
随着AI技术的快速发展,视觉-语言模型(VLM)在多模态任务中的应用越来越广泛。然而,如何在保持高性能的同时降低计算成本,一直是研究者面临的挑战。近日,国内知名AI公司“月之暗面”推出了 一款高效的开源混合专家(MoE)视觉-语言模型Kimi-VL。这款模型以其紧凑的参数规模、卓越的多模态推理能力和长上下文处理能力,迅速引起了广泛关注。
- GitHub:https://github.com/MoonshotAI/Kimi-VL
- 模型:https://huggingface.co/collections/moonshotai/kimi-vl-a3b-67f67b6ac91d3b03d382dd85
什么是 Kimi-VL?
Kimi-VL 是一款开源的视觉-语言模型(VLM),专注于多模态推理、长上下文理解和强大的代理能力。它的核心特点在于采用了混合专家(MoE)架构,仅激活 28 亿参数,却在多个高难度任务中表现出色,包括大学级别的图像和视频理解、OCR(光学字符识别)、数学推理以及多图像理解。
| 模型 | 总参数 | 激活参数 | 上下文长度 | 下载地址 |
|---|---|---|---|---|
| Kimi-VL-A3B-Instruct | 16B | 3B | 128K | Hugging Face |
| Kimi-VL-A3B-Thinking | 16B | 3B | 128K | Hugging Face |
此外,月之暗面还推出了 Kimi-VL-Thinking,一个专注于长时间推理的变体模型。通过长链思维链(CoT)监督微调和强化学习(RL),这一版本进一步提升了复杂多模态推理任务的表现。
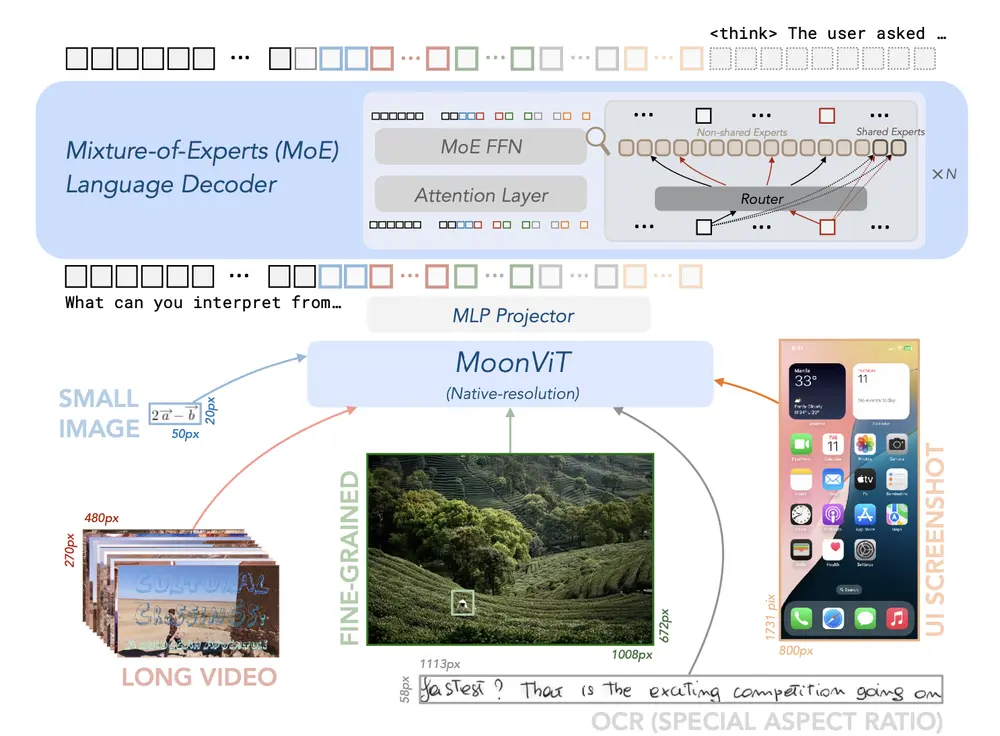
主要功能
多模态推理:Kimi-VL 能够处理多种模态的输入,包括文本、图像和视频,并在这些模态之间进行推理。 长文本理解:Kimi-VL 拥有 128K 的扩展上下文窗口,能够处理长文本和长视频,适用于长文档和长视频理解任务。 高分辨率视觉输入:Kimi-VL 的 MoonViT 视觉编码器支持原生分辨率处理,能够处理高分辨率视觉输入,如 4K 图像和视频。 强大的代理能力:Kimi-VL 在多轮代理任务中表现出色,例如在 OSWorld 基准测试中,Kimi-VL 的表现与旗舰模型相当。 长链推理:Kimi-VL-Thinking 版本通过长链推理(CoT)监督微调和强化学习(RL)进一步提升了长链推理能力,在复杂的多模态推理任务中表现出色。
主要特点
混合专家架构:Kimi-VL 采用混合专家(MoE)架构,仅激活 28 亿参数,显著提高了计算效率。 长文本处理能力:Kimi-VL 的 128K 上下文窗口使其能够处理长文本和长视频,适用于长文档和长视频理解任务。 高分辨率视觉处理:Kimi-VL 的 MoonViT 视觉编码器支持原生分辨率处理,能够处理高分辨率视觉输入,如 4K 图像和视频。 多模态数据处理:Kimi-VL 的预训练数据涵盖了多种模态,包括文本、图像、视频和 OCR 数据,确保模型在多模态任务中的表现。 强化学习支持:Kimi-VL-Thinking 版本通过强化学习进一步提升了长链推理能力,适用于复杂的多模态推理任务。
工作原理
模型架构: MoonViT 视觉编码器:支持原生分辨率处理,能够处理高分辨率视觉输入。 MLP 投影器:将视觉特征投影到语言模型的嵌入空间。 混合专家(MoE)语言模型:采用 MoE 架构,仅激活 28 亿参数,显著提高了计算效率。
预训练阶段: ViT 训练阶段:训练 MoonViT 视觉编码器,处理图像和文本对。 联合预训练阶段:同时训练视觉和语言模型,处理多种模态数据。 联合冷却阶段:进一步优化模型的多模态能力。 长文本激活阶段:扩展模型的上下文窗口,处理长文本和长视频。
后训练阶段: 联合监督微调(SFT):通过指令优化模型的对话能力。 长链推理监督微调:通过长链推理数据进一步提升模型的推理能力。 强化学习(RL):通过强化学习进一步提升模型的推理能力。
与其他模型的比较
Kimi-VL 在多个关键领域表现出色,与一些尖端高效 VLM 相比具有竞争力:
在 长上下文处理 和 高分辨率视觉理解 方面,Kimi-VL 明显优于 GPT-4o-mini 和 Qwen2.5-VL-7B。 在 数学推理 和 多模态任务 中,Kimi-VL 表现优于 GPT-4o 和 Gemma-3-12B-IT。
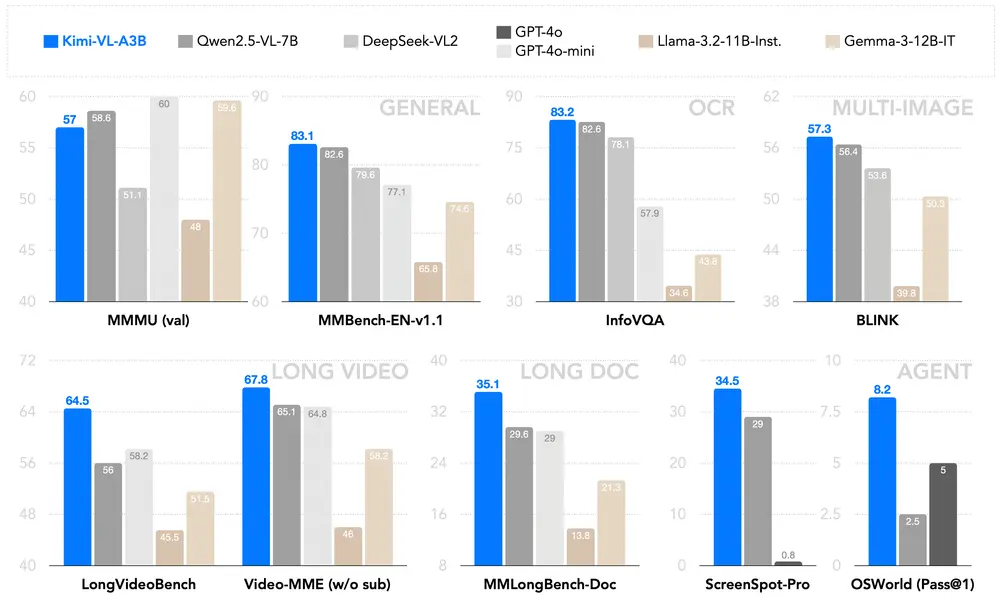
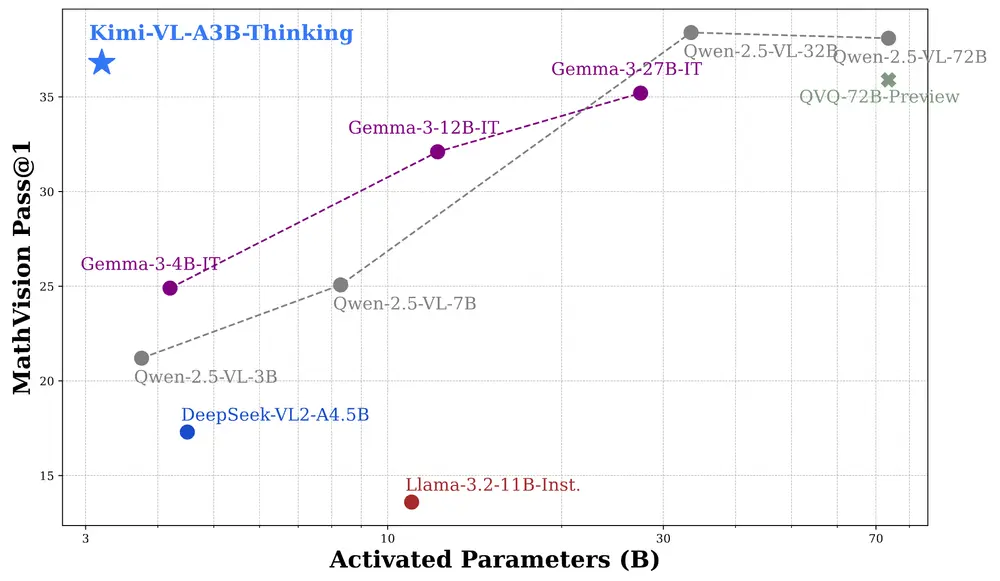
更重要的是,Kimi-VL 仅激活 28 亿参数,计算效率远高于其他模型,为高效且多模态的推理模型树立了新标杆。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











