
在内容创作领域,视频生成技术正不断进化,但如何让生成的视频既保持主体一致性,又能实现多样化的场景和动作变化,一直是创作者面临的难题。今天,腾讯混元团队正式推出并开源了一款全新的多模态定制化视频生成工具——Hunyuan Custom。这款工具基于混元视频生成大模型(Hunyuan Video)打造,不仅支持文本、图像、音频、视频等多模态输入,还在主体一致性效果上超越了现有的开源方案。
- 项目主页:https://hunyuancustom.github.io
- GitHub:https://github.com/Tencent/HunyuanCustom
- 模型:https://huggingface.co/tencent/HunyuanCustom
- Demo:https://hunyuan.tencent.com/modelSquare/home/play?modelId=192

Hunyuan Custom的核心能力
1. 主体一致性的突破
Hunyuan Custom 的一大亮点是其强大的主体一致性能力。无论是单主体还是多主体视频生成,模型都能精准识别用户上传的图片中的身份信息,并在生成的视频中保持高度一致。例如,用户只需上传一张人物照片并提供一句文字描述(如“他正在遛狗”),Hunyuan Custom 就能生成一段连贯自然的视频,其中人物的身份特征与原始图片完全吻合,而动作、服饰和场景则可以完全改变。
对于多主体生成,Hunyuan Custom 同样表现出色。比如,用户可以上传一张人物照片和一张物体照片(如一名男子和一包薯片),并输入文字描述(如“一名男子正在游泳池旁边,手里拿着薯片进行展示”),模型便能生成符合要求的多主体视频。

2. 多模态输入支持
Hunyuan Custom 支持多种输入形式,包括文本、图像、音频和视频,赋予创作者更灵活的控制力:
- 图像+文本:生成主体一致的动态视频。
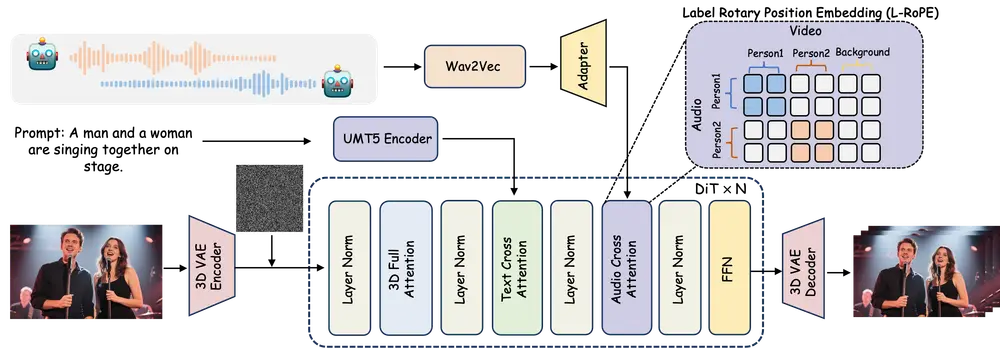
- 图像+音频:实现音视频同步的表演效果,适用于数字人直播、虚拟客服等场景。
- 图像+视频:将图片中的主体自然替换或插入到任意视频片段中,用于创意植入或场景扩展。

3. 多样化应用场景
凭借其多模态能力和高度可控性,Hunyuan Custom 可广泛应用于多个领域:
- 虚拟人广告:通过多张图片生成虚拟人动态广告。
- 虚拟试穿:根据用户上传的图片生成不同服装搭配的效果。
- 歌唱头像:结合音频输入生成唱歌或说话的虚拟头像。
- 视频编辑:通过图片和视频输入实现主体替换或场景扩展。
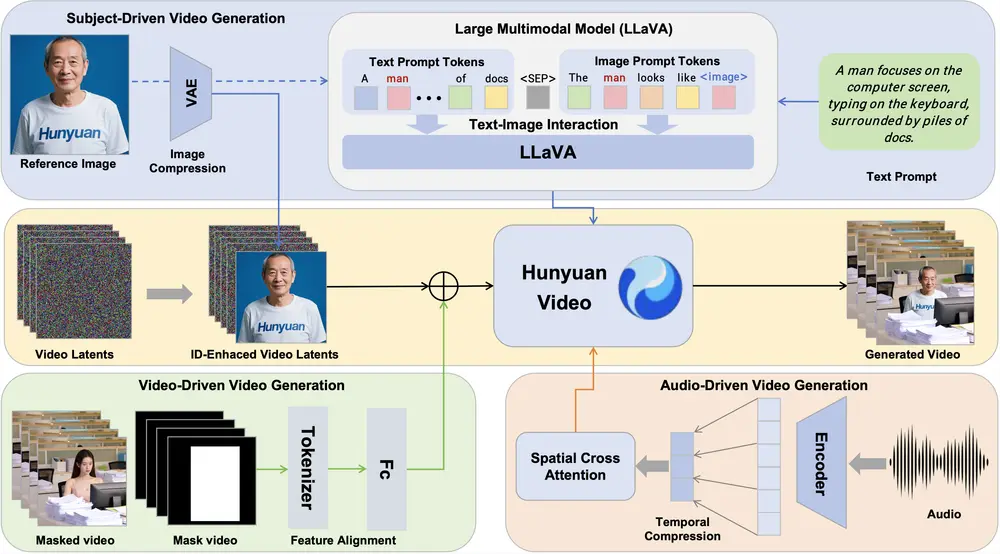
技术架构与创新点
Hunyuan Custom 基于 Hunyuan Video 框架构建,通过多项技术创新实现了其卓越的性能:
- 多模态理解增强
引入基于 LLaVA 的文本-图像融合模块,提升对图像和文本条件的理解能力,从而更好地解决图像-文本生成任务。 - 跨帧身份特征强化
提出时序拼接的图像 ID 增强模块,确保生成的视频在不同帧之间保持主体身份的一致性。 - 模态特定条件注入机制
- AudioNet 模块:通过空间交叉注意力实现层次对齐,支持音频驱动的视频生成。
- 视频驱动注入模块:通过基于 patchify 的特征对齐网络整合潜在压缩条件视频,支持视频输入的场景替换。
实验结果表明,Hunyuan Custom 在身份一致性、真实感和文本-视频对齐方面显著优于当前最先进的开源和闭源方法。
性能比较
为评估HunyuanCustom的性能,我们将其与最先进的视频定制方法(包括VACE、Skyreels、Pika、Vidu、Keling和Hailuo)进行了比较,重点关注面部/主体一致性、视频-文本对齐和整体视频质量。
| 模型 | 面部相似度 | CLIP-B-T | DINO-相似度 | 时序一致性 | DD |
|---|---|---|---|---|---|
| VACE-1.3B | 0.204 | 0.308 | 0.569 | 0.967 | 0.53 |
| Skyreels | 0.402 | 0.295 | 0.579 | 0.942 | 0.72 |
| Pika | 0.363 | 0.305 | 0.485 | 0.928 | 0.89 |
| Vidu2.0 | 0.424 | 0.300 | 0.537 | 0.961 | 0.43 |
| Keling1.6 | 0.505 | 0.285 | 0.580 | 0.914 | 0.78 |
| Hailuo | 0.526 | 0.314 | 0.433 | 0.937 | 0.94 |
| HunyuanCustom (Ours) | 0.627 | 0.306 | 0.593 | 0.958 | 0.71 |
运行要求
下表显示了运行HunyuanCustom模型(批量大小=1)生成视频的要求:
| 模型 | 设置(高度/宽度/帧数) | GPU峰值显存 |
|---|---|---|
| HunyuanCustom | 720px1280px129f | 80GB |
| HunyuanCustom | 512px896px129f | 60GB |
- 需要支持CUDA的英伟达 GPU。
- 模型在配备8个GPU的机器上测试。
- 最低要求:720px1280px129f的最小GPU内存需求为24GB,但速度非常慢。
- 推荐:我们建议使用80GB显存的GPU以获得更好的生成质量。
- 测试操作系统:Linux
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











