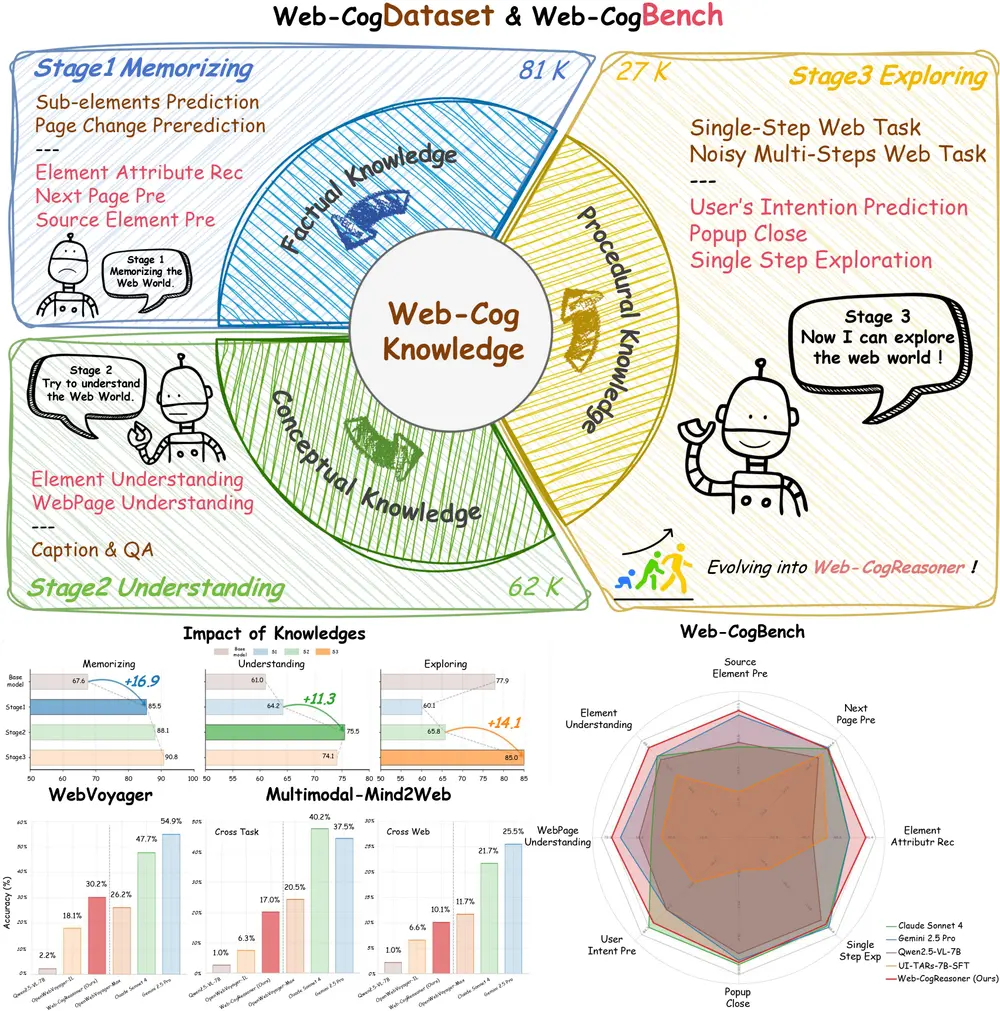
当前主流多模态基础模型在文本、图像理解、推理和生成任务上已取得显著进展,但在空间智能(Spatial Intelligence)方面仍存在系统性短板。具体表现为:
- 对物体尺度、距离、比例的估计不准确
- 难以理解三维空间结构与几何关系
- 对视角变化(如旋转、遮挡)缺乏鲁棒性
- 在复杂场景中难以整合多源空间信息
为系统性提升模型的空间理解能力,商汤科技从尺度效应(Scaling)视角出发,构建了一个大规模、多样化的空间智能训练数据集,并在通用多模态基础模型上进行持续微调,形成了 SenseNova-SI 模型系列。
- GitHub:https://github.com/OpenSenseNova/SenseNova-SI
- 模型:https://huggingface.co/collections/sensenova/sensenova-si
模型版本与兼容性
本次开源发布包括两个版本:
- SenseNova-SI-InternVL3-2B
- SenseNova-SI-InternVL3-8B
模型基于流行的开源架构 InternVL3 构建,旨在与现有研究流程保持兼容,便于社区复现、评估与二次开发。模型权重与训练细节已公开。
评估结果
SenseNova-SI 在四个近期发布、专注于空间能力的基准测试中进行了评估:
- VSI(Visual Spatial Intelligence)
- MMSI(Multimodal Spatial Inference)
- MindCube
- ViewSpatial
在同等模型规模下,SenseNova-SI 在上述基准上均达到当前开源模型的最佳性能(SOTA)。
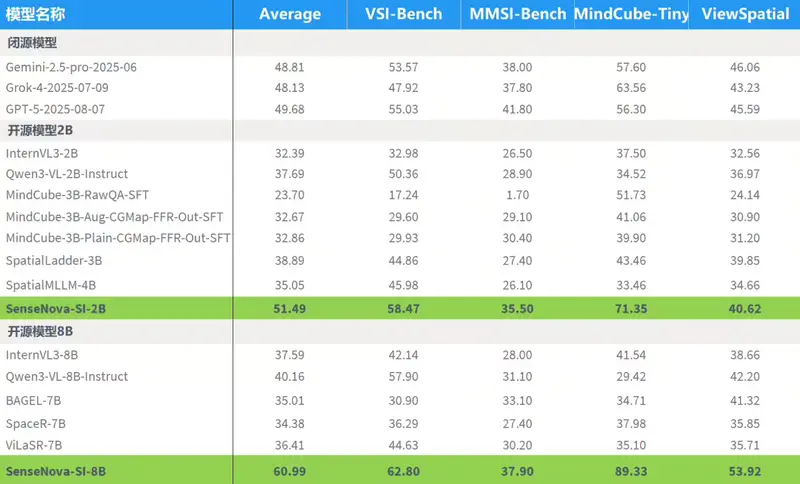
具体而言,SenseNova-SI-8B 的平均得分如下:
| 模型 | 平均得分 |
|---|---|
| SenseNova-SI-8B | 60.99 |
| Qwen3-VL-8B | 40.16 |
| BAGEL-7B | 35.01 |
| SpatialMLLM | 35.05 |
| ViLaSR-7B | 36.41 |
| GPT-5(闭源) | 49.68 |
| Gemini-2.5-Pro(闭源) | 48.81 |
注:闭源模型数据来自官方或第三方公开评测,非直接对比实验。
结果显示,SenseNova-SI-8B 在显著更小的参数量下(8B vs. 闭源模型估计的数百B),在空间任务上表现优于所列闭源系统。这表明,针对特定能力进行数据与训练策略优化,可在垂直领域超越更大通用模型。
技术意义
商汤指出,空间智能是具身智能体(Embodied Agents)与物理世界交互的基础能力。当前大模型虽在语言、知识、编程等任务上表现优异,但在需要理解“物体在哪里”“如何移动”“从哪个角度看”的任务中仍显不足。
SenseNova-SI 的探索表明:
- 空间能力可通过专用数据集+持续训练有效提升
- 尺度效应不仅存在于通用任务,在垂直能力上同样存在
- 即使中等规模模型,也能在特定领域达到领先水平
该工作为多模态模型的垂直能力优化提供了可复现路径。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











