麻省理工学院和Adobe的研究人员推出新型自回归视频扩散模型CausVid,旨在解决传统双向扩散模型在交互式应用中的高延迟问题。通过将双向扩散模型蒸馏为快速自回归生成器,CausVid 能够实现低延迟、高效率的视频生成,同时保持高质量的输出。
- 项目主页:https://causvid.github.io
- GitHub:https://github.com/tianweiy/CausVid
- 模型:https://huggingface.co/tianweiy/CausVid
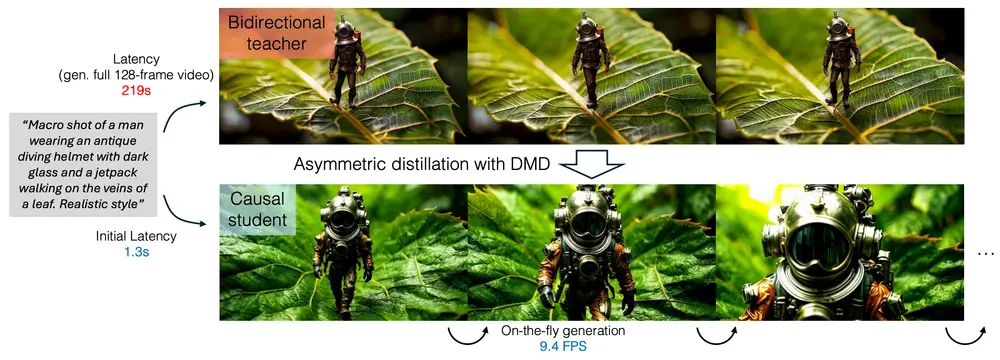
例如,你想生成一个视频,内容是一个人穿着复古潜水服在树叶的脉络上行走。传统的双向扩散模型需要处理整个视频序列,包括未来的帧,才能生成第一帧,这可能需要 219 秒才能生成一个 128 帧的视频。而 CausVid 可以在 1.3 秒内生成第一帧,并以大约 9.4 FPS 的速度连续生成后续帧,大大提高了交互性。
主要功能
- 快速视频生成:CausVid 能够在短时间内生成高质量的视频,适用于需要实时反馈的交互式应用。
- 低延迟交互:支持用户在生成过程中实时输入指令或更改条件,模型能够即时响应。
- 多样化任务支持:除了文本到视频生成,CausVid 还支持图像到视频、视频到视频翻译以及动态提示等任务。
主要特点
- 自回归架构:采用因果自回归架构,逐帧生成视频,用户可以即时观看生成的视频,而无需等待整个序列完成。
- 分布匹配蒸馏(DMD):通过将双向扩散模型的知识蒸馏到自回归学生模型中,显著减少了错误累积,提高了生成质量。
- 高效推理:利用键值(KV)缓存机制,进一步提高了推理速度,使得模型能够在单个 GPU 上以 9.4 FPS 的速度生成视频。
- 长视频生成:通过滑动窗口推理策略,CausVid 可以生成无限长的视频,而不会出现质量下降的问题。
工作原理
CausVid 的工作原理基于以下关键步骤:
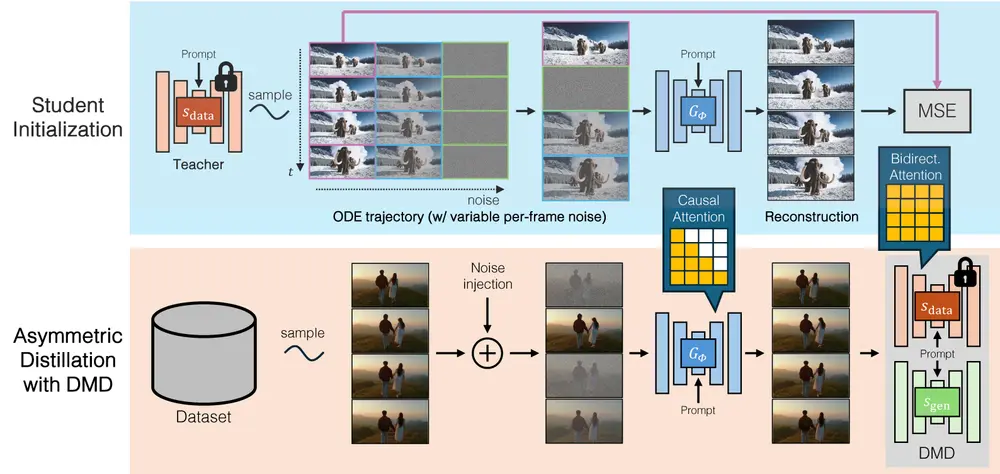
- 双向到自回归的转换:将预训练的双向扩散模型(如 Diffusion Transformer)转换为自回归架构,通过因果注意力机制逐帧生成视频。
- 分布匹配蒸馏(DMD):通过 DMD 技术,将 50 步的双向扩散模型蒸馏为 4 步的自回归生成器。这种方法通过最小化双向教师模型和自回归学生模型之间的分布差异来训练学生模型。
- 学生初始化:通过 ODE 轨迹初始化学生模型,确保训练的稳定性和收敛性。
- KV 缓存机制:在推理阶段,利用 KV 缓存机制减少计算开销,提高生成速度。
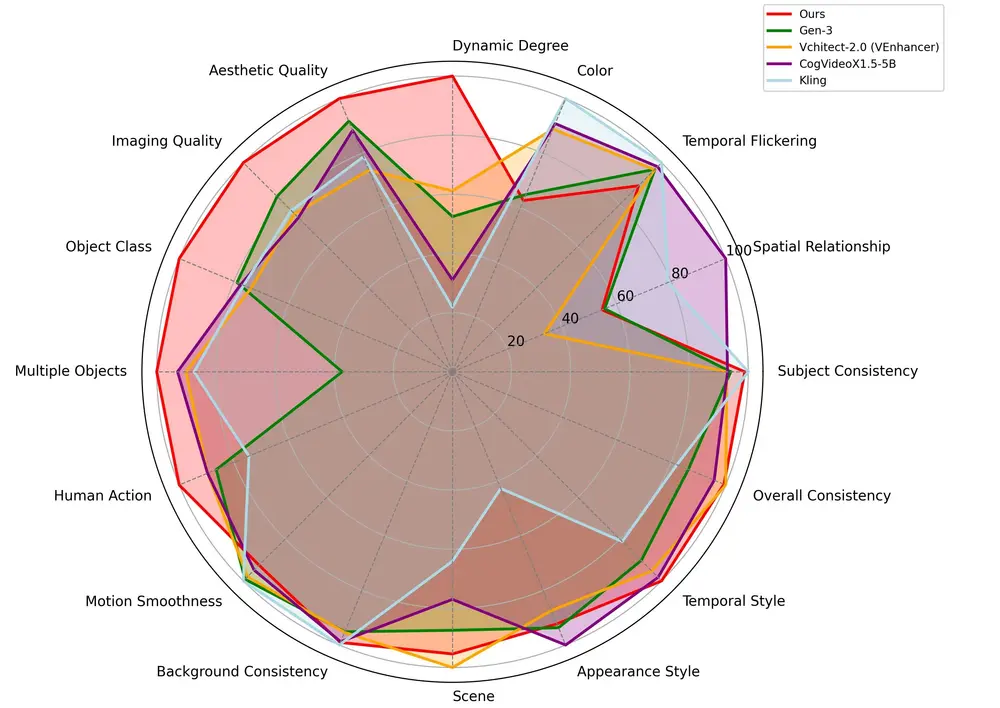
测试结果
CausVid 在多个基准测试中表现出色:
- VBench-Long 基准测试:CausVid 在 16 个标准化指标上取得了 84.27 的总分,超越了所有先前的视频生成模型。
- 文本到视频生成:在 10 秒视频生成任务中,CausVid 在时间质量、帧质量和文本对齐方面均优于 CogVideoX、OpenSORA 和 Pyramid Flow 等基线方法。
- 长视频生成:在 30 秒长视频生成任务中,CausVid 在时间质量和帧质量上优于 Gen-L-Video、FreeNoise 和 StreamingT2V 等方法。
- 效率测试:与 CogVideoX 相比,CausVid 的延迟降低了 160 倍,吞吐量提高了 16 倍。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...