
在 AI 视频编辑领域,我们常面临一个尴尬境地:文字指令难以描述精确的视觉细节(如“把那辆车换成特定的红色法拉利”),而现有的参考图引导编辑又受限于高质量训练数据的极度匮乏。
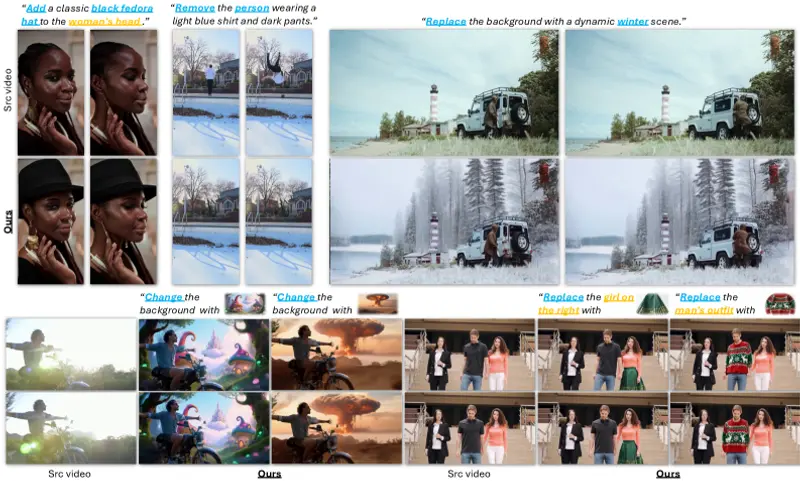
Kiwi-Edit 是由新加坡国立大学 Show Lab 团队研发,基于阿里 Qwen2.5-VL-3B 与 Wan2.2-TI2V-5B 强强联合打造,Kiwi-Edit 是一个统一、完全开源的多模态视频编辑框架。它不仅发布了强大的模型代码,更推出了目前最大的开源参考引导视频编辑数据集 RefVIE,让学术界和开发者首次拥有了媲美商业级(如 Runway Aleph)的精准视频编辑能力。
- 项目主页:https://showlab.github.io/Kiwi-Edit
- GitHub:https://github.com/showlab/Kiwi-Edit
- 模型:https://huggingface.co/collections/linyq/kiwi-edit
核心突破:解决“文字说不清”的痛点
Kiwi-Edit 的核心愿景是让 AI 既能听懂文字指令,又能看懂参考图片,实现真正的可控视频编辑。
1. 三大编辑模式自由切换
- 📝 纯文字指令编辑:支持风格迁移、背景替换、物体增删改等通用任务。
- 🖼️ 参考图引导编辑:上传一张参考图,AI 即可精准复刻其外观、纹理和风格(如“把衣服换成这件紫色连衣裙”)。
- 🔄 混合模式编辑:文字指令 + 参考图双管齐下,实现复杂需求(如“发型换成参考图的短发,同时保持原视频光影”)。
2. 时间与空间的双重一致性
- 时间连贯:编辑后的视频流畅自然,无闪烁、无变形,物体不会突然消失。
- 局部精准:能够精准定位编辑区域,只修改目标物体,完美保留背景和其他元素。
- 高清输出:支持 720p 分辨率下的高质量生成,细节丰富,色彩还原度高。
技术亮点:从“数据炼金”到“双连接器架构”
聪明的“数据炼金术”:RefVIE 数据集
面对“缺乏四元组数据(原视频 - 指令 - 参考图 - 目标视频)”的行业难题,团队没有选择昂贵的人工标注,而是设计了一套自动化数据生成管道:
- 原料:利用现有的 370 万条三元组公开数据(缺参考图)。
- 合成:利用视觉语言模型自动分析目标视频,提取编辑区域,再通过图像编辑模型生成高保真参考图。
- 提纯:经过多轮质量筛选,最终构建出包含 47.7 万 高质量样本的 RefVIE 数据集。
这是目前全球最大的开源参考引导视频编辑数据集,彻底打破了商业公司的数据壁垒。
统一的双连接器架构
Kiwi-Edit 设计了两个专门的“信息通道”,协同工作互不干扰:
- 查询连接器 (Query Connector):负责“翻译”文字指令,将自然语言转化为模型可理解的编辑意图。
- 潜在连接器 (Latent Connector):负责“提取”参考图特征,捕捉颜色、纹理、形状等细微视觉信息。
- 混合注入策略:在生成阶段,原视频结构特征直接“相加”以保持动作连贯,参考图特征“拼接”输入以提供细节指导,完美平衡了结构保留与外观迁移。
渐进式训练课程
模型采用三阶段训练策略,稳扎稳打:
- 对齐语言:先让语言模型与视频生成模型“对上话”。
- 基础编辑:学习通用的视频编辑操作。
- 参考强化:专门利用 RefVIE 数据训练参考图引导能力,提升视觉还原度。
实测表现:开源之光,媲美商业闭源
在多项权威基准测试中,Kiwi-Edit 展现了惊人的实力:
| 任务类型 | 测试集 | Kiwi-Edit 得分 | 对比对象 | 结果评价 |
|---|---|---|---|---|
| 文字指令编辑 | OpenVE-Bench | 3.02 | OpenVE-Edit (2.50) | 显著超越前最佳开源模型 |
| 背景替换 | OpenVE-Bench | 3.84 | Runway Aleph (2.62) | 碾压商业级模型 |
| 参考图引导 | RefVIE-Bench | 3.31 | Runway Aleph (3.29) | 略胜一筹,确立新 SOTA |
| 身份一致性 | RefVIE-Bench | 3.98 | - | 极高的角色/物体还原度 |
注:虽然闭源的 Kling-O1 等模型因参数量巨大仍具优势,但 Kiwi-Edit 作为开源模型,已达到了前所未有的高度。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











