
蚂蚁集团 inclusionAI 团队正式推出 Ming-flash-omni 2.0,搭载全新 Ling-2.0 混合专家(MoE)架构,以总参数 100B、激活参数 6B 的高效配置,在开源全能型多模态大模型(omni-MLLM)领域实现代际跃升,拿下全新 SOTA 水准。
- GitHub:https://github.com/inclusionAI/Ming
- Hugging Face:https://huggingface.co/inclusionAI/Ming-flash-omni-2.0
- 魔塔:https://www.modelscope.cn/models/inclusionAI/Ming-flash-omni-2.0
模型深度融合通用能力与专业领域知识,在视觉百科理解、沉浸式语音合成、高动态图像生成与编辑三大方向实现突破性体验。
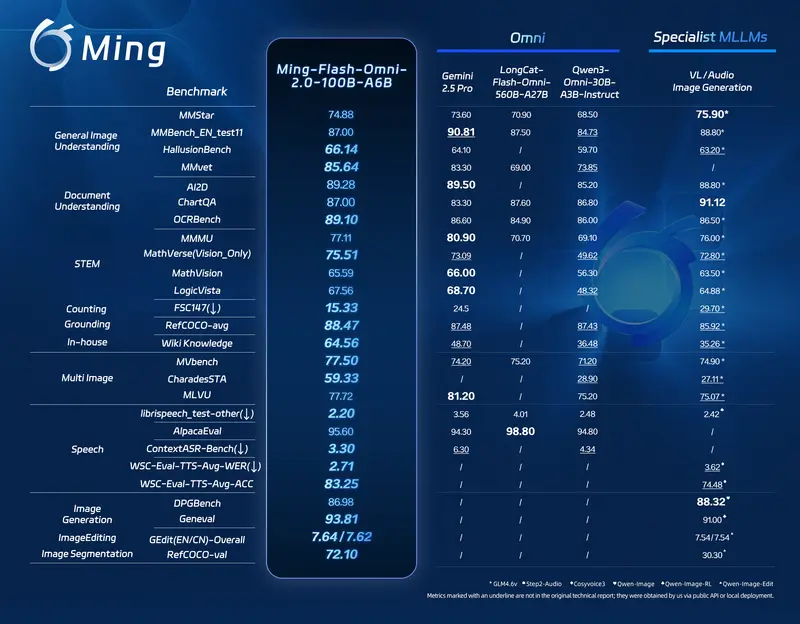
模型信息总览
| 模型名称 | 输入模态 | 输出模态 | 规模 |
|---|---|---|---|
| Ming-flash-omni 2.0 | 文本、图像、视频、音频 | 文本、图像、音频 | 100B 总参 / 6B 激活 |
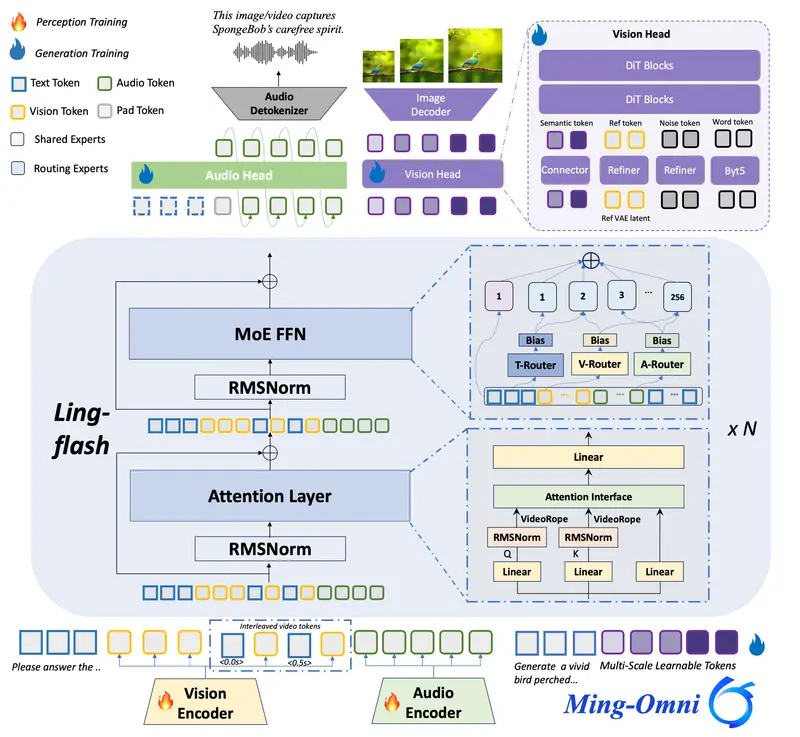
核心架构:Ling-2.0 MoE 高效架构
- 架构:Ling-2.0 混合专家 MoE 框架
- 总参数量:100B
- 激活参数量:6B
- 定位:轻量激活、超强推理、全能多模态
相比前代,在性能、精度、多模态统一生成能力上实现全面跃升。
三大核心能力升级
1. 专家级多模态认知
Ming-flash-omni 2.0 具备接近专业级的视觉理解能力:
- 精准识别动植物、菜品、地标、文物
- 深度解析文化背景、历史年代、形制工艺
- 高分辨率视觉感知 + 大规模知识图谱融合
- 实现“看到 → 识别 → 理解 → 知识输出”的完整链路
2. 沉浸式统一声学合成
业内领先的端到端统一声学生成体系:
- 单通道统一生成:语音、音效、音乐
- 连续自回归机制 + 扩散 Transformer(DiT)
- 支持零样本语音克隆
- 细粒度可控:情感、音色、语气、氛围、环境感
- 从传统 TTS 升级为高沉浸、强情感、拟人化听觉体验
3. 高动态可控图像生成与编辑
原生多任务统一架构,真正实现生成/编辑/分割一体化:
- 复杂时空语义解耦
- 高动态创作:氛围重建、无缝场景合成
- 智能对象移除、上下文保持
- 超强一致性:纹理一致、空间深度一致
- 在复杂图像编辑任务中达到业界领先精度
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











