
腾讯混元项目组推出基于扩散模型的条件控制方法 HunyuanPortrait ,用于高度可控且逼真的肖像动画生成。该方法通过隐式表示来控制肖像动画,能够利用单张肖像图像作为外观参考和视频片段作为驱动模板,生成具有面部表情和头部姿态的动画。官方表示,运行环境建议至少配备 16GB 显存。
- 项目主页:https://kkakkkka.github.io/HunyuanPortrait
- GitHub:https://github.com/Tencent-Hunyuan/HunyuanPortrait
- 模型:https://huggingface.co/tencent/HunyuanPortrait
简单来说这就是数字人头像生成模型,与去年快手开源的LivePortrait类似,给定一张静态的名人肖像和一段带有丰富表情的视频,HunyuanPortrait 可以生成该名人做出类似表情和头部动作的动画视频。
主要功能
- 肖像动画生成:将静态肖像转化为具有丰富表情和头部动作的动画视频。
- 高度可控性:通过隐式表示精确控制面部表情和头部姿态。
- 风格适应性:能够适应不同的图像风格,如动漫风格、真实照片风格等。
主要特点
- 高保真度:生成的动画在细节上与原始肖像高度一致,面部表情和头部动作自然流畅。
- 强泛化能力:能够处理不同风格的肖像和驱动视频,适应各种面部几何形状和表情变化。
- 时空一致性:生成的视频在时间和空间上具有高度一致性,避免了背景抖动和面部模糊等问题。
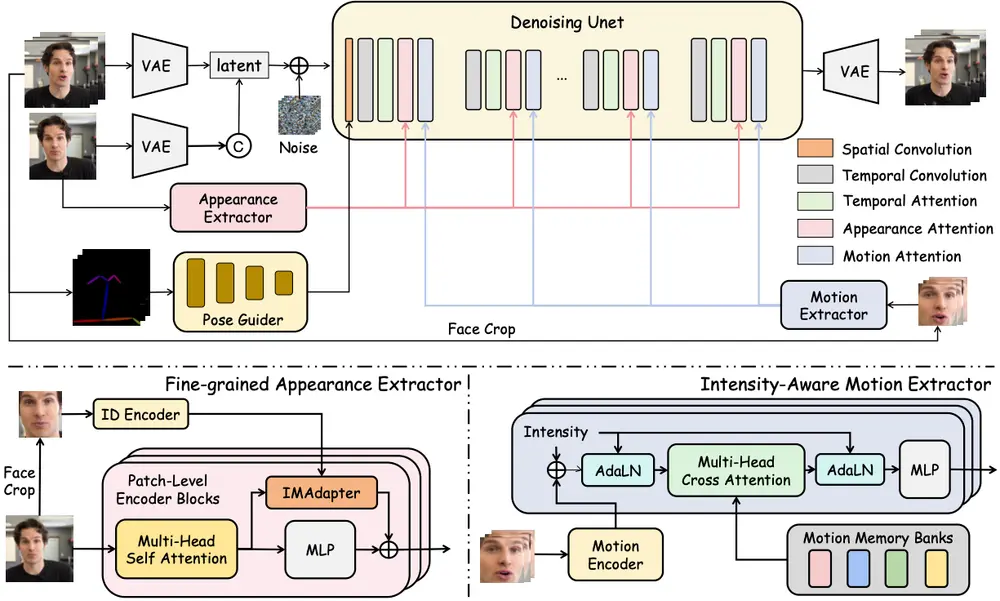
工作原理
- 预训练编码器:使用预训练的编码器将肖像的运动信息和身份信息进行解耦,提取出粗略的运动特征。
- 隐式表示:采用隐式表示来编码运动信息,并将其作为动画阶段的控制信号。
- 适配器层:设计适配器层,通过注意力机制将控制信号注入到去噪 U-Net 中,增强细节和时空一致性。
- 运动记忆库:引入运动记忆库,增强运动特征的上下文感知能力和时间建模能力。
- 强度感知运动编码器:根据运动的强度调整运动特征的表示,提高对复杂运动的捕捉能力。
- 细粒度外观提取器:结合 ArcFace 和 DiNOv2 背骨,增强对肖像身份和背景的建模能力。
测试结果
- 定量评估:在多个数据集上进行测试,HunyuanPortrait 在 Fréchet Inception Distance (FID)、Fréchet Video Distance (FVD)、Landmark Mean Distances (LMD) 等指标上均优于现有方法。
- 定性评估:通过用户研究,HunyuanPortrait 在面部运动、视频质量和时间平滑性方面均获得了较高的评分。
- 泛化能力:在跨重演(cross-reenactment)场景中表现出色,能够有效处理不同面部几何形状和表情变化。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











