
在 AI 视频生成领域,长期存在一个“不可能三角”:生成速度快、视频时长长、画面质量高,三者往往难以兼得。主流模型要么只能生成几秒的短视频,要么需要数十分钟才能渲染出几秒钟的画面,且长视频极易出现人物变形、场景崩坏的“漂移”现象。
- 项目主页:https://pku-yuangroup.github.io/Helios-Page
- GitHub:https://github.com/PKU-YuanGroup/Helios-Page
- 模型:https://huggingface.co/collections/BestWishYsh/helios
- Demo:https://huggingface.co/spaces/multimodalart/Helios-Distilled
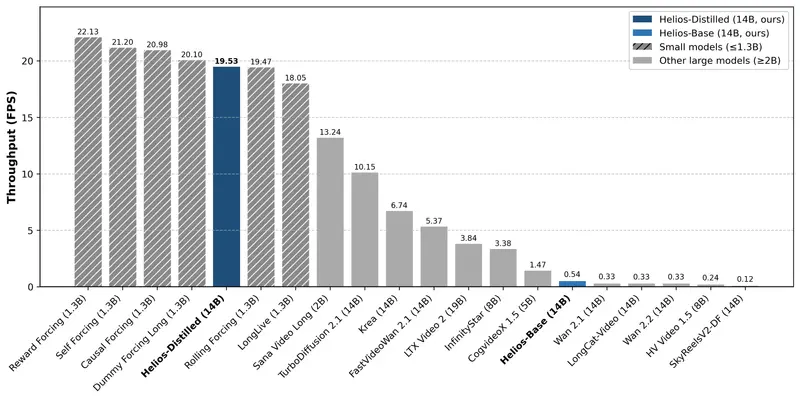
由北京大学、字节跳动 Seed 团队及 Canva 联合研发的 Helios 模型作为一款拥有 140 亿参数 的巨无霸模型,Helios 竟能在单张 NVIDIA H100 GPU 上以 19.5 FPS 的速度实时生成长达一分钟的高清视频,其速度不仅碾压同量级模型,甚至超越了众多轻量级小模型,同时保持了卓越的画质稳定性。

核心突破:重新定义“实时”与“长视频”
Helios 的成功并非偶然,它在三个关键维度上实现了前所未有的突破:
1. 真正的实时生成 (Real-Time)
- 极速推理:在单张 H100 上达到 19.5 FPS(昇腾 NPU 上约 10 FPS),意味着用户输入提示词后,视频几乎能“边说边看”地流畅播放。
- 对比震撼:同等规模的 Wan 2.1 模型速度仅为 0.33 FPS,Helios 快了 59 倍;甚至比许多专门优化过的 1.3B 小模型还要快,真正做到了“又大又快”。
2. 分钟级长视频稳如泰山
- 超长上下文:支持稳定生成 1440 帧(约 1 分钟)的连续视频。
- 零漂移奇迹:无需依赖复杂的“抗漂移”启发式策略(如关键帧重绘、错误银行等),Helios 从头到尾保持人物一致、场景连贯、色彩稳定,彻底解决了长视频“越往后越崩坏”的行业难题。
3. 极致的资源效率
- 单卡训练/推理:无需昂贵的多卡并行或参数分片框架。
- 超高密度:在 80GB 显存 的单卡上,甚至能同时容纳 4 个 14B 模型实例进行训练或推理,大幅降低了研究和部署门槛,让小团队也能玩得起顶级大模型。
技术揭秘:超级动画师的四大独门绝技
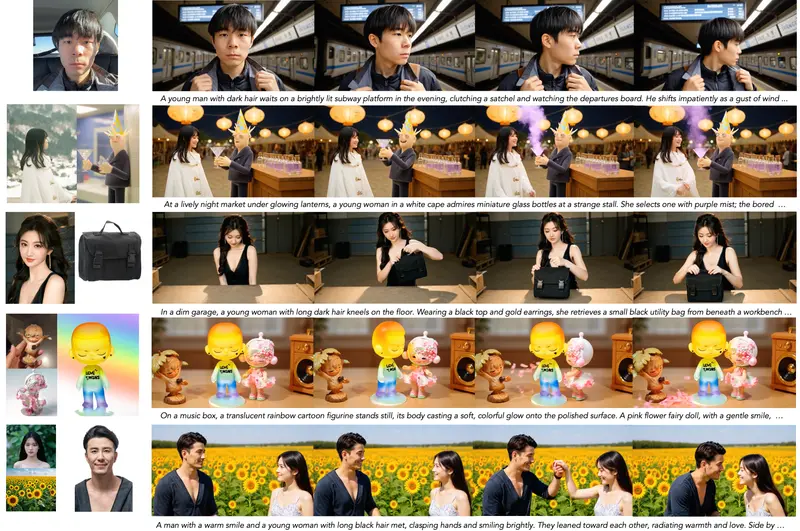
Helios 是一个统一的 14B 自回归扩散模型,原生支持文生视频 (T2V)、图生视频 (I2V) 和视频生视频 (V2V)。它是如何做到“又快又稳”的?
第一招:分层记忆压缩 (Hierarchical Memory Compression)
为了解决长视频显存爆炸的问题,Helios 模仿人类记忆机制:
- 短期记忆:清晰保留最近几帧的细节。
- 中期记忆:将稍早的帧压缩为低分辨率缩略图。
- 长期记忆:将更早的历史进一步压缩为抽象的“印象派草图”。
这种策略使得无论视频多长,显存占用几乎恒定,实现了无限时长的理论可能。
第二招:金字塔式渐进作画 (Pyramidal Progressive Generation)
摒弃传统的“一步到位”高分辨率生成,采用“先粗后细”策略:
- 先在低分辨率下快速勾勒动态轮廓。
- 逐步放大并细化细节,最后精修至高清。
早期步骤数据量极小,后期才处理全分辨率,整体计算量大幅降低。
第三招:防漂移训练法 (Drift-Resistant Training)
针对长视频三大“翻车”模式(整体偏移、颜色失真、画质退化),团队设计了巧妙的训练策略:
- 主动模拟故障:在训练中故意给历史帧加入噪声、调整曝光、模糊处理,强迫模型学会“即使参考图有点烂,我也能画好”。
- 首帧锚定:始终保留第一帧作为“定海神针”,确保风格不跑偏。
- 相对位置编码:替代绝对位置编码,彻底消除画面周期性重复的“鬼畜”现象。
第四招:对抗式知识蒸馏 (Adversarial Knowledge Distillation)
为了让模型从“需要 50 步精修”变为"3 步出图”:
- 让 Helios 向自己训练好的“老师版”学习。
- 引入对抗训练机制,像一个学生既要模仿名师,又要骗过“图灵测试”评委。
结果是在保留高质量的同时,实现了超高速采样。
实测表现:碾压基线,媲美人类
在权威的 HeliosBench 基准测试(240 个用例)中,Helios 展现了统治级实力:
| 指标 | Helios | Wan 2.1 (14B) | 其他实时模型 | 评价 |
|---|---|---|---|---|
| 生成速度 | 19.5 FPS | 0.33 FPS | < 10 FPS | 快 59 倍,唯一真·实时 |
| 长视频质量 | 6.94 / 10 | - | < 5.0 | 长视频稳定性 SOTA |
| 人类盲测胜率 | 56% - 92% | - | - | 对同类模型胜率超 66% |
| 漂移控制 | 极低 | 高 | 中/高 | 无需额外修正策略 |
消融实验验证:
- 去掉“首帧锚定” → 颜色迅速跑偏。
- 去掉“帧感知损坏”训练 → 240 帧后画质明显退化。
- 去掉“引导注意力” → 出现语义堆积(如鸟冠羽无限变大)。
每一项设计都至关重要,缺一不可。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











