
“大模型的未来不在于无限堆砌参数,而在于如何让每一分算力都产生价值。”
浪潮旗下 YuanLab.ai 团队正式开源 源 3.0 Ultra (Yuan3.0 Ultra)。这是一款从零开始预训练的超大规模多模态模型,其初始参数量高达 1515B (1.5 万亿),但通过创新的架构设计,最终激活参数量仅为 68.8B。
- 官网:https://yuanlab.ai
- GitHub:https://github.com/Yuan-lab-LLM/Yuan3.0
- Hugging Face:https://huggingface.co/YuanLabAI/Yuan3.0-Ultra
- 魔搭:https://www.modelscope.cn/models/YuanLabAI/Yuan3.0-Ultra
这不仅是一次参数的胜利,更是一场效率的革命。源 3.0 Ultra 在多模态 RAG、复杂表格理解、Text-to-SQL等企业核心场景中,多项基准测试成绩超越 GPT-4o、Claude Opus 4.6 及 Gemini 3.1 Pro,成为驱动下一代企业智能体的强力引擎。
核心技术突破:大模型的“瘦身”与“深思”
源 3.0 Ultra 并未盲目追求推理时的庞大算力,而是通过两项颠覆性技术,实现了训练效率与推理质量的双重优化。
1. 逐层自适应专家剪枝 (LAEP):让训练效率提升 49%
传统的混合专家 (MoE) 模型在训练后期常面临“专家负载不均”的难题:少数专家累死,多数专家闲置。
- 创新方案:YuanLab 提出了 LAEP 算法。在训练进入稳定阶段后,系统会根据每一层的 Token 分布,动态剪枝低负载专家,并通过贪心策略重排剩余专家,实现完美的负载均衡。
- 惊人效果:
- 总参数量从 1515B 缩减至 1010B (减少 33%)。
- 预训练效率提升 49%。
- 最终推理时,激活参数量仅需 68.8B,使得如此庞大的模型也能在相对合理的算力成本下部署。
2. 反思抑制奖励机制 (RIRM):拒绝无效“过度思考”
在强化学习阶段,模型往往容易陷入“为了思考而思考”的陷阱,生成大量冗余步骤。
- 创新方案:基于 快速思考强化学习 (RAPO) 范式,引入 RIRM 机制。
- 答对了? 反思步骤越少,奖励越高(鼓励直觉与高效)。
- 答错了? 反思步骤越多,惩罚越重(避免无效试错)。
- 实测数据:
- 训练准确率提升 16.33%。
- 输出 Token 长度减少 14.38%。
- 真正实现了“该快则快,该慢则慢”的智能节奏。
🏆 企业级场景:全面领跑的硬实力
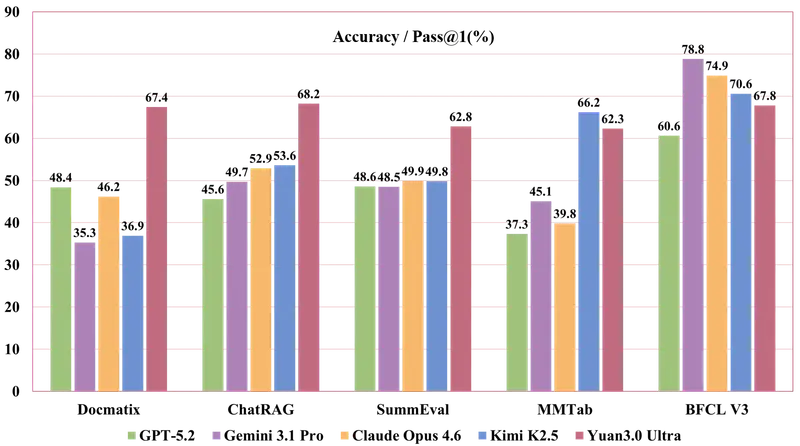
源 3.0 Ultra 专为解决企业复杂任务而生,在五大核心基准测试中展现了统治级表现。
1. 多模态 RAG:文档理解的绝对王者 (DocMatix 🏆)
面对包含文本、表格、图像的复杂多页文档,源 3.0 Ultra 展现了惊人的信息提取与关联能力。
- 得分:67.4%
- 对比:远超 GPT-4o (56.8%)、Claude Opus 4.6 (46.2%) 及 o3 (45.6%)。
- 意义:无论是财报分析还是技术手册检索,它都能精准定位关键信息,是企业知识库的完美大脑。
2. 文本 RAG:长短期记忆的全能选手 (ChatRAG 🏆)
在涵盖长上下文、短对话及结构化检索的 10 项任务中,源 3.0 Ultra 在 9 项排名第一。
- 平均准确率:68.2% (领先第二名 Kimi K2.5 近 15 个百分点)。
- 亮点:在 CoQA (94.6%) 和 SQA (91.0%) 等高难度对话与结构化检索任务中表现近乎完美。
3. 复杂表格理解:数据分析的行家 (MMTab)
处理财务报告、审批表单等结构化数据是许多模型的弱项,但源 3.0 Ultra 对此游刃有余。
- 平均准确率:62.3%
- 对比:超越 Claude Opus 4.6 (39.8%) 和 Gemini 3.1 Pro (45.1%),仅在个别单项上略逊于 Kimi K2.5,但综合均衡性更强。
- 能力:轻松应对跨行跨列计算、事实核查及长上下文表格推理。
4. 高质量摘要生成:信息压缩的艺术 (SummEval 🏆)
作为 Agent 的历史记忆压缩模块,摘要的忠实度与简洁性至关重要。
- 平均准确率:62.8%
- 优势:在 ROUGE-1 (59.1) 和 BERTScore (91.1) 上大幅领先,确保信息不丢失、语义不扭曲。
5. 工具调用与 Text-to-SQL:智能体的手脚
- 工具调用 (BFCL V3):平均分 67.8%,尤其在无关调用拒绝能力上高达 86.0%,有效防止 Agent 乱调 API。
- Text-to-SQL:在 Spider 1.0 基准上取得 83.9% 的高分,超越 Qwen3.5 和 DeepSeek-V3.2,让自然语言查库更加精准可靠。
📊 性能对比一览
| 基准测试 | 任务类型 | Yuan3.0 Ultra | GPT-4o | Claude Opus 4.6 | Gemini 3.1 Pro | Kimi K2.5 |
|---|---|---|---|---|---|---|
| DocMatix | 多模态 RAG | 67.4 🥇 | 56.8 | 46.2 | 35.3 | 36.9 |
| ChatRAG | 文本 RAG | 68.2 🥇 | 50.5 | 52.9 | 49.7 | 53.6 |
| MMTab | 表格理解 | 62.3 🥈 | - | 39.8 | 45.1 | 66.2 🥇 |
| SummEval | 摘要生成 | 62.8 🥇 | 46.5 | 49.9 | 48.5 | 49.8 |
| Spider 1.0 | Text-to-SQL | 83.9 🥇 | - | - | - | 82.7 |
(注:部分模型未公开所有基准数据,“-”表示暂无公开数据)
💾 模型下载与部署
源 3.0 Ultra 现已完全开源,支持多种精度格式,方便不同算力需求的用户部署。
| 模型版本 | 总参数量 | 精度 | 上下文长度 | 下载平台 |
|---|---|---|---|---|
| Yuan3.0 Ultra | 1.01T | 16bit | 64K | ModelScope / HuggingFace / WiseModel |
| Yuan3.0 Ultra Int4 | 1.01T | 4bit | 64K | ModelScope / HuggingFace / WiseModel |
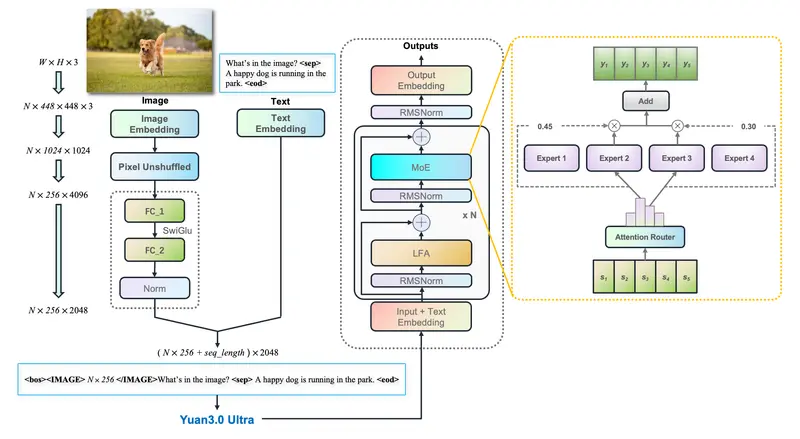
- 架构特点:103 层 Transformer,集成 SigLIP 类视觉编码器,支持原生多模态输入。
- 适用场景:企业私有知识库、复杂数据分析 Agent、自动化办公流、科研文献解读。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











