
字节跳动正式推出 Seed1.5-VL,这是一款专注于提升多模态理解与推理能力的视觉-语言基础模型。Seed1.5-VL 不仅在视觉和视频理解任务中表现出色,还在智能体相关任务及复杂推理挑战中展现了卓越的能力。该模型在 60 项公开评测基准中的 38 项取得了 SOTA(State-of-the-Art)表现,进一步巩固了其在多模态领域的领先地位。
- 项目主页:https://seed.bytedance.com/zh/tech/seed1_5_vl
- GitHub:https://github.com/ByteDance-Seed/Seed1.5-VL
- Demo:https://huggingface.co/spaces/ByteDance-Seed/Seed1.5-VL

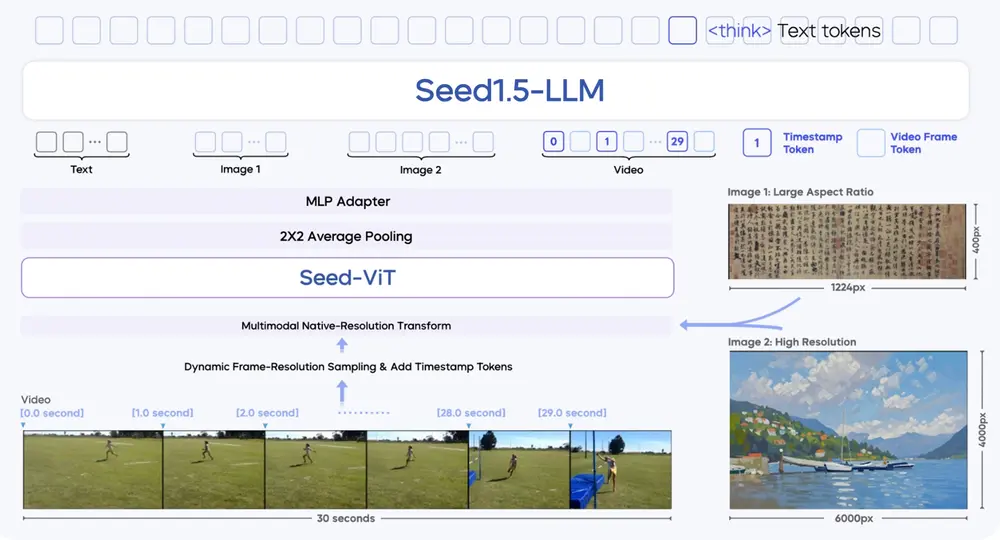
模型架构
Seed1.5-VL 的核心架构由三个关键组件组成:
- SeedViT(视觉编码器)
- 包含 5.32 亿参数,用于对图像和视频进行高效编码。
- 支持多种分辨率的图像输入,并通过 原生分辨率变换(native-resolution transform) 最大限度保留图像细节。
- 在视频处理方面,引入了 动态帧分辨率采样策略(dynamic frame-resolution sampling strategy),能够根据任务需求动态调整采样帧率和分辨率。
- MLP 适配器
- 将视觉特征映射为多模态 token,实现视觉信息与语言模型的无缝衔接。
- 混合专家(MoE)大语言模型
- 激活参数规模达 200 亿,具备强大的多模态推理能力。
- 能够处理复杂的跨模态任务,如视觉问答(VQA)、视频理解、智能体交互等。
此外,为了增强模型的时间信息感知能力,我们在每帧图像之前引入了 时间戳标记(timestamp token),以捕捉视频中的动态变化。
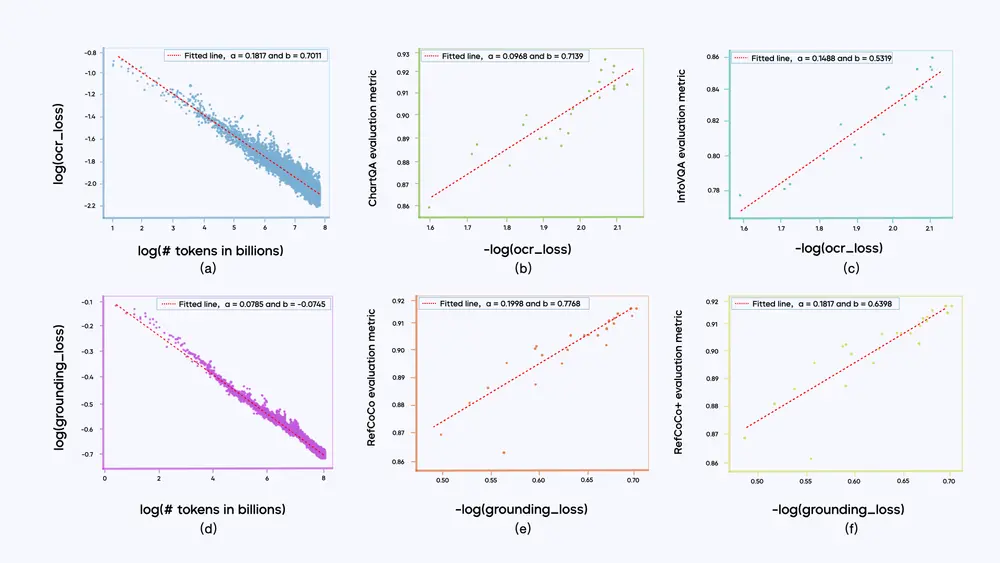
预训练数据与 Scaling Law
Seed1.5-VL 的预训练语料库包含 3 万亿个多样化且高质量的源标记(source tokens),这些数据根据模型目标能力的需求进行了分类。例如:
- 图像和视频相关的标注数据。
- 复杂推理任务的提示和答案。
- 多模态对话和指令数据。
在预训练阶段,我们观察到以下规律:
- 幂律关系:大多数子类别的训练损失与训练标记数量之间遵循幂律关系(Power Law),即训练数据量越大,模型的训练损失越小。
- 对数线性关系:某一子类别的训练损失与其对应的下游任务评估指标之间呈现对数线性关系(Log-linear Relationship)。这一趋势尤其在局部区域内显著,表明训练数据的质量和分布对模型性能有重要影响。
后训练优化
Seed1.5-VL 的后训练过程采用了结合 拒绝采样(rejection sampling) 和 在线强化学习(online reinforcement learning) 的迭代更新方法。具体特点包括:
- 数据 pipeline:我们构建了一条完整的数据 pipeline,用于收集和筛选复杂提示,确保后训练阶段的数据质量。
- 监督信号设计:监督信号通过 奖励模型(reward models) 和 规则验证器(rule verifiers) 仅作用于模型生成的最终输出结果。这种方法避免了对模型的详细链式思维推理(chain-of-thought reasoning)过程进行直接干预,从而保持了模型的灵活性和创造性。
- 插图说明:插图右侧部分重点说明了强化学习的实现机制,展示了监督信号如何应用于最终输出,而不是中间推理过程。

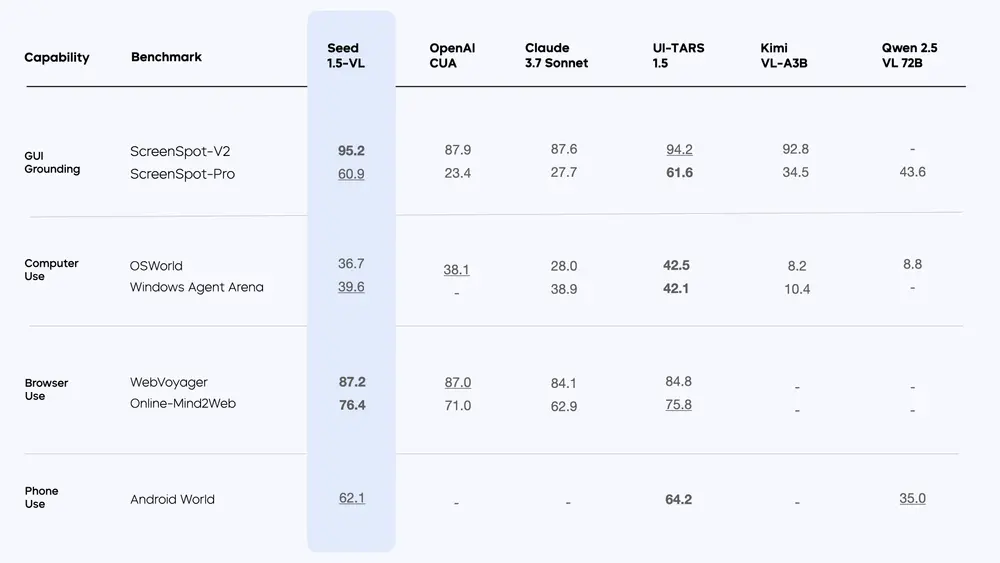
基准测试
Seed1.5-VL 在 60 项公开基准测试 中取得了 38 项 SOTA 表现,其中包括:
- 19 项视频基准测试中的 14 项:在视频理解任务中展现优异性能。
- 7 项 GUI 代理任务中的 3 项:证明了其在智能体相关任务中的潜力。

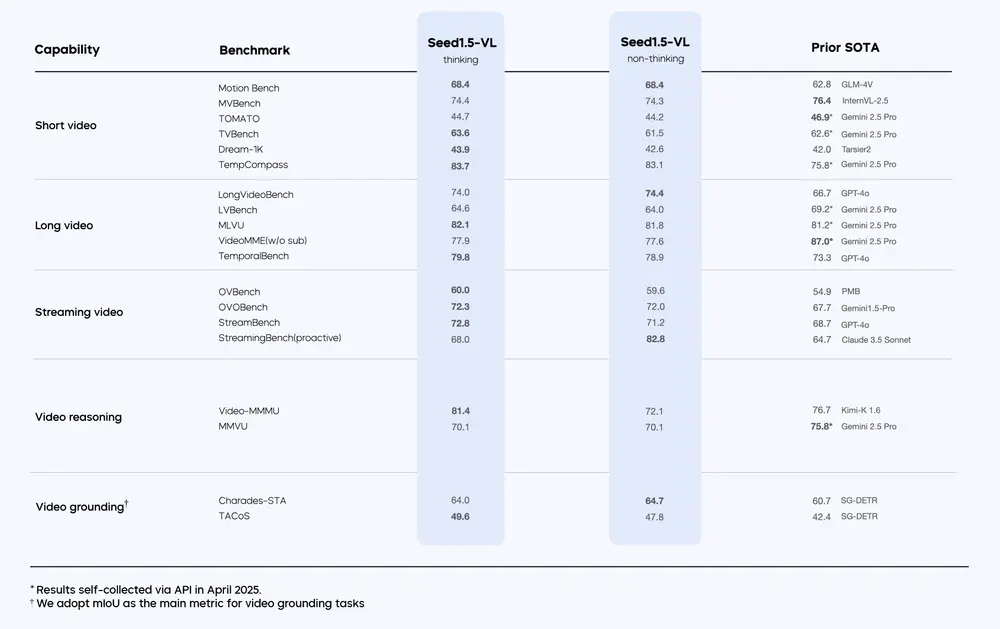
以下是部分亮点:
- 在视觉问答(VQA)任务中,Seed1.5-VL 凭借其强大的多模态推理能力,显著超越现有模型。
- 在视频理解任务中,动态帧分辨率采样策略帮助模型更好地捕捉动态场景中的细节。
- 在复杂推理任务中,Seed1.5-VL 展现了出色的跨模态理解和逻辑推导能力。
局限性与未来方向
尽管 Seed1.5-VL 展现了卓越的多模态能力,但仍存在一些局限性,主要包括:
- 细粒度视觉感知
模型在处理高精度细节时可能不够准确,尤其是在低分辨率或噪声较大的图像中。 - 三维空间推理
当前模型在三维空间感知和推理任务中仍有一定局限性,无法完全模拟真实世界的物理环境。 - 复杂组合搜索任务
对于需要大量组合搜索的任务(如复杂游戏或规划问题),模型的表现仍有提升空间。
未来研究方向
- 统一现有模型能力与图像生成
结合生成模型(如扩散模型)与多模态理解模型,进一步提升生成和推理能力。 - 引入更健全的工具使用机制
增强模型在实际应用中的工具调用能力,使其能够更好地完成复杂任务。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











