在多模态大语言模型(MLLMs)的研究与应用中,视觉与文本模态的融合正在不断拓展其边界,从图像描述到视觉问答,再到复杂文档的解读,这些模型展现出了强大的能力。然而,这一领域的进一步发展面临着诸多挑战。许多顶尖的MLLMs并未公开其关键组件,如训练代码、数据整理方法和预训练数据集,导致研究者难以复现和进一步改进这些模型。此外,训练这些模型所需的高昂计算资源,更是让许多学术研究者望而却步,严重阻碍了新技术的传播和研究社区的协作。
- GitHub:https://github.com/Victorwz/Open-Qwen2VL
- 模型:https://huggingface.co/weizhiwang/Open-Qwen2VL
- 数据:https://huggingface.co/datasets/weizhiwang/Open-Qwen2VL-Data
为了打破这种局面,加州大学圣巴巴拉分校、字节跳动和英伟达的研究人员联合推出了Open-Qwen2VL。这是一款拥有20亿参数的多模态大语言模型,它不仅性能卓越,更以完全开源的姿态,为研究者提供了一条清晰的路径。

Open-Qwen2VL的开源与高效设计
Open-Qwen2VL的开发团队深知透明度和可访问性的重要性。因此,他们不仅公开了模型的训练代码库和数据过滤脚本,还提供了WebDataset格式的预训练数据,以及基础模型和指令调整后的模型检查点。这些资源的全面开放,旨在支持多模态学习领域的透明实验和方法开发,让更多的研究者能够参与到这一前沿领域的探索中。
在计算效率方面,Open-Qwen2VL同样表现出色。它基于Qwen2.5-1.5B-Instruct LLM主干,结合了SigLIP-SO-400M视觉编码器。通过一种自适应平均池化视觉投影器,该模型在预训练期间将视觉标记数量从729减少到144,显著提高了计算效率。而在监督微调(SFT)阶段,标记数量又重新增加到729,这种从低到高分辨率的策略在优化资源使用的同时,保持了强大的图像理解能力。
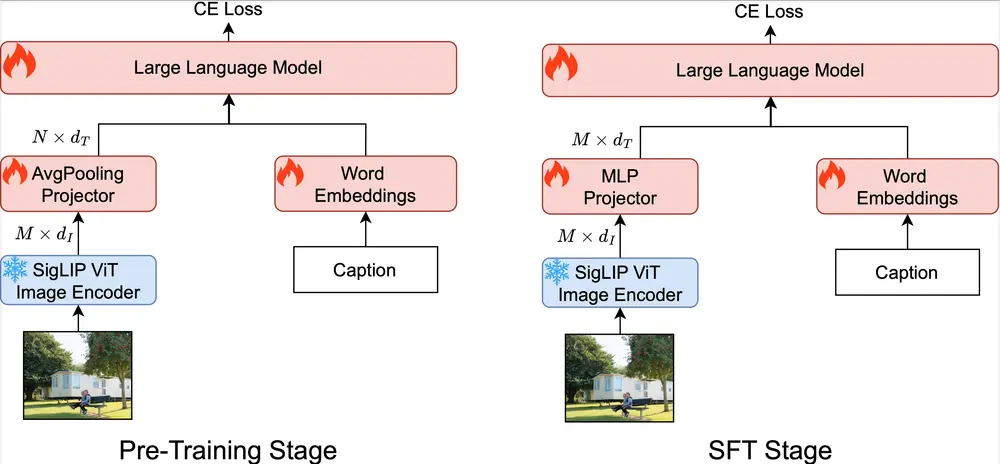
此外,Open-Qwen2VL还实现了多模态序列打包,允许将多个图像-文本对连接成约4096个标记的序列,从而减少了填充和计算开销。视觉编码器参数在预训练期间保持冻结以节省资源,并在SFT期间可选择解冻以提升下游性能。这些设计选择,使得Open-Qwen2VL在资源受限的环境中也能高效运行。
强大的性能与少样本学习能力
尽管Open-Qwen2VL仅使用了Qwen2-VL标记总量的0.36%进行训练,但在多个基准测试中,它却展现出了相当甚至更优的性能。在MMBench上,它获得了80.9分的高分,在SEEDBench(72.5)、MMStar(49.7)和MathVista(53.1)等数据集上也表现出了强大的竞争力。消融研究表明,整合一小部分(500万样本)使用基于MLM技术过滤的高质量图像-文本对,即可显著提升性能,这凸显了数据质量优于数量的重要性。
更令人印象深刻的是,Open-Qwen2VL还展示出了强大的少样本多模态上下文学习能力。在GQA和TextVQA等数据集的评估中,该模型从0样本到8样本场景的准确率提升了3%至12%。微调性能随着指令调整数据集规模的增加而可预测地提升,在使用MammoTH-VL-10M数据集约800万样本时性能增益趋于平稳。
开启多模态大模型的新篇章
Open-Qwen2VL的推出,不仅仅是一个模型的发布,更是一个可重复且资源高效的多模态大型语言模型训练管道的建立。它系统性地解决了先前模型在开放性和计算需求方面的局限性,为更多人参与MLLM研究提供了可能。该模型的设计选择,包括高效的视觉标记处理、多模态序列打包和审慎的数据选择,为学术机构在该领域做出贡献提供了一条可行路径。
Open-Qwen2VL不仅建立了一个可重复的基线,更为未来在受限计算环境下开发可扩展、高性能MLLMs奠定了坚实的基础。它的开源和高效设计,为多模态大模型的研究和应用带来了新的希望,也为推动这一领域的普惠化发展迈出了坚实的一步。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











