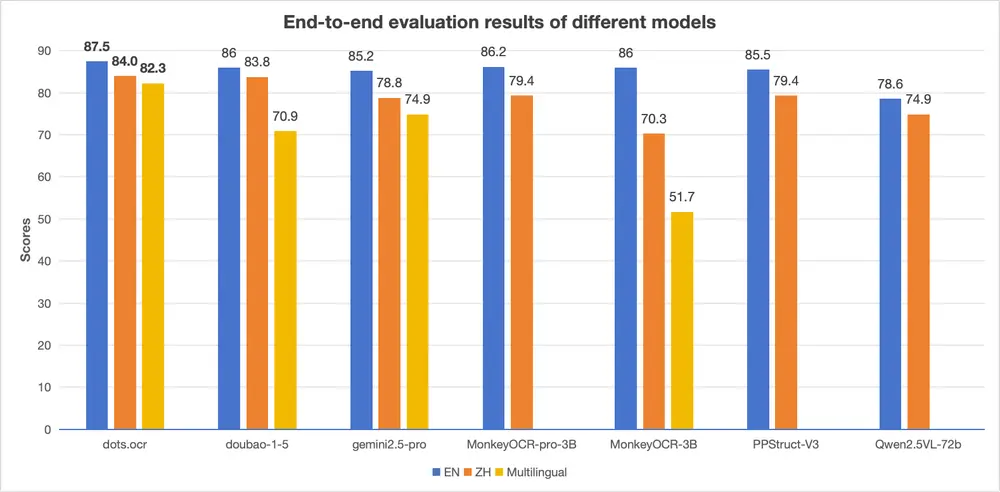
谷歌近日宣布推出全新 AI 模型 SignGemma,作为 Gemma 家族的新成员,它专注于将手语(尤其是美式手语 ASL)翻译成英文文本或语音输出,是目前最强大的开源手语理解模型之一。

SignGemma 的目标是为听障和聋人用户提供更便捷的技术支持,帮助他们更好地融入数字世界。该模型具备本地化处理能力,强调隐私保护,并计划在未来支持更多种手语语言。
🌟 核心功能亮点
✅ 快速翻译能力
- 翻译延迟低于 200 毫秒,实现实时交互体验。
- 支持离线使用,无需持续联网即可完成翻译任务。
✅ 本地化隐私设计
- 所有视频数据均在设备端处理,除非用户主动分享,否则不会上传云端。
- 强调对敏感人群的数据保护,符合无障碍技术伦理标准。
✅ 多平台兼容性
- 可运行于智能手机、平板电脑和笔记本电脑等主流设备。
- 适用于教育、医疗、客服等多种需要实时沟通的场景。
🔧 技术架构解析
SignGemma 基于 Gemini Nano 构建,采用以下关键技术:
- 视觉转换器(Vision Transformer):捕捉手部动作、面部表情和身体姿态,实现对手语的全面识别。
- 紧凑型语言模型:负责将视觉信号转化为英文文本输出,兼顾准确性和效率。
- 训练数据丰富:基于超过 10,000 小时的 ASL 视频资料,并配有英文转录文本,确保模型理解和表达能力。
👥 开发者预览与合作计划
SignGemma 目前已开放开发者预览,主要面向以下群体:
- 语言服务提供商
- 无障碍研究人员
- 聋人社区代表
提供资源包括:
- TensorFlow Lite 模型包
- GitHub 示例代码
- 托管 API 接口文档
同时,谷歌鼓励用户反馈翻译错误率,并提出方言覆盖建议,以不断优化模型表现。
🛠 应用场景展望
实时翻译助手
- 支持自动聊天口译、视频会议字幕生成,提升听障人士在远程会议、在线课堂中的参与度。
无障碍信息访问
- 在医院、银行、政府服务等公共场景中,辅助听障用户与工作人员进行顺畅交流。
开发者友好接口
- 提供完整 API 和集成指南,便于第三方应用快速接入,打造个性化无障碍工具。
⚠️ 局限性与伦理考量
尽管 SignGemma 表现优异,但仍存在一些局限性:
- 对地区变体、非手动信号(如面部表情)识别仍需加强。
- 多人手势重叠、低光环境可能影响识别准确性。
- 当前仅支持美式手语(ASL),多语言扩展仍在规划中。
谷歌也高度重视伦理问题:
- 发布了详细的模型卡,公开训练数据来源和性能边界。
- 鼓励开发者在部署前审查隐私合规要求,保障用户权益。
📅 上线时间与获取方式
- 当前状态:通过 Google AI 开发者门户提供有限预览。
- 广泛发布:预计将在 2025 年第四季度 正式向公众开放。
- 访问链接: goo.gle/SignGemma.(实际请以官网为准)
开发者可在此页面申请 API 密钥、下载模型文件并获取集成指南。
🔄 未来发展方向
谷歌表示,未来计划逐步扩展 SignGemma 对其他手语体系的支持,例如英国手语(BSL)、印度手语(ISL)等,具体时间表尚未公布。
此外,团队将持续收集来自聋人社区和研究机构的反馈,进一步优化模型的准确性和适应性,推动全球无障碍通信的发展。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











