
腾讯和清华大学的研究人员推出新型图生视频框架FlexiAct,实现灵活的动作控制,能够在异构场景(即具有不同空间结构、骨骼结构或视角的场景)中将参考视频中的动作迁移到任意目标图像上,同时保持动作动态和外观细节的一致性。此框架是基于智谱 AI推出的图生视频模型CogVideoX-5B-I2V。
- 项目主页:https://shiyi-zh0408.github.io/projectpages/FlexiAct
- GitHub:https://github.com/shiyi-zh0408/FlexiAct
- 模型:https://huggingface.co/shiyi0408/FlexiAct
例如,我们有一张目标图像,内容是一个静态的人像,而参考视频中是一个人在做瑜伽动作。FlexiAct 能够将参考视频中的瑜伽动作迁移到目标图像中的人像上,生成一段视频,其中目标人物准确地执行了参考视频中的动作,同时保持了目标图像的外观特征(如服装、发型等)。

主要功能
FlexiAct 的核心功能是实现动作迁移,即将一个参考视频中的动作准确地迁移到任意目标图像中的主体上。它能够处理以下复杂情况:
- 空间结构差异:目标图像和参考视频中的主体可以有不同的姿势、布局或视角。
- 骨骼结构差异:支持跨物种的动作迁移,例如将人类的动作迁移到动物身上,或反之。
- 外观一致性:生成的视频在外观上与目标图像保持高度一致,同时动作与参考视频保持一致。
主要特点
- 高适应性:能够适应各种异构场景,包括不同的空间布局、骨骼结构和视角。
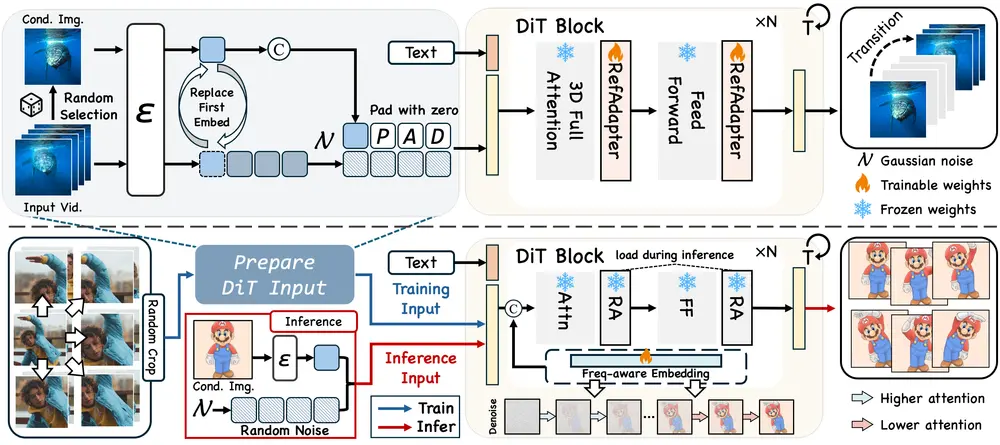
- 精确的动作控制:通过频率感知动作提取(FAE)技术,能够在去噪过程中直接提取动作信息,确保动作的准确性和连贯性。
- 轻量级设计:RefAdapter 仅引入少量可训练参数(5%的模型总参数),避免了大规模参数复制,降低了训练成本。
- 强大的外观一致性:通过 RefAdapter 的图像条件化架构,确保生成视频与目标图像在外观上的一致性。
工作原理
FlexiAct 的工作原理基于两个核心组件:RefAdapter 和 频率感知动作提取(FAE)。
- RefAdapter:
- RefAdapter 是一个轻量级的图像条件化适配器,用于解决空间结构适应性问题。
- 在训练阶段,RefAdapter 使用随机采样的帧作为条件图像,而不是固定使用第一帧。这使得模型能够适应不同的空间结构。
- 通过替换时间维度的第一个嵌入向量,RefAdapter 可以将参考动作引导到目标图像上,而不是将其限制为视频的起始点。
- 频率感知动作提取(FAE):
- FAE 通过在去噪过程中动态调整注意力权重,实现动作的精确提取。
- 在去噪的早期阶段,FAE 关注低频动作信息(如运动区域),而在后期阶段则关注高频细节(如外观特征)。
- 通过调整注意力权重,FAE 能够在生成过程中更准确地复制参考视频的动作。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











