
在最近的 Google Cloud Next '25 大会上,谷歌推出了 Ironwood,这是谷歌第七代 TPU,也是迄今为止性能最强、可扩展性最高的定制 AI 加速器。Ironwood 是首款专为推理设计的 TPU,标志着谷歌在 AI 基础设施领域的重大转变,支持大规模的思考型和推理型 AI 模型。
从响应式到主动式:推理时代的到来
Ironwood 的推出不仅代表了 AI 技术的重大进步,还标志着从 响应式 AI 模型(提供实时信息供人们解读)向 主动式 模型(提供洞察和解读的生成)的转变。谷歌将这一时代称为“推理时代”,在这个时代,AI 代理将主动检索和生成数据,以协作方式提供洞察和答案,而不仅仅是数据。
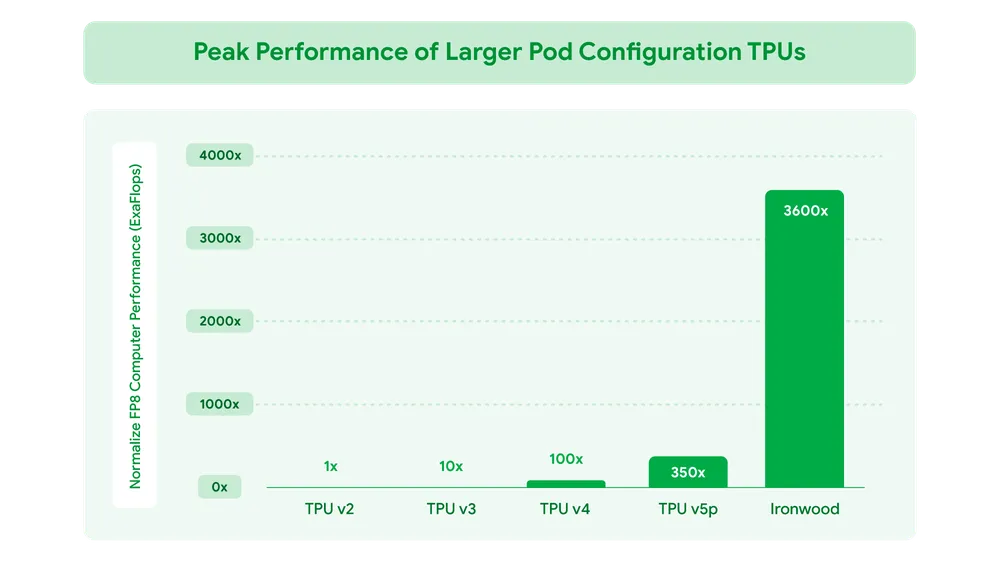
Ironwood 的强大性能
Ironwood 是谷歌最强大、最有能力且节能的 TPU,专为大规模驱动思考型、推理型 AI 模型而设计。它具有以下关键特性:
- 大规模并行处理能力:
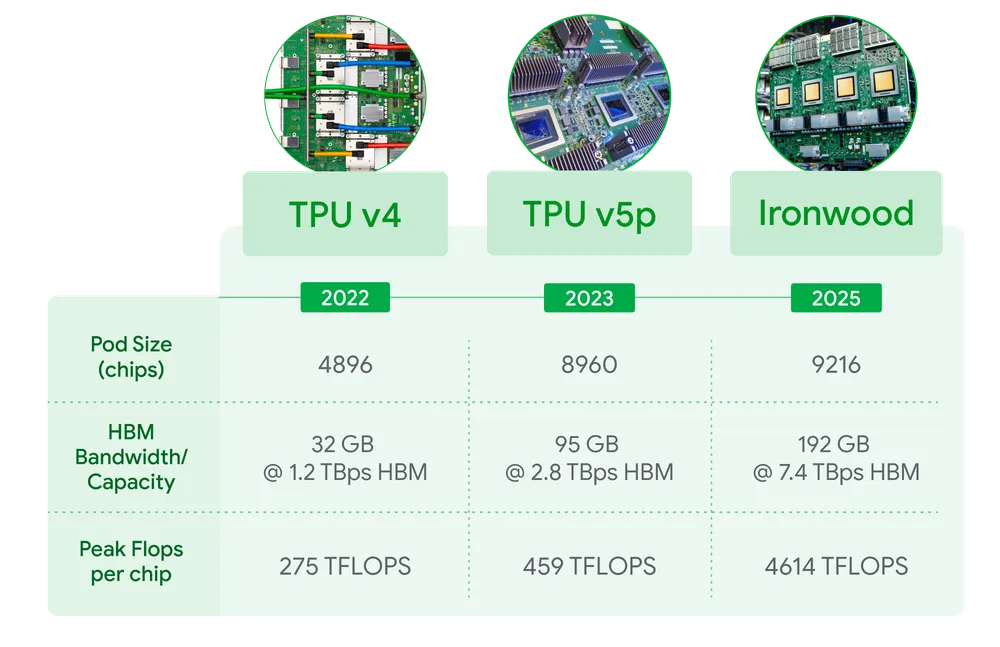
- 可扩展性:Ironwood 可扩展至 9,216 个液冷芯片,通过突破性的芯片间互连(ICI)网络连接,功率接近 10 兆瓦。
- 计算能力:当扩展至每个 pod 9,216 个芯片时,Ironwood 的计算能力总计可达 42.5 Exaflops,是全球最大超级计算机 El Capitan 的 24 倍以上。每个芯片的峰值计算能力达到 4,614 TFLOPs。
- 内存容量:每芯片提供 192 GB 的高带宽内存(HBM),是前代 Trillium 的 6 倍,显著提升了处理更大模型和数据集的能力。
- 内存带宽:HBM 带宽达到每芯片 7.2 TBps,是 Trillium 的 4.5 倍,确保快速数据访问,满足现代 AI 的内存密集型工作负载需求。
- 芯片间互连带宽:提升至 1.2 Tbps 双向,是 Trillium 的 1.5 倍,加快了芯片间通信,促进高效的分布式训练和推理。
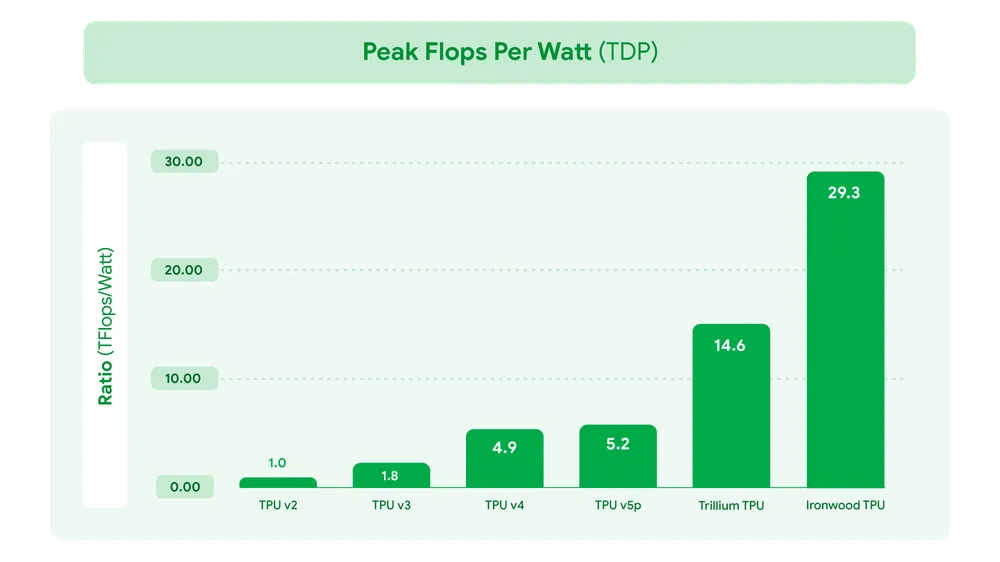
- 能效提升:
- 每瓦性能:Ironwood 的每瓦性能是第六代 TPU Trillium 的两倍,显著提高了 AI 工作负载的能效比。
- 液冷解决方案:先进的液冷技术使 Ironwood 能够在持续的重型 AI 工作负载下,可靠地维持比标准空气冷却高两倍的性能。
- 增强的 SparseCore:
- Ironwood 扩展了 SparseCore 支持,能够处理高级排名和推荐工作负载中常见的超大型嵌入,加速更广泛的工作负载,包括金融和科学领域的应用。
- Pathways 软件栈:
- 分布式计算:Google 自家的 Pathways 软件栈能够跨多个 TPU 芯片实现高效分布式计算,支持数十万 Ironwood 芯片协同工作,快速推进生成式 AI 计算的前沿。
Ironwood 的应用场景
Ironwood 专为驱动思考型和推理型 AI 模型而设计,能够优雅地管理大型语言模型(LLM)、专家混合模型(MoE)和高级推理任务的复杂计算和通信需求。这些模型需要大规模并行处理和高效的内存访问,Ironwood 的设计确保了在执行大规模张量操作时,最大限度减少芯片上的数据移动和延迟。
对于 Google Cloud 客户,Ironwood 提供两种配置:
- 256 芯片配置:适用于中等规模的 AI 工作负载。
- 9,216 芯片配置:适用于最苛刻的 AI 工作负载,如超大型密集 LLM 或 MoE 模型的训练和推理。
Ironwood 的未来展望
Ironwood 的推出不仅为谷歌的 AI 基础设施带来了显著的性能提升,还为未来的 AI 发展奠定了坚实的基础。随着生成式 AI 的快速发展,Ironwood 的强大计算能力和高效能效将帮助开发者和企业应对日益增长的计算需求。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











