
在通用视觉语言模型(VLM)主导多模态任务的当下,百度飞桨团队反其道而行之,推出新一代轻量级文字识别模型 PP-OCRv5 ——一个仅含 70万参数(0.07B)的超小模型,在多项 OCR 任务中表现超越 GPT-4o、Qwen2.5-VL-72B 等千亿参数级大模型。
- GitHub:https://github.com/PaddlePaddle/PaddleOCR
- 模型:https://huggingface.co/collections/PaddlePaddle/pp-ocrv5-684a5356aef5b4b1d7b85e4b
- Demo:https://huggingface.co/spaces/PaddlePaddle/PP-OCRv5_Online_Demo
这一成果不仅刷新了轻量化OCR的技术边界,也再次证明:专用模型在特定任务上,依然具备压倒性的效率与精度优势。
背景:当大模型遇上OCR,为何“力不从心”?
近年来,以 GPT-4o、Gemini、Qwen-VL 为代表的通用视觉语言模型(VLM)展现出强大的图文理解能力。但在实际 OCR 场景中,它们面临三大瓶颈:
- 文本定位不准:难以精确框出文本行位置;
- 边界框质量差:输出坐标偏移严重,影响后续结构化处理;
- 存在“幻觉”风险:生成图像中并不存在的文字内容;
- 计算开销巨大:依赖高性能 GPU,难部署于边缘设备。
这些问题在教育、医疗、金融等对准确性要求极高的行业中尤为致命。
正是在这样的背景下,PP-OCRv5 的出现提供了一条更务实、高效的替代路径。
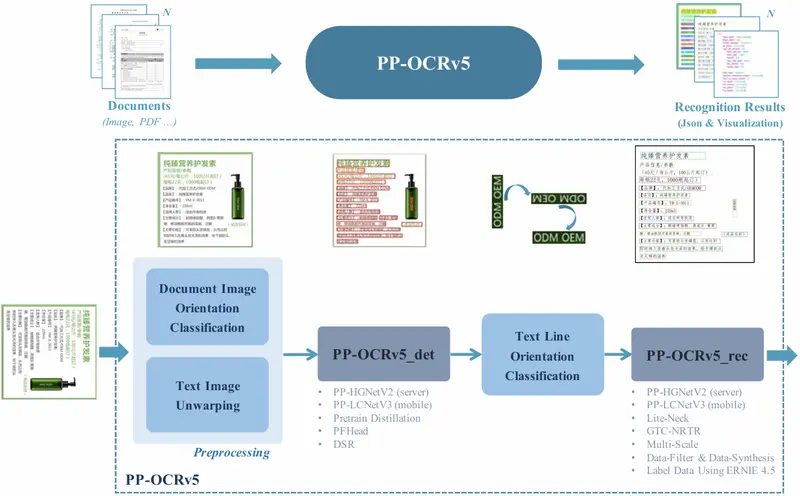
核心突破:模块化双阶段架构,专为OCR而生
PP-OCRv5 延续 PaddleOCR 系列经典的 两阶段流水线设计,将任务分解为:
- 文本检测
- 文本识别
中间辅以:
- 图像预处理(矫正旋转、扭曲)
- 文本方向分类(确保正确对齐)
这种模块化设计带来多重优势:
- 每个阶段可独立优化,提升整体鲁棒性;
- 避免端到端模型的“黑箱”问题;
- 显著降低推理资源消耗,支持 CPU 和边缘设备运行。
它不是“全能选手”,而是“专业运动员”。
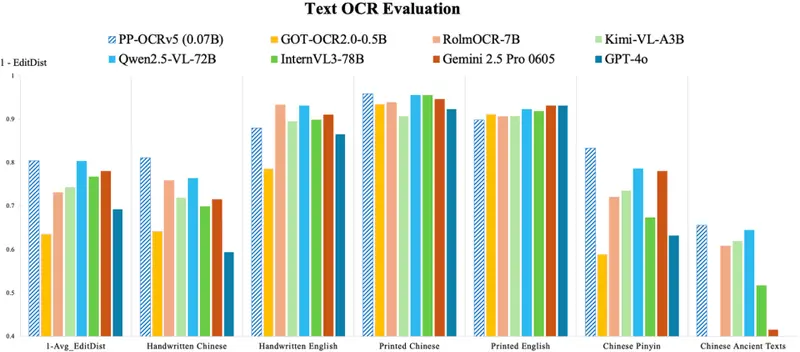
性能对比:小模型,大能量
根据官方发布的 OmniDocBench OCR 基准测试结果,PP-OCRv5 在多个关键任务上表现优于主流 VLM:
| 任务类型 | PP-OCRv5 表现 |
|---|---|
| 印刷中文 | 精度媲美 Qwen2.5-VL-72B |
| 印刷英文 | 超越 GPT-4o 和 Gemini Pro |
| 手写英文 | 平均 1-编辑距离得分最高 |
| 手写中文 | 在复杂字形下仍保持高准确率 |
| 拼音识别 | 特殊场景稳居前列 |
尤其值得注意的是,在 Handwritten Chinese 和 Chinese Pinyin 这类易混淆、低质量输入场景中,PP-OCRv5 展现出更强的泛化能力和抗干扰性。
关键特性一览
| 特性 | 说明 |
|---|---|
| 📦 超轻量级 | 参数仅 0.07 亿,模型体积 <100MB |
| ⚡ 高性能推理 | 移动版在 Intel Xeon CPU 上达 370+ 字符/秒 |
| 🌍 多语言支持 | 支持简体中文、繁体中文、英文、日文、拼音 |
| 🔤 多文字类型 | 可识别超过 40 种语言 |
| ✅ 精准定位 | 提供高质量文本行边界框,适用于结构化提取 |
| 💡 开源开放 | 已上线 Hugging Face,支持在线体验与本地部署 |
PP-OCRv5 是目前业界首个单模型支持 五种文字类型 的超轻量级开源 OCR 模型,真正实现“一模型多用”。
实际应用场景广泛
得益于其高精度、低延迟、易部署的特点,PP-OCRv5 可广泛应用于以下领域:
- 教育行业:自动批改试卷、作业数字化
- 医疗行业:病历扫描录入、处方识别
- 法律与政务:合同、笔录、档案电子化
- 金融行业:票据识别、表单自动化处理
- 企业办公:PDF/扫描件内容提取与检索
对于需要高吞吐、低误差率的业务系统而言,PP-OCRv5 提供了一个稳定可靠的底层能力支撑。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











