AMD 正式发布了面向 Windows 系统的技术指南,详细介绍了如何在 AMD 硬件平台上通过两条不同路径实现 OpenClaw 的本地化部署,这两条方案分别被命名为 RyzenClaw 和 RadeonClaw,均基于 AMD 自研芯片架构,将 AI 智能体完整运行在本地 PC 中,不再依赖云端服务。

这一举措也是 AMD 整体“Agent Computers”理念的重要组成部分,AMD 认为并非所有 AI 工作负载都适合在云端执行,大量个人与企业用户更希望实现数据自主掌控,同时获得无使用限制、高性价比且 24 小时不间断可用的本地 AI 能力。
- 教程地址:https://www.amd.com/en/resources/articles/run-openclaw-locally-on-amd-ryzen-ai-max-and-radeon-gpus.html

整套方案基于 WSL2 环境运行,依托 LM Studio 与 llama.cpp 完成本地大语言模型推理流程,并支持通过本地嵌入实现 Memory.md 功能,全程无需连接云端,整体配置时间可控制在一小时以内,主要面向希望尝试个人 AI 智能体的早期用户与开发者。

两套硬件方案说明
RyzenClaw
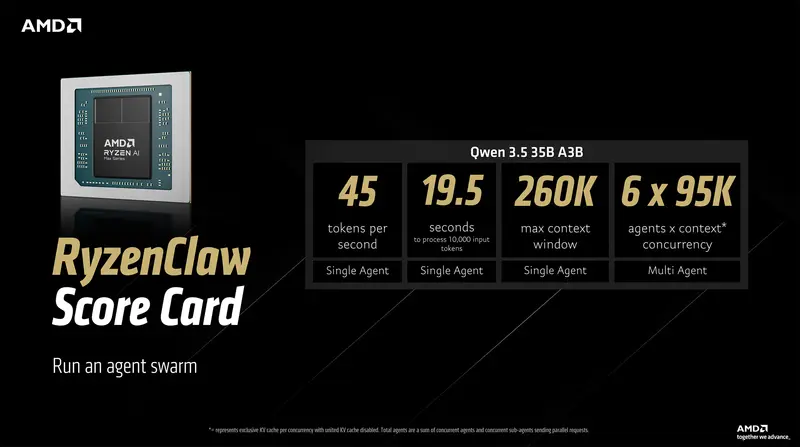
RyzenClaw 基于配备 128GB 统一内存的 Ryzen AI Max+ 系统构建,AMD 建议为该用途预留 96GB 作为可变显存。在运行 Qwen 3.5 35B A3B 模型时,该配置可实现约每秒 45 个 token 的处理速度,处理 1 万个输入 token 约需 19.5 秒,同时支持最高 26 万 token 的上下文窗口,可同时运行最多六个智能体。AMD 将其定位为可在消费级硬件上开展“智能体集群”实验的方案。整机设备基于 Ryzen AI Max+ 395 处理器与 128GB 内存,目前市售价格普遍在 10000 元以上。
RadeonClaw
RadeonClaw 采用独立显卡路线,需要搭配 Radeon AI PRO R9700 专业显卡使用,该显卡配备 32GB 显存。在运行相同模型的情况下,其处理速度可达每秒约 120 个 token,处理 1 万个输入 token 仅需约 4.4 秒,性能优势明显。但该方案的上下文窗口略小,约为 19 万 token,同时仅支持同时运行两个智能体。Radeon AI PRO R9700 单独售价为 1299 美元,按照当前汇率约合 8939 元人民币。

完整安装与配置教程(官方原版步骤)
预计完成时间:约 1 小时
1. 驱动程序更新与 AMD 可变图形内存设置
- 下载并安装最新版本的 AMD Software: Adrenalin Edition驱动程序。
- 使用 AMD Radeon 独立显卡的用户可直接跳过此步骤。使用 AMD Ryzen AI Max+ 128GB 平台的用户,在桌面任意位置右键打开 AMD Software: Adrenalin Edition,进入性能选项中的调整页面,找到可变图形内存并将其设置为 96GB,完成设置后重启计算机。

2. LM Studio 配置
初始设置
- 下载并启动 LM Studio。
- 在模型下载提示界面选择暂时跳过。
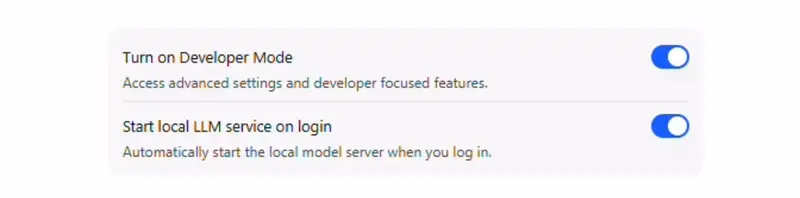
- 勾选开发者模式与登录时启动 LLM 服务。
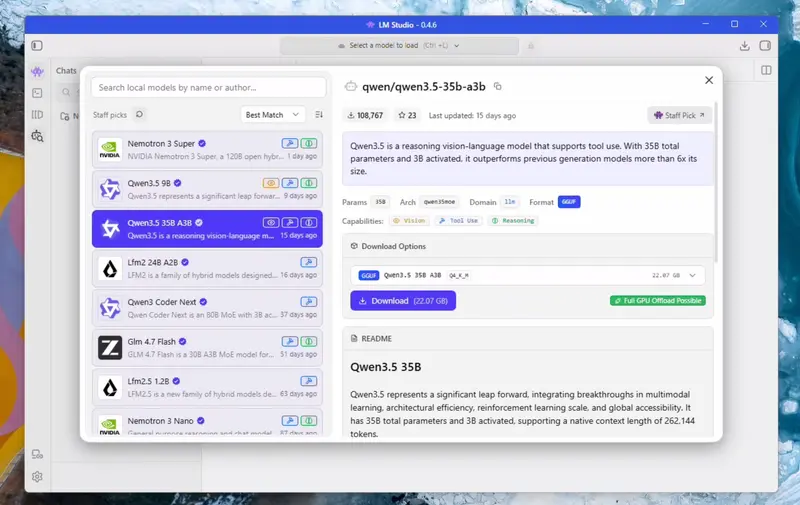
- 点击机器人与放大镜图标进入模型搜索界面。
- 在左侧列表中选择 Qwen3.5 35B A3B,在右侧点击下载并等待任务完成。
- 使用快捷键 Ctrl+L 打开模型选择界面,勾选手动选择加载模型参数,然后点击 LLM 打开加载选项。
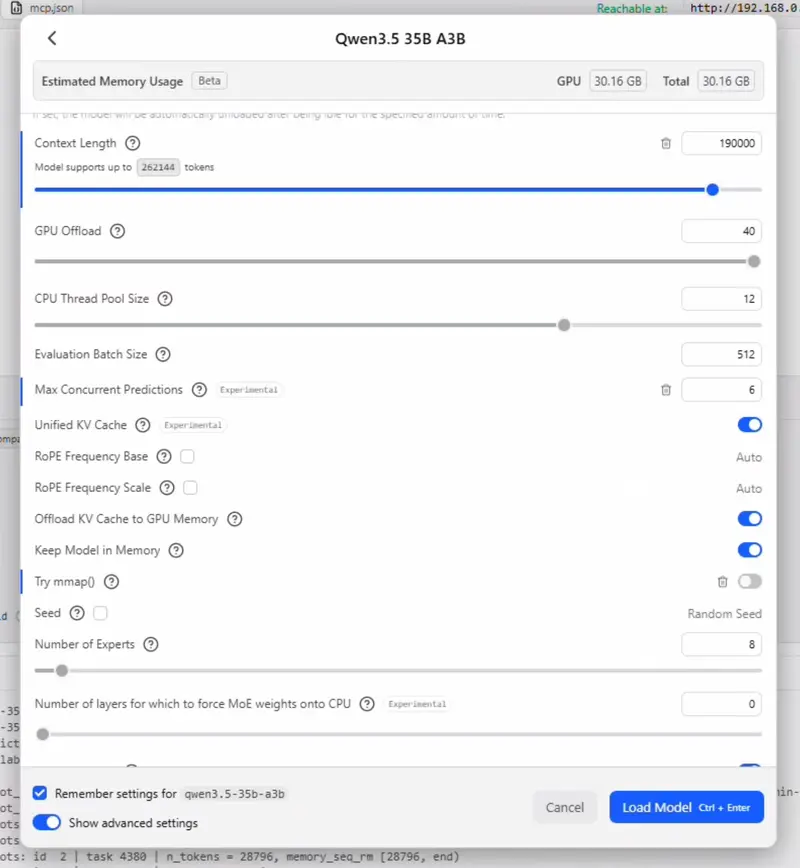
- 勾选记住设置与显示高级设置。
- 将上下文长度设置为 190000,并确保 GPU 卸载设置为 MAX。
- 取消勾选尝试 nmap。最大并发预测数值应设置为 OpenClaw 中最大并发智能体数量与最大并发智能体数量乘以最大并发子智能体数量之和。例如当配置为 2 个并发智能体与 2 个并发子智能体时,该值应设置为 6。禁用统一 KV 缓存会让每个智能体拥有独立的缓存与上下文窗口,但会显著提高内存占用;保持统一 KV 缓存开启则可让所有智能体共享同一窗口,不会额外增加内存压力。
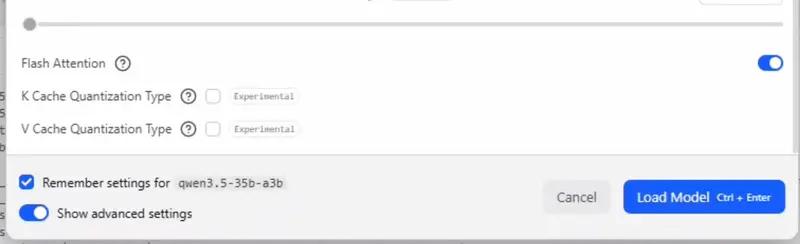
- 确保启用 Flash Attention。
- 将最大并发预测设置为 6,并保持统一 KV 缓存处于勾选状态。
- 点击加载按钮。
- 如果模型未正常显示,可尝试在下拉菜单中重新选择。
- 开启对话并发送 test 消息,确认 LLM 可以正常响应。
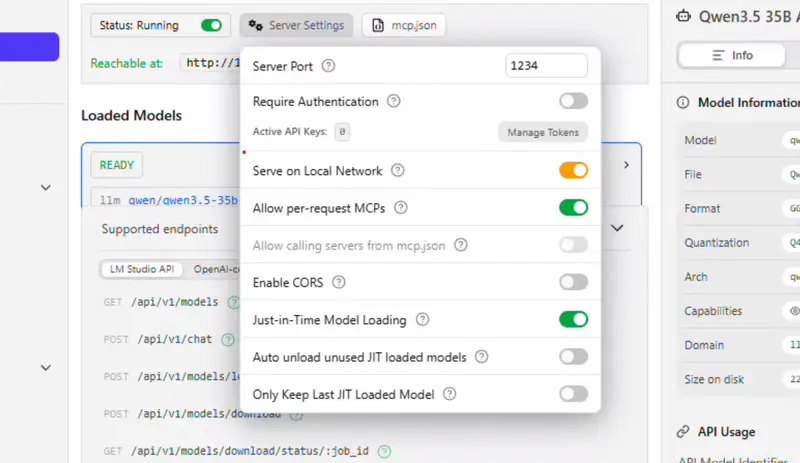
服务器设置与稳定性优化
- 使用快捷键 Ctrl+2 进入开发者选项卡。
- 点击状态前方的开关启动服务器。
- 进入服务器设置界面。
- 允许在本地网络提供服务,并在系统弹出授权提示时授予权限。
- 取消勾选自动卸载未使用的 JIT 加载模型与仅保留最后 JIT 加载的模型,点击任意空白处关闭设置窗口。
- 点击加载模型,选择 Qwen 35B A3B,此前配置的参数会自动加载,点击加载。
- 模型加载完成后状态会显示为就绪。
- 保持 LM Studio 窗口处于开启状态,继续执行后续步骤。
3. 安装 WSL2 与 OpenClaw 核心组件
- 以管理员身份打开 PowerShell 窗口。
- 执行以下命令安装 Ubuntu 24.04,首次运行会自动安装 WSL:
wsl --install -d Ubuntu-24.04
- 根据提示创建用户名与密码,执行系统更新命令,过程中可能需要输入密码并确认 Y:
sudo apt update && sudo apt upgrade
- 启用 systemd:
sudo tee /etc/wsl.conf >/dev/null <<'EOF'
[boot]
systemd=true
EOF
- 新开一个管理员权限的 PowerShell 窗口,执行:
wsl --shutdown
- 返回最初的 PowerShell 窗口,执行:
wsl.exe
- 执行以下命令验证 systemd 是否正常运行:
ps -p 1 -o comm=
若返回 systemd 则表示正常,继续配置环境变量:
mkdir -p ~/.config/systemd/user ~/.npm-global
grep -qxF 'export PATH="$HOME/.npm-global/bin:$PATH"' ~/.profile 2>/dev/null || \
echo 'export PATH="$HOME/.npm-global/bin:$PATH"' >> ~/.profile
export PATH="$HOME/.npm-global/bin:$PATH"
- 安装 Homebrew:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
- 配置 Shell 环境:
echo >> /home/claw/.bashrc
echo 'eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv bash)"' >> /home/claw/.bashrc
eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv bash)"
- 安装编译工具:
sudo apt-get install build-essential
- 安装 OpenClaw:
curl -fsSL https://openclaw.ai/install.sh | bash
4. 对接本地 LLM 配置 OpenClaw
- 阅读安全警告,使用左箭头选择是并回车,再次回车进入快速入门。
- 向下滚动找到自定义提供商并回车。
- 返回 LM Studio,在右侧 API 用法区域复制本地服务器地址,粘贴到 PowerShell 中。
- 在提示输入 API 密钥时回车,输入 lmstudio,不可留空。
- 选择兼容 Anthropic 的 API 并回车,回到 LM Studio 复制模型名称,粘贴到模型 ID 处回车。
- OpenClaw 会自动验证连接,显示验证成功后,按提示设置端点 ID 与模型别名。
- 配置通信渠道,示例中使用 Discord,需提前准备认证令牌与已邀请机器人的服务器。
- 输入 Discord 令牌,选择是配置频道访问。
- 按照格式输入服务器名称与频道名称,例如 ClawOffice/#general,回车后系统会自动解析频道 ID。
- 配置网络搜索 API,可选择跳过或注册 Brave 等服务,示例中使用 Brave API。
- 选择基础技能如 himalaya、blogwatcher、nanopdf、clawhub,提示时选择 npm 完成安装。
- 如不需要云服务,对所有 API 密钥请求选择否。
- 在钩子选项中选择 boot-md、command-logger 与 session-memory,回车完成配置。
5. 上下文、智能体数量与本地嵌入配置
- 发送以下指令更新配置:
Lets do some house-keeping: You are running locally using LM Studio and a Qwen model with 190000 context. please update the openclaw.json file with max context and 190000 max token. Also please set the max agent count to 2 and the max sub-agent count to 2 as well. When done, restart the gateway.
- 等待网关重启并显示空闲状态,在 TUI 中输入:
/new
- 发送指令配置本地嵌入模型:
Perfect! that is all done. Lets setup and validate memory.md now. Please read the docs. Specifically, we need to configure the embedding model – which by default is cloud based. We need to configure this to the local embedding model – which includes the memorysearch parameter in openclaw.json and should trigger a download of the local embeddding model. Once done – please validate its working along with the entire memory.md system.
- 网关重启后输入:
the gateway has restarted!
系统确认记忆系统正常即完成配置。
6. 可选:Chrome 浏览器自动化配置
- 新开 PowerShell 窗口进入 WSL:
wsl.exe
- 安装浏览器扩展:
openclaw browser extension install
- 更新并安装 Chrome:
sudo apt update
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
sudo apt install ./google-chrome-stable_current_amd64.deb
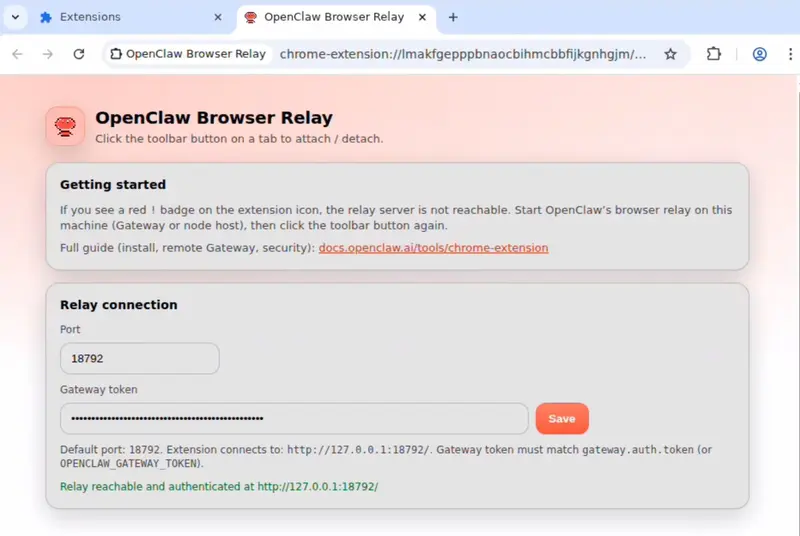
- 获取令牌并启动浏览器:
openclaw dashboard
- 在 Chrome 中开启开发者模式,加载已解压扩展,路径为:
.openclaw/browser/chrome extension
- 输入令牌并保存,确认中继状态正常。
- 点击工具栏启用 OpenClaw Browser Relay。
- 在 TUI 中发送测试指令:
I just configured you with the chrome browser relay extension. can you verify its working by navigating to amd.com
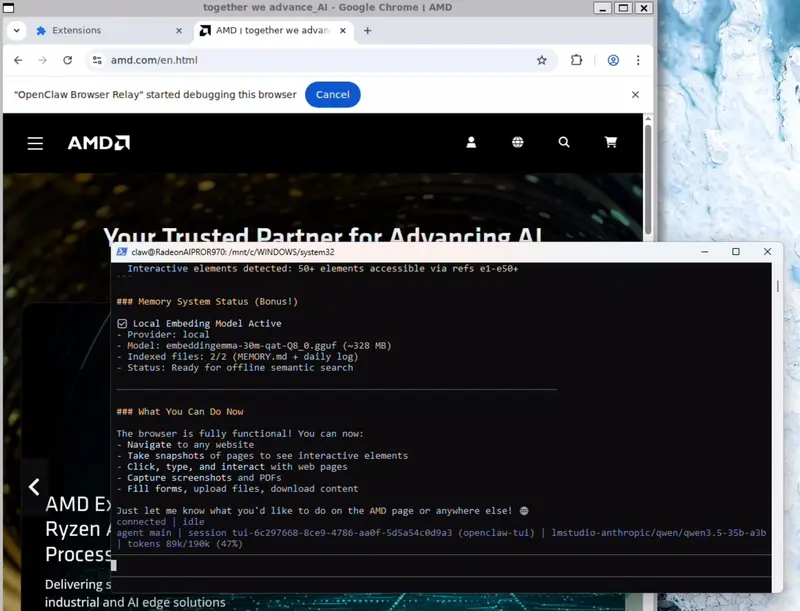
至此,OpenClaw 已完成全部本地部署,可在 Windows 环境中独立运行 AI 智能体。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...