“当所有人都在堆砌数据和参数时,腾讯选择了一条更本质的路:重新设计视觉编码器,让‘看’和‘想’在同一个空间里对话。”
在视觉语言模型(VLM)领域,主流范式长期依赖通过大规模对比学习(如 CLIP、SigLIP)预训练的视觉编码器。然而,腾讯最新开源的 Penguin-VL 系列模型对这一传统发起了挑战。
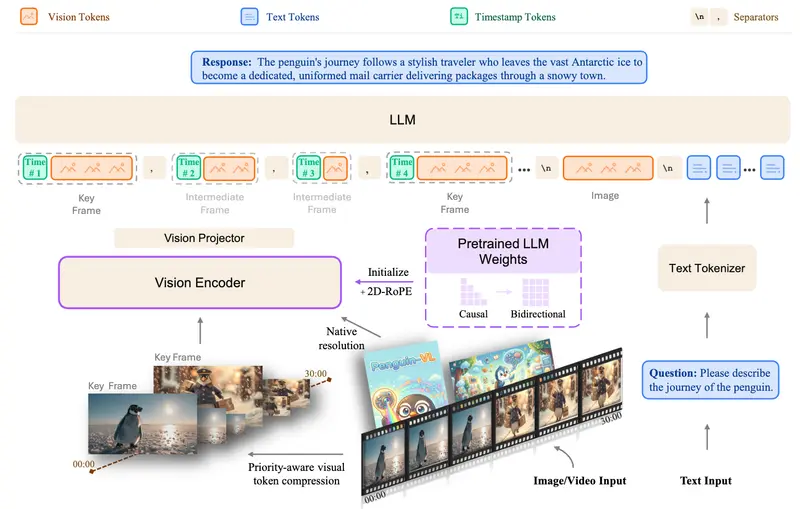
Penguin-VL 认为,对比学习倾向于学习粗粒度的类别不变性,难以满足 OCR(光学字符识别)、文档理解、密集字幕 及 复杂推理 所需的细粒度信号。为此,腾讯团队提出了一种颠覆性的架构:Penguin-Encoder——一个直接从纯文本大语言模型(LLM)初始化而来的视觉编码器。
- GitHub:https://github.com/tencent-ailab/Penguin-VL
- 模型:https://huggingface.co/collections/tencent/ai-lab
- Demo:https://huggingface.co/spaces/tencent/Penguin-VL
这一创新不仅打破了模态壁垒,更在紧凑的模型规模下(2B/8B),实现了精度与效率的完美平衡。
核心突破:四大技术创新
1. LLM 初始化的视觉编码器 (Penguin-Encoder)
这是 Penguin-VL 的灵魂所在。
- 传统做法:使用独立的 Vision Transformer (ViT),通过图像 - 文本对进行对比学习预训练。
- Penguin 做法:直接复用纯文本 LLM(如 Qwen3-0.6B)的权重初始化视觉主干。
- 注意力机制转换:将因果注意力(Causal Attention)转换为双向注意力(Bidirectional Attention),使其能全面捕捉图像上下文。
- 2D-RoPE 嵌入:引入二维旋转位置编码,完美处理可变分辨率的视觉词元。
- 优势:视觉主干在起始阶段就处于语言模型的表示空间内,大幅降低了模态对齐的难度,使学习更高效、更精细。
2. 混合监督编码器预训练
为了让 LLM 权重视觉化,团队设计了独特的“预热”策略:
- 重建与蒸馏:利用振幅、方向、关系损失等重建目标,稳定地将视觉知识注入编码器。
- 高分辨率对齐:预热完成后,切换至高分辨率对齐训练,确保模型能捕捉细微的视觉特征(如小字、复杂图表)。
3. 视频效率:时间冗余感知词元压缩
针对长视频理解中的计算瓶颈,Penguin-VL 引入了动态预算分配机制:
- 关键帧优先:在全局词元预算固定的情况下,智能识别并分配更多词元给信息量大的关键帧。
- 中间帧压缩:对变化较小的中间帧进行大幅压缩。
- 效果:在不牺牲理解精度的前提下,显著提升了长视频处理的效率和上下文长度支持。
4. 统一训练策略
采用 “低分辨率 → 高分辨率” 的课程学习(Curriculum Learning)结合指令微调:
- 先让模型学会“看大概”,再学会“看细节”。
- 在同一套框架下平衡图像理解与视频分析能力,避免多任务冲突。
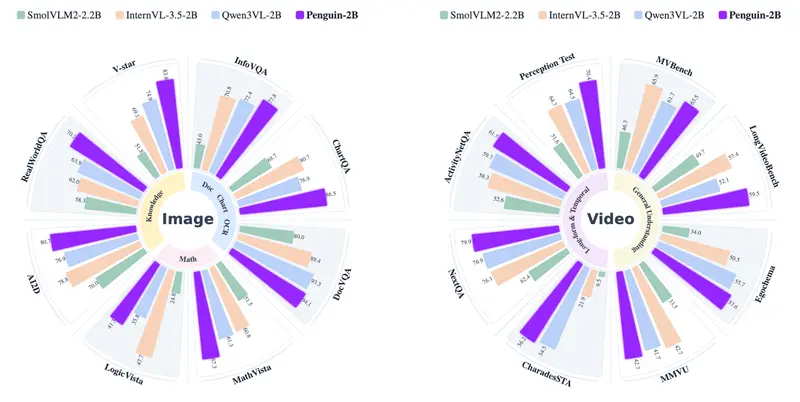
性能表现:小身材,大能量
Penguin-VL 系列发布了 2B 和 8B 两个版本。测试结果显示,它们在精度 - 效率权衡上表现卓越,尤其在以下领域显著优于同规模传统模型:
- OCR 密集型任务:凭借细粒度视觉表征,能精准识别文档中的小字、公式和复杂排版。
- 推理密集型任务:在需要多步逻辑推导的视觉问答中表现出色。
- 长视频理解:动态词元压缩使其在处理长时序视频时更具优势。
模型库与资源
腾讯已完全开源了相关模型权重,社区可立即下载使用:
| 模型名称 | 描述 | Hugging Face 链接 |
|---|---|---|
| Penguin-VL-2B | 超轻量级多模态模型,适合端侧部署 | tencent/Penguin-VL-2B |
| Penguin-VL-8B | 平衡性能与效率的主力模型 | tencent/Penguin-VL-8B |
| Penguin Vision Encoder | 独立的视觉编码器权重,可集成到其他架构 | tencent/Penguin-Encoder |
通过架构层面的创新——特别是打破视觉与语言模型的初始化壁垒,让两者在更底层的表示空间融合——我们完全可以在更小的参数量下,实现更精细、更高效的智能。这对于希望在本地设备、边缘计算场景中部署多模态能力的开发者和企业来说,无疑是一个巨大的利好。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...










