
百度正式开源 ERNIE-4.5-VL-28B-A3B-Thinking,一款专注于文档、图表与视频理解的多模态推理模型。尽管模型总参数达 约 30B,但通过稀疏激活机制,每次推理仅激活 3B 参数,在保持大模型级能力的同时,显著降低计算与内存开销。该模型已发布在 Hugging Face,并以 Apache License 2.0 开源,支持商业使用。
- 项目主页:https://yiyan.baidu.com/blog/zh/posts/ernie-4.5-vl-28b-a3b-thinking
- GitHub:https://github.com/PaddlePaddle/ERNIE
- 模型:https://huggingface.co/baidu/ERNIE-4.5-VL-28B-A3B-Thinking
核心架构:MoE设计实现“大容量+轻部署”平衡
ERNIE-4.5-VL-28B-A3B-Thinking的核心优势源于其专家混合(MoE)架构设计,既保证了模型的推理容量,又降低了部署时的资源消耗:
1. 异构多模态MoE结构
模型基于ERNIE-4.5-VL-28B-A3B架构构建,采用“文本与视觉共享参数+模态特定专家”的异构设计。从参数规模来看,模型总参数约30B(架构归属28B-VL分支),但通过A3B路由方案,每个令牌仅激活3B参数。
这种设计让模型具备了“3B级模型的计算和内存特征”,同时保留了30B总参数的大容量推理池,实现了“轻量部署”与“高性能推理”的双赢。
2. 针对性训练优化
为提升多模态理解能力,模型经过了两阶段专项训练:
- 第一阶段:额外的“中训练”阶段,在大型视觉语言推理语料库上训练,重点提升模型的表示能力,以及视觉与语言模态之间的语义对齐——这对解析文档中的密集文本、图表中的精细结构至关重要;
- 第二阶段:多模态强化学习训练,在可验证任务上采用GSPO策略、IcePop策略以及动态难度采样技术,既稳定了MoE架构的训练过程,又推动模型聚焦困难示例,进一步提升推理精度。
关键能力:聚焦实用场景的多模态推理
百度将该模型定位为“轻量级多模态推理引擎”,官方明确其核心能力覆盖六大场景,其中“图像思考”和“工具利用”是差异化亮点:
1. 六大核心推理能力
- 视觉推理:精准理解图像中的视觉信息与语义关联;
- STEM推理:应对科学、技术、工程、数学领域的相关视觉推理任务(如电路问题分析);
- 视觉定位:支持带JSON边界框的目标定位,精准识别图像中特定区域;
- 图像思考(核心功能):模型可主动缩放感兴趣区域,对裁剪后的局部视图进行精细化推理,再将多个局部观察结果整合为最终答案,尤其适合处理细节密集的图像或图表;
- 工具利用(扩展功能):当模型内部知识不足以完成推理时,可调用外部工具(如图像搜索)补充信息,解决长尾识别问题;
- 视频理解:支持视频片段定位,能输出带时间戳的分析结果。
2. 功能部署形态
“图像思考”和“工具利用”两大核心功能,在部署时分别以“推理解析器”和“工具调用解析器”的形式暴露,方便开发者直接集成到业务系统中。
性能表现:轻量参数对标旗舰模型
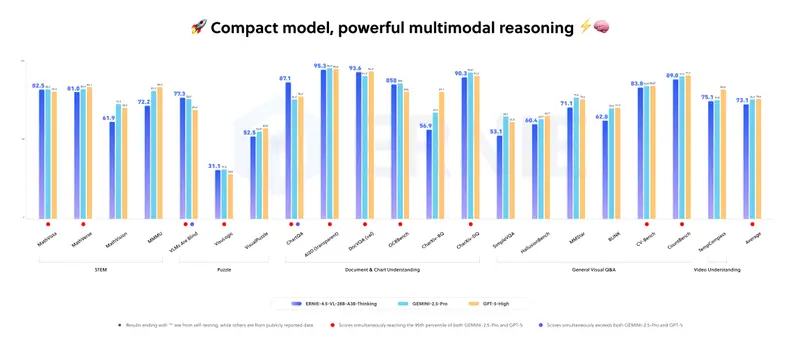
1. 与同级别模型对比优势
基础版ERNIE-4.5-VL-28B-A3B(非Thinking变体)已在多个基准测试中,实现与Qwen-2.5-VL-7B、Qwen-2.5-VL-32B相当或更优的性能,且使用的激活参数更少(仅3B)。
2. Thinking变体的性能突破
针对ERNIE-4.5-VL-28B-A3B-Thinking,百度研究人员明确表示,其在内部多模态基准测试中“紧密匹配行业旗舰模型的性能”——这意味着该模型以3B活跃参数,达到了更大型多模态模型的推理水平。
3. 双模式适配不同需求
模型支持“思考模式”和“非思考模式”切换:
- 思考模式:针对推理密集型任务,进一步提升推理精度;
- 非思考模式:保持强大的感知质量,适配对速度要求更高的场景。
部署与商用:开源友好,适配多场景落地
1. 开源协议与部署支持
模型基于Apache License 2.0协议开源,支持商业使用,部署方式灵活:
- 兼容主流框架:支持通过transformers、vLLM、FastDeploy等框架部署;
- 支持微调扩展:可通过ERNIEKit工具,采用SFT(有监督微调)、LoRA(低秩适配)、DPO(直接偏好优化)等方式进行二次微调,适配特定业务场景。
2. 关键技术参数
- 上下文长度:131,072令牌(FastDeploy示例中使用该最大模型长度);
- 支持模态:文本、视觉(图像、文档、图表、视频)。
模型参数对比表
| 模型名称 | 训练阶段 | 总参数/活跃参数 | 支持模态 | 上下文长度(令牌) |
|---|---|---|---|---|
| ERNIE-4.5-VL-28B-A3B-Base | 预训练 | 28B 总计 / 每个令牌3B活跃 | 文本、视觉 | 131,072 |
| ERNIE-4.5-VL-28B-A3B (PT) | 后训练聊天模型 | 28B 总计 / 每个令牌3B活跃 | 文本、视觉 | 131,072 |
| ERNIE-4.5-VL-28B-A3B-Thinking | 推理导向中训练 | 28B架构(HF模型30B参数) / 每个令牌3B活跃 | 文本、视觉 | 131,072 |
| Qwen2.5-VL-7B-Instruct | 后训练视觉语言模型 | ≈8B 总计(7B级) | 文本、图像、视频 | 32,768 文本位置 |
| Qwen2.5-VL-32B-Instruct | 后训练+强化调优 | 33B 总计 | 文本、图像、视频 | 32,768 文本位置 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











