在当前机器人智能领域,视觉-语言-动作(Vision-Language-Action, VLA)模型正成为连接感知与行为的核心技术。这类模型能让机器人“听懂指令”、“看懂场景”,并自主执行任务,例如:“把桌上的黑色碗放到盘子里”。
然而,现有方法普遍依赖大规模视觉语言模型(如 7B 参数的 OpenVLA),且需在大量机器人数据上预训练,导致部署成本高、训练周期长、难以普及。
为此,北京邮电大学、浙江大学、西湖大学、OpenHelix 团队、网络与交换技术国家重点实验室以及香港科技大学(广州)的研究人员联合提出 VLA-Adapter ——一种新型轻量级 VLA 架构,旨在以更低的成本实现高性能动作生成。
- 项目主页:https://vla-adapter.github.io
- 模型:https://huggingface.co/collections/VLA-Adapter/vla-adapter-models-68b3fcb2e6c790f9821aff7d
其核心思想是:不重训大模型,而是通过一个小型适配模块,将已有视觉语言能力高效转化为机器人动作。
问题本质:大模型 ≠ 高效率
当前主流 VLA 模型通常采用“全参数微调”方式,在数百万机器人交互数据上对大型 VLM 进行端到端训练。虽然性能不错,但存在三大瓶颈:
- 计算资源消耗巨大:动辄需要多卡 A100 训练数天;
- 训练门槛高:依赖专用机器人平台采集数据;
- 推理慢:模型臃肿,难以部署到边缘设备。
更关键的是:是否必须用 7B 的模型才能完成一个“拿碗放盘”的任务?
研究人员发现:真正影响动作生成的,并非整个大模型,而是其中特定层次的多模态特征。
于是,他们提出了一个反向思路:冻结主干模型,只训练一个小而高效的“桥接模块”。
这就是 VLA-Adapter 的出发点。
核心创新:桥接注意力 + 轻量策略网络
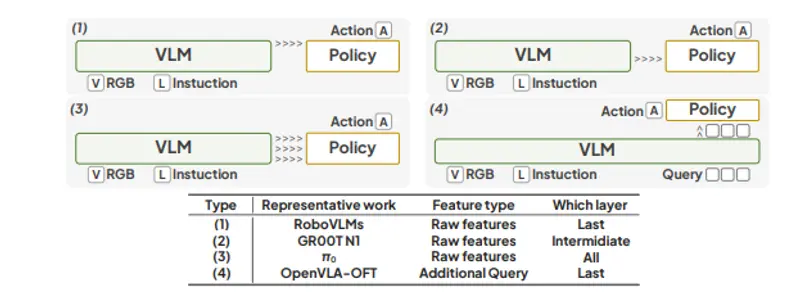
架构概览
VLA-Adapter 不修改或重训底层视觉语言模型(VLM),而是引入两个新组件:
- 动作查询(Action Queries):一组可学习的向量,作为动作空间的潜在表示;
- 轻量级 Policy 网络:仅含 97M 参数的小型 Transformer,负责融合 VLM 多层特征并生成动作序列。
两者通过 桥接注意力机制(Bridge Attention) 实现跨层交互。
🔄 工作流程
- 输入处理:
- 视觉输入:第三视角图像 + 夹爪图像
- 语言输入:自然语言指令(如“拿起红色积木”)
- 特征提取:
- 使用 DINOv2 / SigLIP 提取图像嵌入
- 使用 Qwen2.5-0.5B 等小型 VLM 编码图文信息
- 桥接注意力机制:
- 将 VLM 各层的原始特征与动作查询同时注入 Policy 网络
- 动作查询通过自注意力聚合全局语义
- 原始特征通过可控注入方式参与决策(防止干扰)
- 动作输出:
- Policy 网络解码出连续动作向量(如机械臂位姿、夹爪开合)
- 控制机器人完成任务
✅ 整个过程中,主干 VLM 完全冻结,仅训练 Adapter 模块。
关键技术洞察
研究团队通过系统实验回答了多个关键问题,得出以下重要发现:
| 问题 | 关键发现 |
|---|---|
| 哪一层特征最有用? | 中层视觉特征保留更多细节,更适合动作生成;深层偏向语义抽象,作用有限 |
| 动作查询 vs 原始特征? | 动作查询表现更好,尤其在使用多层时提升显著(+2.0% 成功率) |
| 需要多少动作查询? | 64 个为最优平衡点:太少则信息不足,太多则冗余干扰 |
| 如何融合多层特征? | 使用所有层优于单一选择,既提升性能又省去调参成本 |
| 是否需要调节注入强度? | 是。原始特征需控制注入程度,动作查询可直接完全注入 |
这些发现支撑了 VLA-Adapter 的设计合理性。
实验结果:小模型,大性能
✅ 在 LIBERO-Long 基准上的表现
| 模型 | 主干参数 | 成功率 |
|---|---|---|
| OpenVLA-OFT | 7B | 94.8% |
| VLA-Adapter | 0.5B | 95.0% |
👉 使用仅 0.5B 参数的主干,性能超越 7B 模型!
这表明:性能瓶颈不在模型大小,而在特征利用效率。
⚡ 推理效率大幅提升
| 模型 | 吞吐量(Hz) |
|---|---|
| OpenVLA-OFT | 71.4 Hz |
| VLA-Adapter | 219.2 Hz |
👉 推理速度提升 3 倍以上,更适合实时控制场景。
此外,GPU 内存占用更低,可在单张消费级显卡(如 RTX 3090/4090)上运行。
🌐 泛化能力强:零样本迁移测试
在 CALVIN ABC→D 基准(跨任务零样本泛化)中:
| 模型 | 平均成功步长 |
|---|---|
| 其他方法 | < 4.0 |
| VLA-Adapter | 4.42 |
说明其具备较强的跨任务适应能力,无需额外训练即可应对新场景。
训练便捷性:8 小时即可完成训练
得益于冻结主干的设计,VLA-Adapter 的训练极为高效:
- 数据量:仅需标准机器人数据集(如 LIBERO)
- 硬件需求:单张消费级 GPU
- 训练时间:约 8 小时
- 显存占用:远低于全参数微调方案
这意味着,高校实验室甚至个人开发者也能快速复现并部署自己的 VLA 模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











