微软的 OmniParser 发布了 V2 更新,这一版本的核心目标是将任何大语言模型(LLM)转化为能够理解和交互图形用户界面(GUI)的智能体。相比前一代,OmniParser V2 在检测更小可交互元素的准确性和推理速度上有了显著提升。
- GitHub:https://github.com/microsoft/OmniParser
- OmniTool:https://github.com/microsoft/OmniParser/tree/master/omnitool
- 模型:https://huggingface.co/microsoft/OmniParser-v2.0
- Demo:https://huggingface.co/spaces/microsoft/OmniParser-v2
OmniParser 是什么?
OmniParser 是一款通用的屏幕解析工具,它能够将用户界面截图解释并转换为结构化格式,从而改进现有的基于大语言模型的用户界面代理。OmniParser 的训练数据集包括:
- 可交互图标检测数据集:从流行的网页上收集并自动标注,突出显示可点击和可操作的区域。
- 图标描述数据集:将每个用户界面元素与其相应的功能关联起来。
OmniParser 的模型架构包括在上述数据集上微调的 YOLOv8 和 Florence-2 基础模型。
GUI 自动化的挑战
图形用户界面(GUI)自动化需要代理能够理解并交互用户屏幕。然而,使用通用大语言模型(LLM)作为 GUI 代理面临两大挑战:
- 可靠地识别用户界面中的可交互图标。
- 理解屏幕截图中各种元素的语义,并准确地将预期操作与屏幕上的相应区域关联起来。
OmniParser 正是通过将用户界面截图从像素空间“标记化”为 LLM 可解释的结构化元素,弥补了这一差距。这使得 LLM 能够基于一组已解析的可交互元素进行下一步操作预测。
OmniParser V2 的新特性
OmniParser V2 在功能上实现了质的飞跃。相比前代,它在检测较小的可交互元素和推理速度上实现了更高的准确性,使其成为 GUI 自动化的强大工具。具体改进包括:
- 更大的交互元素检测数据集和图标功能标题数据集:用于训练模型。
- 更低的延迟:通过减小图标标题模型的图像尺寸,OmniParser V2 将延迟比前代降低了 60%。
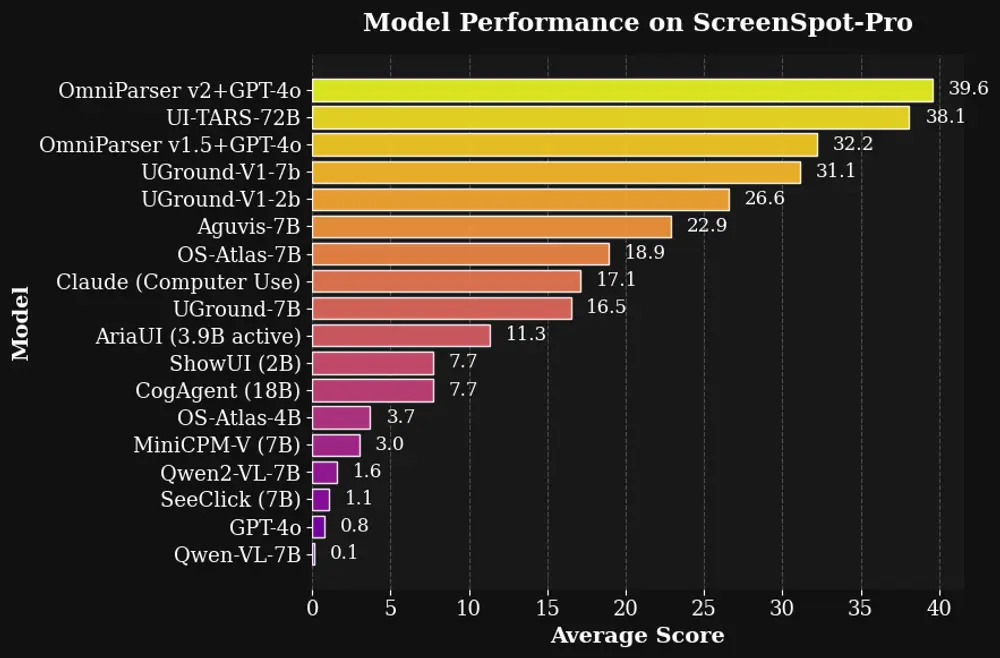
- 卓越的性能:在高分辨率屏幕和微小目标图标的新基准 ScreenSpot Pro 上,OmniParser V2 + GPT-4o 实现了 39.6 的平均准确率,相比 GPT-4o 原始分数 0.8 有了显著提升。
此外,OmniParser V2 还推出了 OmniTool,这是一个包含基本代理工具的 Docker 化 Windows 系统,支持与多种最先进的 LLM 集成,包括 OpenAI (4o/o1/o3-mini)、DeepSeek (R1)、Qwen (2.5VL) 和 Anthropic (Sonnet)。
V2 版本的关键特性:
- 更大的图标标题 + 标注数据集:更全面、更精准。
- 更低的延迟:平均延迟在 A100 上为 0.6 秒/帧,在单 4090 上为 0.8 秒。
- 强大的性能:在 ScreenSpot Pro 上达到 39.6 的平均准确率。
- 一站式工具:OmniTool 支持 OmniParser + 用户选择的视觉模型控制 Windows 11 虚拟机,开箱即用。
负责任的人工智能考虑
预期用途
OmniParser 的目标是将非结构化的屏幕截图图像转换为结构化的元素列表,包括可交互区域的位置和图标潜在功能的标题。它适用于已经接受过负责任分析方法培训且需要批判性推理的环境。OmniParser 能够提取屏幕截图中的信息,但需要人为判断其输出。
OmniParser 可用于各种屏幕截图,包括 PC 和手机,以及各种应用程序。
局限性
OmniParser 旨在忠实地将屏幕截图图像转换为可交互区域的结构化元素和屏幕的语义,但它不会检测输入中的有害内容。用户应确保输入内容无害。
虽然 OmniParser 仅将屏幕截图转换为文本,但它可用于构建基于 LLM 的可操作 GUI 代理。在使用 OmniParser 开发和操作代理时,开发人员需要遵循常见的安全标准。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











