
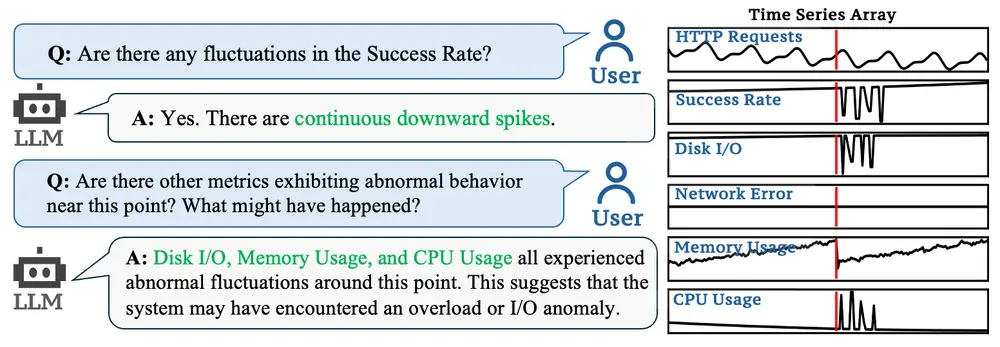
清华大学和字节跳动的研究人员推出多模态大语言模型ChatTS ,专门用于时间序列分析。它通过自然语言命令帮助用户快速理解时间序列数据,执行日常任务,并处理复杂的推理问题。ChatTS 的核心优势在于其能够将时间序列数据作为独立的模态进行处理,类似于视觉 MLLM 处理图像的方式,从而实现对时间序列的深度理解和推理。
主要功能
编辑文件并修复代码库中的错误:ChatTS 可以直接编辑文件,修复代码中的错误,确保代码的正确性和可读性。 回答有关代码架构和逻辑的问题:通过自然语言命令,ChatTS 能够解释代码的架构和逻辑,帮助用户更好地理解代码。 执行并修复测试、代码检查等命令:自动运行测试和代码检查命令,并根据结果提供修复建议,确保代码质量。 搜索 Git 历史记录,解决合并冲突,创建提交和拉取请求:通过 Git 历史记录搜索,快速定位问题,解决合并冲突,并创建提交和拉取请求。 时间序列理解与推理:ChatTS 能够处理多变量时间序列数据,执行复杂的推理任务,如趋势分析、周期性检测、异常识别等。
主要特点
多模态处理能力:ChatTS 将时间序列数据作为独立模态处理,支持多变量时间序列输入,能够同时处理多个时间序列数据。 合成数据生成:为了解决高质量时间序列与文本对齐数据稀缺的问题,ChatTS 提出了一种基于属性的合成数据生成方法,能够生成具有详细属性描述的时间序列数据。 时间序列演化指令(TSEvol):通过多样化的属性组合和任务,TSEvol 能够生成多样化的问答数据集,增强模型的推理能力。 自适应界面:ChatTS 提供自适应界面,支持压感触控笔输入,可配置多种笔划样式,适用于不同设备和屏幕尺寸。 高效推理:ChatTS 通过上下文感知的时间序列编码器,能够处理任意长度的时间序列数据,同时保留原始数值信息。
工作原理
合成数据生成:ChatTS 使用基于属性的方法生成合成时间序列数据。这些数据不仅包含时间序列的数值信息,还附带详细的文本描述,确保模型能够准确理解和对齐时间序列与文本信息。 时间序列编码:ChatTS 将输入的时间序列数据分割成固定大小的片段,通过多层感知机(MLP)对每个片段进行编码,然后将编码后的片段与文本嵌入对齐,确保时间序列和文本信息在同一空间中表示。 上下文感知编码:ChatTS 通过上下文感知的时间序列编码器,将多变量时间序列数据的上下文信息完整保留,确保模型能够准确分析多变量之间的关系。 问答生成与训练:使用 TSEvol 算法生成多样化的问答数据集,通过大规模对齐训练和监督微调(SFT),提升模型的时间序列理解能力和推理能力。
具体应用场景
AIOps(人工智能运维):在系统监控和故障诊断中,ChatTS 可以通过自然语言对话帮助运维人员快速定位问题,分析多变量时间序列数据,识别异常并提供解决方案。 金融市场分析:ChatTS 可以分析股票价格、交易量等时间序列数据,帮助投资者进行市场趋势分析和风险评估。 医疗健康:在医疗领域,ChatTS 可以分析心电图(ECG)、脑电图(EEG)等时间序列数据,辅助医生进行疾病诊断和治疗方案制定。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











