想象一下:你上传一张爱因斯坦的照片和一段录音,AI 就能生成他在办公室里发表演讲的完整视频,口型完美匹配,声音惟妙惟肖;或者,你想把电影片段中的主角换成自己,连声音也一并替换,动作表情却原汁原味。
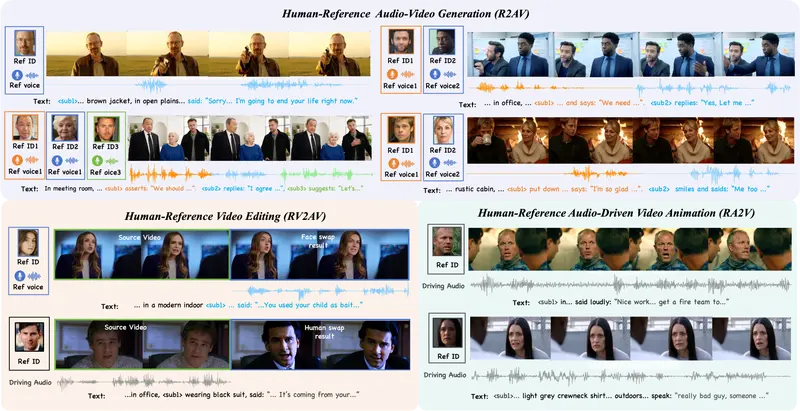
这些曾经只存在于科幻电影中的场景,如今正变为现实。来自清华大学和字节跳动的研究团队推出了 DreamID-Omni,这是一个统一的、可控的、以人为中心的音视频生成框架。它打破了以往任务割裂的局面,用一个模型完美实现了参考生成、视频编辑、音频驱动动画三大核心能力,甚至在多项指标上超越了领先的商业闭源模型。
- 项目主页:https://guoxu1233.github.io/DreamID-Omni
- GitHub:https://github.com/Guoxu1233/DreamID-Omni
核心突破:三位一体,全能虚拟制片厂
现有的 AI 视频工具往往“偏科”严重:有的只能生成新视频,有的只能换脸,有的只能让照片说话。DreamID-Omni 首次将这三者融合在一个对称条件扩散 Transformer 架构中:
1. R2AV:参考生成 (Reference-to-Audio-Video)
- 功能:给定一张人物参考图 + 一段音色参考音频 + 文本描述,生成全新的同步音视频。
- 场景:创建虚拟主播、复活历史人物、制作定制化广告。支持单人及多人互动,每个角色可独立指定身份和声音。
2. RV2AV:视频编辑 (Reference-Video-to-Audio-Video)
- 功能:给定源视频 + 新的参考人物(图 + 音),替换视频中特定角色的身份和声音,同时保留原动作、表情和口型。
- 场景:影视后期换角、个性化视频创作、隐私保护(替换路人面孔)。
3. RA2V:音频驱动动画 (Reference-Audio-to-Video)
- 功能:给定一张静态照片 + 驱动音频,让人物“活”起来,实现精准的唇形同步和自然的头部动作。
- 场景:让老照片说话、制作动态头像、虚拟助手交互。
技术揭秘:如何解决“张冠李戴”难题?
在多人场景中,AI 极易出现“脸是 A,声音是 B”或“两个人说话混淆”的问题。DreamID-Omni 提出了创新的双层解耦策略,彻底根治这一顽疾:
1. 信号层:同步旋转位置编码 (Syn-RoPE)
- 原理:在注意力机制中,为每个人物的视觉特征和听觉特征分配专属的时间轴区间和旋转子空间。
- 效果:就像给每位演员分配了独立的无线频道,既防止了不同人物间的信号串扰,又强制绑定了同一人物的脸和声。实验显示,该技术将多人场景的说话人混淆率从 0.38 降至 0.08。
2. 语义层:结构化标题 (Structured Caption)
- 原理:使用带有唯一标识符(如
<sub1>,<sub2>)的结构化文本描述剧本。 - 效果:明确告知 AI“ 穿着什么、说了什么”,在语义理解阶段就建立清晰的属性 - 主体映射,避免逻辑混乱。
3. 训练策略:多任务渐进式学习
为了避免多任务互相干扰,团队设计了三阶段渐进训练:
- 基础重建:先学“根据自身片段重建视频”,打好底子。
- 跨样本组合:再学“混合不同来源的图和声”,提升泛化能力。
- 全能微调:最后同时训练三大任务,确保各项技能均衡且强大。
实测表现:全面超越,开源在即
研究团队在自建基准测试集 IDBench-Omni 上进行了严苛评估,结果令人瞩目:
| 任务 | 指标 | DreamID-Omni | 领先商业模型 (如 Wan2.6) | 优势 |
|---|---|---|---|---|
| 参考生成 | 身份相似度 (多人) | 0.603 | 0.455 | ⬆️ 32% |
| 说话人混淆率 | 0.08 | 0.38 | ⬇️ 79% | |
| 音色相似度 | 0.402 | <0.3 | 显著领先 | |
| 视频编辑 | 身份保持度 | 0.635 | ~0.59 | 更自然 |
| 音频驱动 | 唇形同步置信度 | 6.325 | ~6.1 | 更精准 |
- 用户盲测:30 位专业创作者在 7 个维度打分,DreamID-Omni 在身份相似度、唇形同步、文本对齐度上均获最高分。
- 开源承诺:团队明确表示将开源代码,旨在弥合学术研究与商业应用之间的鸿沟,让开发者也能构建自己的“虚拟制片厂”。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...