
模思智能正式开源 MOVA(MOSS Video and Audio)——一款专注于原生同步生成视频与音频的基座模型。针对当前主流系统(如 Sora 2、Veo 3)普遍采用的“先画后音”级联流程,MOVA 通过单次推理实现音画同步生成,从根本上解决口型错位、环境音缺失、误差累积等长期痛点。
- 项目主页:https://mosi.cn/models/mova
- GitHub:https://github.com/OpenMOSS/MOVA
- 模型:https://huggingface.co/collections/OpenMOSS-Team/mova
为何需要 MOVA?
传统视频生成模型通常分两步:
- 生成无声视频
- 后期合成配音或音效
这种割裂流程导致:
- 音画不同步(尤其在多语种口型生成中)
- 环境音缺失(如脚步声、风声、背景音乐)
- 计算成本高(需两次独立推理)
- 闭源限制(Sora、Veo 等不开放模型与训练方法)
MOVA 的目标是提供一个完全开源、端到端、高保真的替代方案。
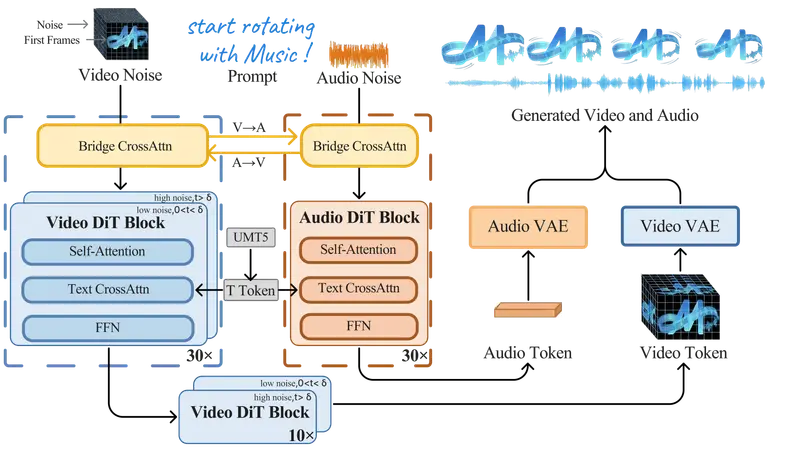
核心技术创新
✅ 原生双模态同步生成
- 在单次前向推理中同时输出视频帧与对应音频波形
- 通过双向交叉注意力机制,让视觉与听觉特征在生成过程中实时交互
- 实现帧级对齐:每一帧画面与声波精准锁相,杜绝后期合成偏差
✅ 非对称双塔 + MoE 架构
- 视频塔:基于预训练视觉主干,处理时空动态
- 音频塔:专为语音与环境音建模优化
- 混合专家(MoE):总参数量 32B,推理时仅激活 18B,兼顾质量与效率
✅ 多语言口型与环境音效
- 支持多语种精准口型同步(中文、英文、日语等)
- 自动生成环境感知音效(如雨声、键盘敲击、车辆驶过)
- 可嵌入背景配乐,提升沉浸感
开源生态:不止于模型权重
MOVA 不仅开源模型,更提供完整工具链:
- 模型权重(360p / 720p 版本)
- 推理与训练代码
- 细粒度双模态数据处理流水线
- LoRA 微调支持:允许用户以低成本定制特定风格或角色
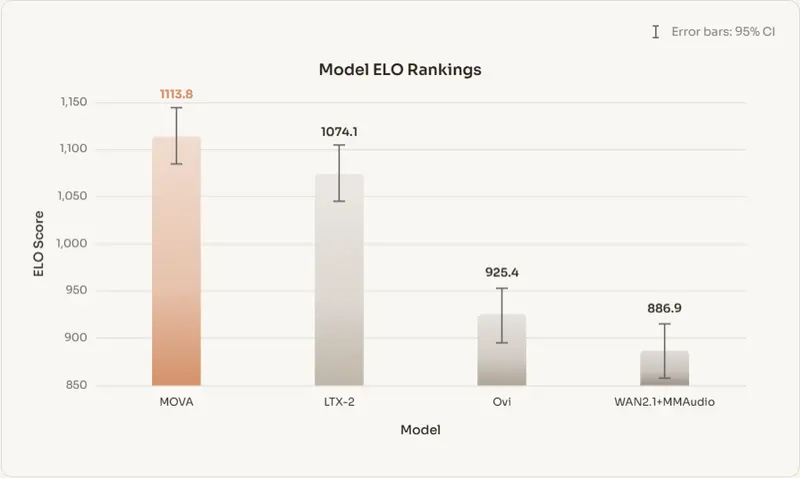
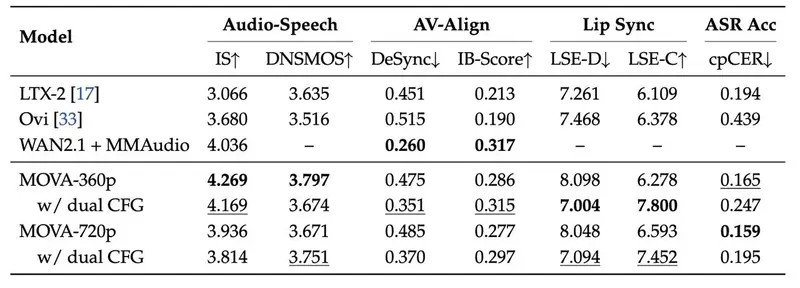
性能评估:口型同步显著领先
在 Verse-Bench 基准测试中,MOVA 表现突出:
| 指标 | MOVA-720p | 最佳竞品 |
|---|---|---|
| LSE-D(口型同步误差) | 7.094 | 8.5+ |
| LSE-C(唇形一致性) | 7.452 | 8.2+ |
| cpCER(多说话人语音识别) | 最优 | — |
注:数值越低表示同步越精准。
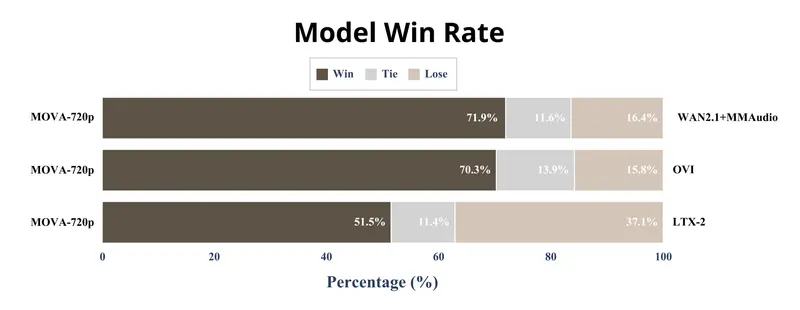
在人工评估中,MOVA 在音画一致性、语音自然度、环境沉浸感三项上均获得最高 Elo 分数与胜率。
适用场景
- 数字人直播:实时生成带精准口型的虚拟主播
- 影视创作:自动为动画/实拍片段添加环境音与配乐
- 教育内容:多语言教学视频一键生成
- 游戏/AI Agent:为虚拟角色赋予同步语音与动作
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











