字节跳动正式推出新一代视频创作模型 Seedance 2.0。作为迭代升级后的重磅版本,它采用全新统一的多模态音视频联合生成架构,全面支持文本、图片、音频、视频四种模态输入,集成了当前行业内覆盖面最广的多模态内容参考与编辑能力,将AI视频生成的质量、稳定性与可控性推上新高度。

对比上一版本 Seedance 1.5,Seedance 2.0 在生成效果上实现跨越式提升:复杂交互与连续运动场景的生成可用率显著提高,物理准确性、画面逼真度、创作可控性全面增强,能够更好地适配影视、广告、电商、游戏等专业领域的工业级内容生产需求。
Seedance 2.0 五大核心亮点
1. 复杂场景可用率再突破,运动与物理还原达业界SOTA
得益于大幅优化的运动稳定性与物理规则建模能力,Seedance 2.0 在多人物互动、高难度动作、连续动态变化等复杂场景中表现稳定可靠,生成内容的可用率达到业界领先水平。
无论是多人协作、竞技对抗,还是需要严格遵循物理规律的运动画面,模型都能保持结构合理、动作连贯,大幅减少传统AI视频常见的扭曲、穿模、逻辑崩坏等问题。
2. 多模态能力全面强化,支持混合素材输入参考
Seedance 2.0 基于统一多模态音视频架构训练,打破单一素材输入的限制,支持混合模态联合输入:用户可同时提交最多9张图片、3段视频、3段音频,并搭配自然语言指令进行创作。
模型能够深度理解并复用素材中的构图、运镜、动作、特效、节奏、音效等特征,让视频生成不再局限于文字描述,真正实现“用素材指挥创作”。
3. 生成可控性大幅提升,普通用户也能当导演
新版本在指令遵循度、主体一致性、画面连贯性上全面升级,能够更精准地理解并执行复杂创作意图。同时,模型新增稳定的视频延长与视频编辑能力:
- 支持对指定片段、角色、动作、剧情进行定向修改
- 支持在原有视频基础上“继续拍摄”,保持风格与主体统一
- 可自主规划镜头语言,具备基础的编导逻辑
用户无需专业技能,即可像导演一样掌控分镜、节奏与叙事,实现全流程可控创作。
4. 双声道音频能力升级,同步生成高沉浸拟真音效
Seedance 2.0 重磅升级音频生成体系,支持双声道立体声输出,可同步生成背景音乐、环境音、人声、特效音等多轨音频,并与画面节奏精准对齐。
模型能够还原极其细腻的音效:磨砂质感、毛绒摩擦、轻敲亚克力、捏气泡纸等微观声音都能逼真呈现,配合严格的音画时序同步,实现高度沉浸的专业级视听体验。
5. 深度适配工业级场景,显著降低内容制作成本
面向专业内容生产,Seedance 2.0 支持最长 15秒高质量多镜头音视频生成,可直接用于商业广告、短视频、影视片段、游戏动画、电商展示等场景。
通过AI生成替代部分实拍、后期与特效制作,模型能够大幅降低制作成本、缩短生产周期,让个人创作者与企业都能快速落地高质量视听内容。
五大能力详解:从画面到音效,全方位专业升级
1. 复杂运动稳定呈现,真实还原物理规律
Seedance 2.0 在人物与物体动态建模上实现质的突破,动作更自然、时序更精准、物理逻辑更严谨。
以双人花样滑冰为例,模型可完整还原同步起跳、空中转体、平稳落冰等一系列高难度连续动作,全程遵循现实物理规则,几乎不会出现不合理形变。在特写镜头中,衣物摆动的重力感、光影的细微变化、人物与环境的自然互动,都达到接近实拍的逼真度与细节完整性。
2. 多模态全能参考,打破创作素材边界
Seedance 2.0 支持“文本+图片+视频+音频”组合输入,实现真正意义上的多模态全能参考。
用户可以上传参考视频的运镜、参考图片的构图、参考音频的节奏与曲风,再搭配文字指令统一指挥,模型便能融合所有输入信息生成统一风格的视频内容,甚至可直接根据文字分镜脚本生成成片,大幅提升创作自由度与效率。
3. 超强指令遵循与编辑能力,精准还原创作意图
新版本对复杂脚本的理解能力显著增强,即便包含大量角色互动、精细动作、镜头切换的专业描述,也能精准还原。
更重要的是,Seedance 2.0 从“单纯生成”进化为“生成+编辑一体化”:
- 支持对视频局部内容定向修改
- 支持视频延长,保持前后风格、角色一致
- 支持按需求调整运镜、节奏与叙事结构
让创作不再是“一锤子生成”,而是可迭代、可修改、可完善的完整流程。
4. 双声道立体音效,音画协同更专业
Seedance 2.0 内置双声道音频生成能力,层次更丰富、空间感更强,可根据场景智能匹配音效、旋律与氛围。
模型在中文台词、方言、戏曲、演唱等场景的指令响应更精准,音画对齐更严格,口型、动作与声音高度同步,为影视、解说、动画等专业内容提供更强的真实感与沉浸感。
5. 全场景覆盖,降低专业内容生产门槛
无论是品牌广告、产品展示、游戏CG、影视二创,还是知识解说、剧情短片,Seedance 2.0 都能提供稳定高质量的输出。
它以AI能力简化传统视频制作中拍摄、布景、动作捕捉、后期剪辑、音效制作等高成本环节,让创意落地更快、成本更低、门槛更小,真正实现普惠式专业内容生产。
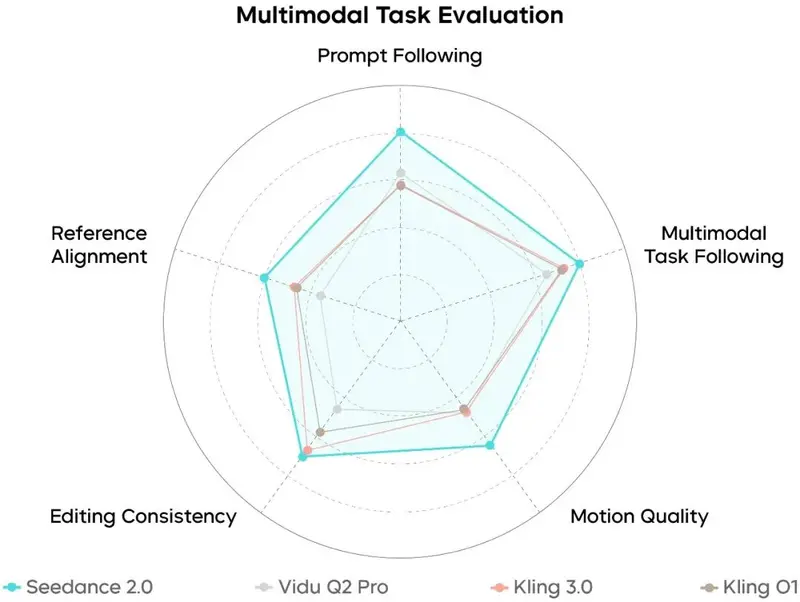
Seedance 2.0 权威评测:综合表现行业领先
为客观评估模型在真实生产场景中的能力,团队联合影视行业专家,构建了覆盖音视频生成、多模态参考、视频编辑等维度的专业评测体系,重点考察运动稳定性、指令遵循、物理合理性、视听表现力、一致性等关键指标。
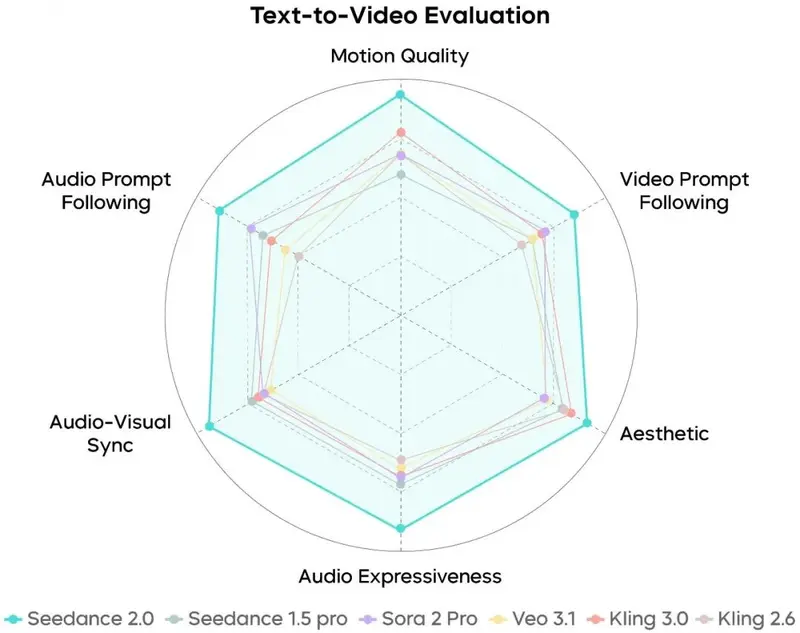
1. 文生视频 / 图生视频评测
- 画面表现:运动稳定性、指令遵循、画面美感全面提升,结构崩坏问题显著改善;大动作与微表情都能细腻呈现,支持专业运镜与节奏控制,光影、材质、服化道具备影视级完成度。
- 音频表现:双声道音质与层次感大幅增强,音效与旋律更贴合场景;音画同步更精准,中文场景适配性明显提升。
- 可优化方向:细节稳定性、动态生动性、多人口型匹配仍在持续迭代。
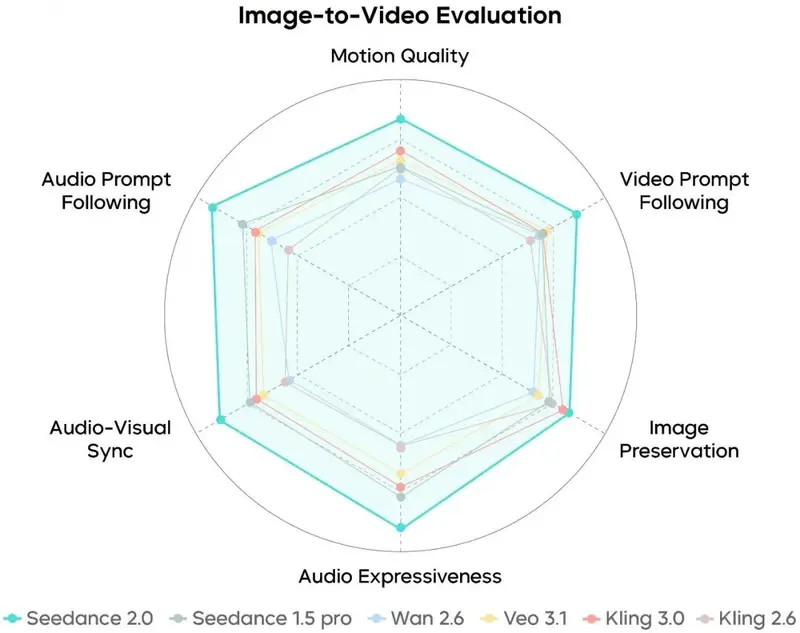
2. 多模态参考生成评测
- 综合能力:在多模态理解、编辑精度、一致性上处于行业领先水平。
- 参考与编辑:对动作、特效、剧情、风格的还原度更高,编辑指令执行更完整,画面真实感更强。
- 可优化方向:多主体长期一致性、文字还原精度、复杂编辑效果仍有提升空间。
从1.5到2.0:持续追求极致的现实世界还原
从 Seedance 1.5 的“音画一体同步生成”,到 Seedance 2.0 的“统一多模态音视频联合生成”,该系列模型一直以统一算法框架 + 高保真现实还原为核心目标。
新版本依托海量世界知识、高效稀疏架构与多模态联合训练能力,重点突破了物理规则遵循、长期一致性、复杂运动稳定等行业难题,让AI音视频生成真正具备工业级可用价值。
同时团队也表示,Seedance 2.0 仍非完美版本,部分细节与复杂场景仍有优化空间。未来,模型将持续在人类反馈对齐、生成稳定性、创作效率等方向深耕,为更多创作者提供更强大、更可靠、更具想象力的AI音视频生产工具。
立即体验 Seedance 2.0
目前,Seedance 2.0 已正式上线字节跳动旗下多款产品,用户可通过以下入口直接体验:
- 即梦网页端 → 视频生成 → 选择 Seedance 2.0
- 豆包 App → 对话框 → 进入 Seedance2.0 → 选择 2.0 模型
- 火山方舟体验中心 → 选择 Doubao → Seedance 2.0
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...