加拿大 AI 初创公司 Cohere 于 2019 年成立,专注于为企业提供 AI 解决方案。尽管在与 OpenAI 和 Anthropic 等美国巨头的竞争中市场份额有限,且面临来自中国开源竞争对手 DeepSeek 的挑战,Cohere 仍在持续增强其产品线。
今天,Cohere 的非营利研究部门 Cohere for AI 宣布推出其首个视觉模型 Aya Vision,这是一个开放权重的多模态 AI 模型,集成了语言和视觉功能,并支持多达 23 种语言的输入。
Aya Vision 的核心特点
1. 多语言支持
Aya Vision 支持包括英语、中文、西班牙语等在内的 23 种语言,覆盖了世界一半以上的人口。这一特性使其能够吸引广泛的全球受众,特别适合在全球多个市场运营的企业和组织。
2. 多模态能力
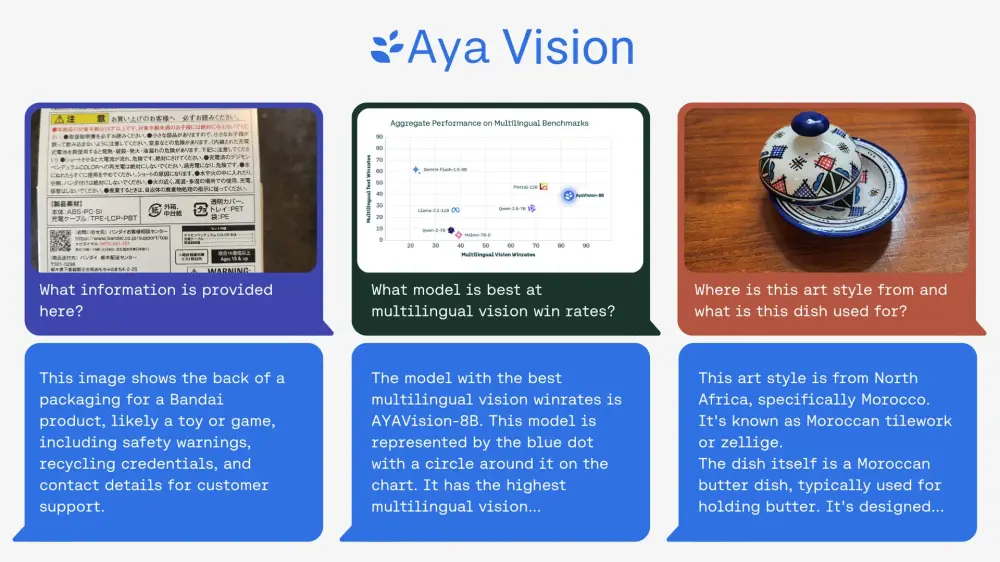
Aya Vision 能够解释图像、生成文本,并将视觉内容翻译成自然语言。这种多模态能力使其适用于多种任务,例如图像字幕生成、视觉问答、文本生成以及跨语言的视觉内容理解。
3. 开放权重发布
Aya Vision 在 Cohere 官方网站、Hugging Face 和 Kaggle 上以 Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0) 许可发布。研究人员和开发人员可以免费使用、修改和共享该模型,但仅限于非商业用途。
4. WhatsApp 集成
用户可以通过 WhatsApp 直接与 Aya Vision 交互,使全球用户能够在熟悉的环境中轻松利用这一先进的 AI 技术。
官方介绍全文:
深入了解 Aya Vision:推进多语言多模态的前沿
随着 Aya Vision 系列(我们新的 8B 和 32B 参数视觉语言模型 (VLM))的发布,我们正在解决 AI 中最大的挑战之一:将多语言性能带入多模态模型。
Aya Vision 是 Cohere For AI 最新的开放权重多语言和多模态模型系列,旨在为 23 种语言的语言和视觉理解奠定坚实的基础。它建立在最先进的多语言语言模型 Aya Expanse 的成功基础上,并通过结合先进技术对其进行了扩展。这些技术包括合成注释、通过翻译和释义扩大多语言数据规模以及多模态模型合并——这些都是在多语言环境中提高语言和视觉理解的关键方法。
因此,我们的模型在各种任务中表现良好,包括图像字幕、视觉问答、文本生成以及将文本和图像翻译成清晰的自然语言文本。我们在包括我们新的开放式视觉语言基准 AyaVisionBench 和翻译成 23 种语言的多语言版本 Wild Vision Bench (mWildVision) 在内的一组数据集上评估了 Aya Vision 模型,我们同时发布了这两个数据集供研究使用。
在成对比较中,Aya Vision 32B 在 AyaVisionBench 上的胜率在 50% 到 64% 之间,在 23 种语言的 mWildVision 平均胜率在 52% 到 72% 之间,优于比其大 2 倍以上的模型,例如 Llama-3.2 90B Vision、Molmo 72B 和 Qwen2.5-VL 72B。
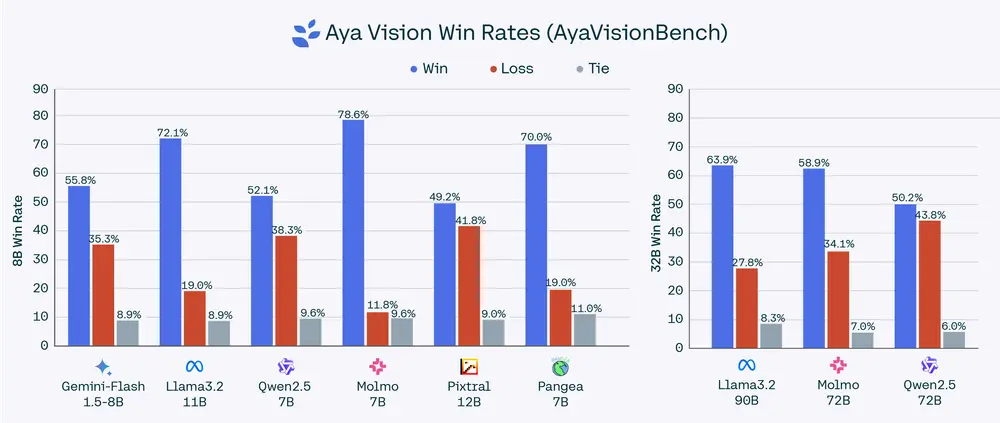
我们紧凑且更高效的模型 Aya Vision 8B 在其参数类别中实现了多语言多模态的最佳性能,在 AyaVisionBench 上的胜率高达 79%,在 mWildBench 上的胜率高达 81%,优于 Qwen2.5-VL 7B、Pixtral 12B、Gemini Flash 1.5 8B、Llama-3.2 11B Vision、Molmo-D 7B 和 Pangea 7B 等领先模型。
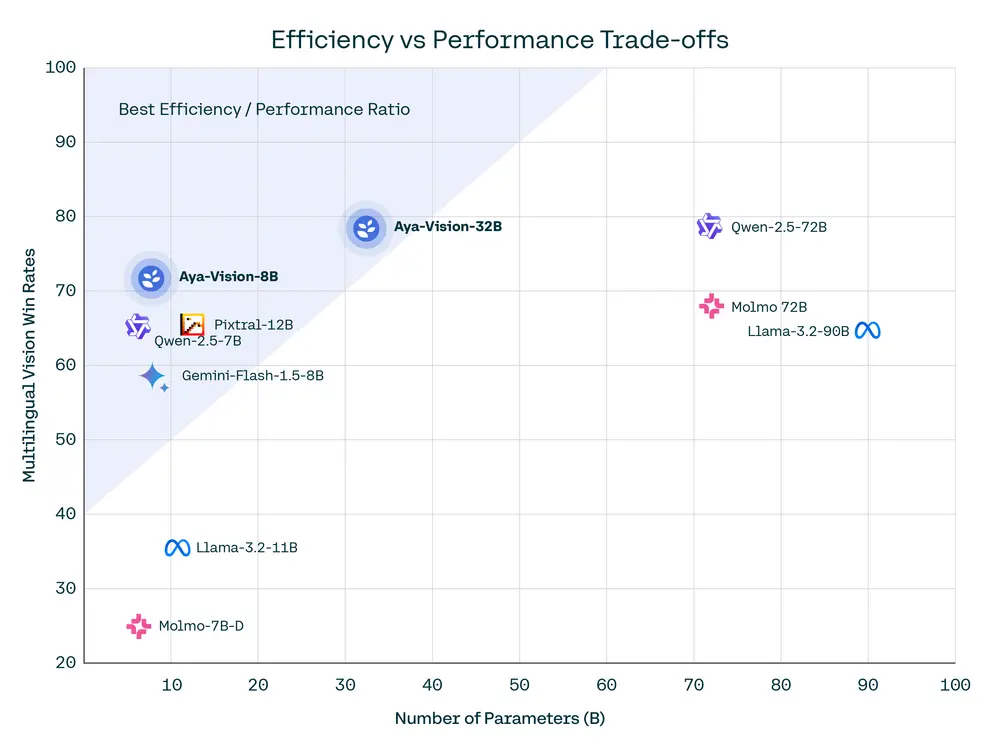
我们发布了 8B 和 32B 模型作为开放权重,供研究社区进一步加速多语言多模态的进展。在这篇博文中,我们分享了 Aya Vision 模型背后的关键技术细节。
Aya Vision 架构和训练
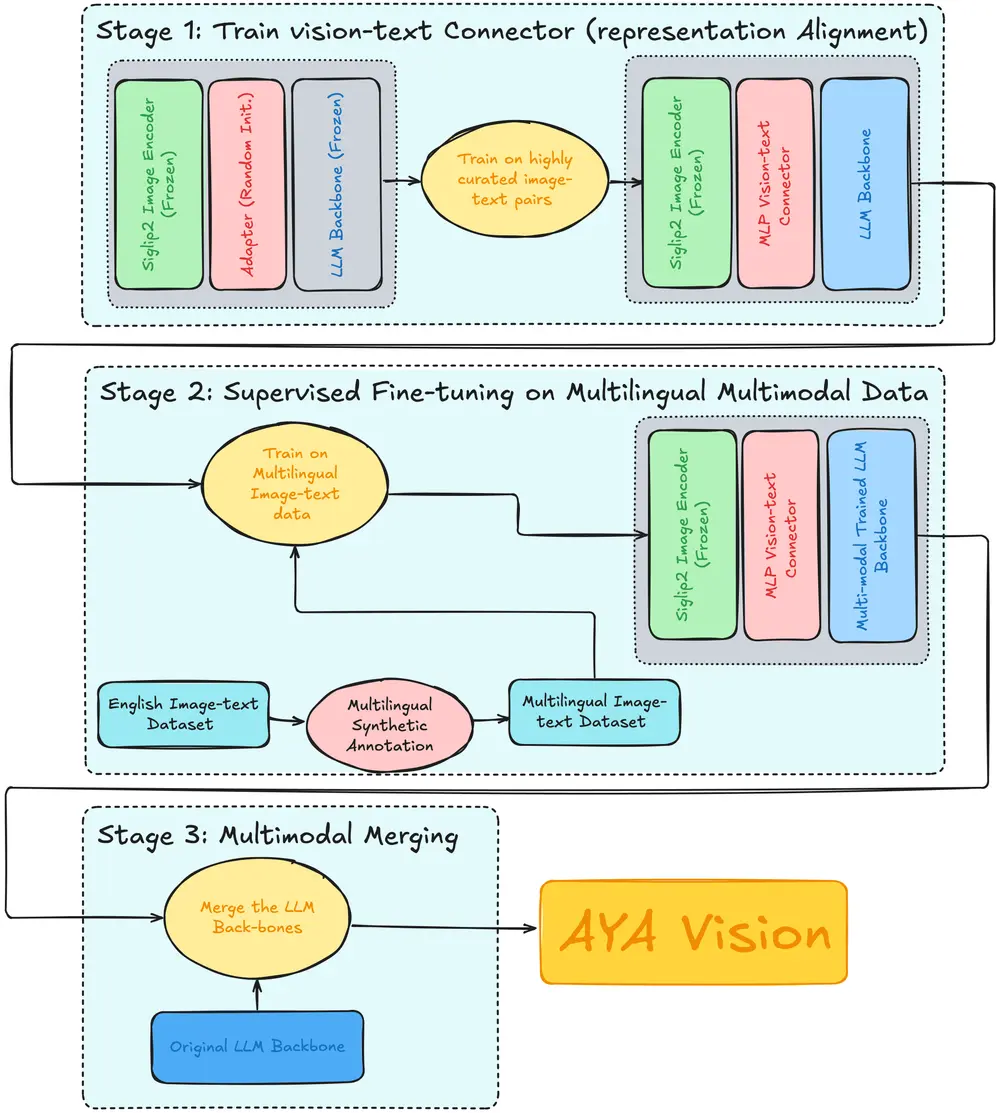
对于高性能视觉语言模型,处理任意分辨率的图像(尤其是高分辨率图像)非常重要。为了在 Aya Vision 中实现此功能,我们动态调整大小并将任何高分辨率图像拆分为多个图块,以从图像编码器生成丰富的图像特征。在 Aya Vision 模型中,我们使用最新发布的 SigLIP2-patch14-384 模型作为视觉编码器的初始化。

虽然动态调整大小可以处理高分辨率图像,但也会导致通过视觉语言连接器和 LLM 解码器的图像令牌数量增加。为了提高延迟和吞吐量,我们使用一种称为 Pixel Shuffle 的下采样方法将图像令牌的数量压缩 4 倍。下采样后,图像令牌通过视觉语言连接器与语言模型输入嵌入对齐,并传递给 LLM 解码器。
对于文本解码器,我们使用我们的多语言语言模型。对于 Aya Vision 8B,我们使用从 Cohere Command R7B 初始化的 LLM,以改进指令遵循和世界知识,并使用 Aya Expanse 配方(由多种多语言数据、模型合并和偏好训练组成)进一步进行后训练。对于 Aya Vision 32B,我们基于其最先进的多语言性能从 Aya Expanse 32B 初始化语言模型。
训练过程
我们在 2 个阶段训练 Aya Vision 模型——视觉语言对齐和监督微调 (SFT)。在视觉语言对齐阶段,仅训练视觉语言连接器,而视觉编码器和语言模型权重保持冻结。这通过将图像编码器特征映射到语言模型嵌入空间来实现基本的视觉语言理解。在 SFT 阶段,我们在 23 种语言的各种多模态任务上训练连接器和语言模型。
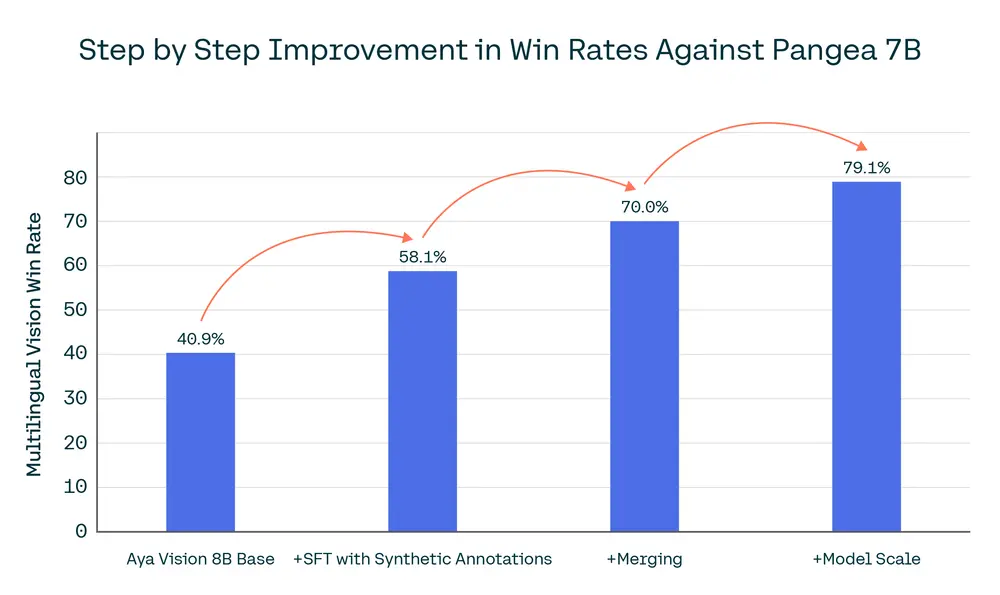
多模态数据增强和扩展语言覆盖范围
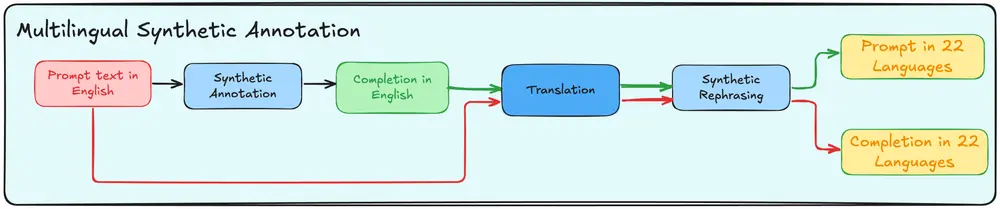
开发多语言视觉语言模型的最大挑战之一是确保在代表性不足的语言中实现强大的性能。为了解决这个问题,我们首先使用英语中各种高质量数据集收集合成注释,这些数据集为我们的多语言多模态注释奠定了基础。在对英语数据集进行合成注释之后,我们将大量数据翻译成 23 种语言。为了避免翻译伪影并在答案中保持高精度的流畅文本特征,我们通过将翻译后的提示/生成对与原始高质量合成样本进行匹配来重新措辞,从而在现实世界数据集稀缺的地方扩展语言覆盖范围。这提高了语言流畅性以及视觉和文本之间的对齐,使 Aya Vision 能够在多种语言中展示卓越的图像理解能力。
我们的 8B 模型在仅使用原始学术数据集进行监督微调时,在 AyaVisionBench 中针对多语言 VLM Pangea 7B 在 23 种语言中达到了 40.9% 的胜率,而合成注释和扩大多语言数据规模则达到了 58.1% 的胜率,增益为 17.2%。这一显著的改进展示了在多语言数据覆盖范围方面进行大量投资的影响。
多模态模型合并
一个最先进的视觉语言模型不仅应该擅长图像理解,还应该擅长对话语境,即模型能够对图像和文本输入生成高质量的响应。为了解决这个问题,受我们之前关于模型合并的研究启发(模型合并是一种结合多个训练模型的技术),我们将基础语言模型与微调后的视觉语言模型合并。
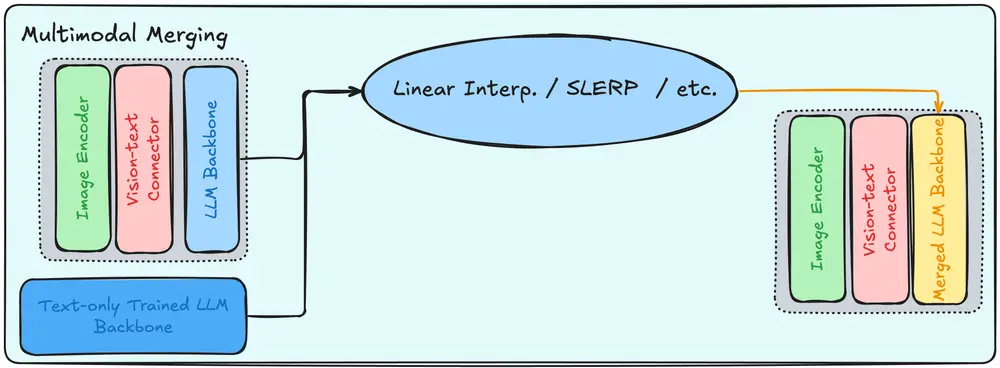
模型合并增强了我们最终模型的生成能力,在 AyaVisionBench 上针对 Pangea 7B 实现了 23 种语言 70% 的胜率,与合并前的模型相比,多模态胜率提高了 11.9%。
多模态模型合并还使我们的 Aya Vision 模型能够在仅文本任务中表现出色,如 mArenaHard 数据集所衡量,与其他领先的视觉语言模型相比。
扩展到 32B
最后,我们将我们的配方从 8B 扩展到 32B,从而产生了最先进的开放权重多语言视觉语言模型——Aya Vision 32B,由于文本骨干的更强初始化,其胜率显著提高,并且在 AyaVisionBench 上的胜率在 49% 到 63% 之间,在 23 种语言的 mWildVision 平均胜率在 52% 到 72% 之间,优于比其大 2 倍以上的模型,例如 Llama-3.2 90B Vision、Molmo 72B 和 Qwen2.5-VL 72B。

Aya Vision 基准测试——多语言评估数据
与 Aya Vision 模型一起,我们还发布了一个高质量的多语言视觉语言基准测试,名为 AyaVisionBench,它基于现实世界的应用程序构建,涵盖 23 种语言和 9 个不同的任务类别,每种语言有 135 个图像-问题对。
我们将此评估集提供给研究社区,以推动多语言多模态评估的发展。该数据集旨在评估模型执行各种视觉语言任务的能力,包括字幕、图表和图形理解、识别两个图像之间的差异、一般视觉问答、OCR、文档理解、文本转录、涉及逻辑和数学的推理以及将屏幕截图转换为代码。通过结合多种语言和任务类型,该数据集为评估跨语言和多模态理解提供了一个广泛且具有挑战性的评估框架。
为了创建此数据集,我们首先从 Cauldron 保留的测试集中选择图像,这是一个源自 50 个高质量数据集的大型集合,确保它们在训练期间没有被看到。对于每个图像,我们然后生成一个相应的需要视觉上下文才能回答的问题。这些问题是合成生成的,然后通过两阶段验证过程进行完善。首先,人类注释者审查并验证每个问题,以确保它清晰、相关且真正依赖于图像。这种严格的选择和验证过程确保了该数据集可以作为评估多语言和现实世界环境中视觉语言模型的强大基准。
专为现实世界应用而设计
沟通以多种形式和多种语言进行。通过我们领先的研发,我们发布了一个模型,该模型有助于连接,无论是文本还是视觉,今天都支持 23 种不同的语言。
Aya Vision 具有广泛的实际应用,其中一个值得注意的例子是它在世界上使用最广泛的通信平台之一 WhatsApp 上的可用性。这使得使用多种语言的全球公民中的大量受众能够在他们每天用来交流的平台上利用 Aya Vision 的功能。
Aya 入门
入门指南:
- 从 Hugging Face 上的 Aya Vision 集合下载权重和数据集。
- 使用我们的 Hugging Face Space 尝试 Aya Vision,或在 Whatsapp 上对其进行文本测试。
- 使用我们的 colab 示例构建 Aya。
- 了解有关我们正在进行的多语言工作的更多信息。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











