
上海AI实验室InternVL项目组推出 InternVL3.5,这是一个开源的多模态大语言模型(MLLM)系列,旨在提升模型在多功能性、推理能力和效率方面的表现。
- GitHub:https://github.com/OpenGVLab/InternVL/blob/main/README_zh.md
- 模型:https://huggingface.co/collections/OpenGVLab/internvl35-68ac87bd52ebe953485927fb
InternVL3.5 通过一系列创新技术,如级联强化学习(Cascade RL)、视觉分辨率路由器(ViR)和解耦视觉语言部署(DvD),显著提高了模型的推理性能和效率。
- 多功能性:InternVL3.5 不仅能够处理传统的文本和图像理解任务,还能进行复杂的数学推理(如解决数学问题)、多图像理解(如跨图像推理)以及图形用户界面(GUI)交互等任务。
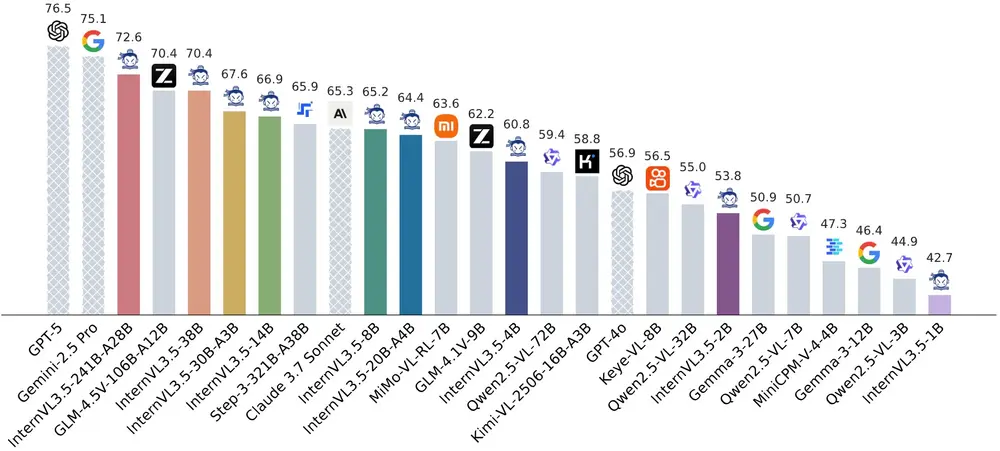
- 推理能力:在数学推理任务 MathVista 上,InternVL3.5-241B-A28B 的得分达到了 82.7,接近顶级商业模型 GPT-5 的表现(84.2),显示出强大的推理能力。
- 效率提升:与 InternVL3 相比,InternVL3.5 在推理速度上实现了 4.05 倍 的提升,同时在整体推理性能上提高了 16.0%。
主要功能
- 多功能性:支持多种任务,包括文本理解、图像理解、数学推理、多图像理解、视频理解、GUI 交互、图形生成等。
- 推理能力:在复杂的多模态推理任务中表现出色,如 MMMU(多学科推理)和 MathVista(数学推理)。
- 效率提升:通过 ViR 和 DvD 技术,显著提高了模型的推理速度,降低了计算成本。
- 开源性:所有模型和代码均公开发布,便于社区使用和进一步研究。
主要特点
- 级联强化学习(Cascade RL):结合了离线强化学习(MPO)和在线强化学习(GSPO),通过两阶段训练提升模型的推理能力。
- 视觉分辨率路由器(ViR):动态调整视觉令牌的分辨率,减少推理成本,同时保持性能。
- 解耦视觉语言部署(DvD):将视觉编码器和语言模型部署在不同的 GPU 上,优化计算负载,提高推理速度。
- 测试时扩展(Test-Time Scaling):通过深度思考和并行思考策略,进一步提升模型的推理能力。
工作原理
- 级联强化学习(Cascade RL):
- 离线阶段:使用混合偏好优化(MPO)进行高效训练,快速收敛到稳定结果。
- 在线阶段:使用组序列策略优化(GSPO)进一步优化模型输出分布,提升推理性能。
- 视觉分辨率路由器(ViR):
- 通过评估图像块的语义丰富度,动态选择合适的压缩率,减少视觉令牌数量,降低推理成本。
- 解耦视觉语言部署(DvD):
- 将视觉编码器和语言模型分别部署在不同的 GPU 上,减少计算阻塞,提高推理效率。
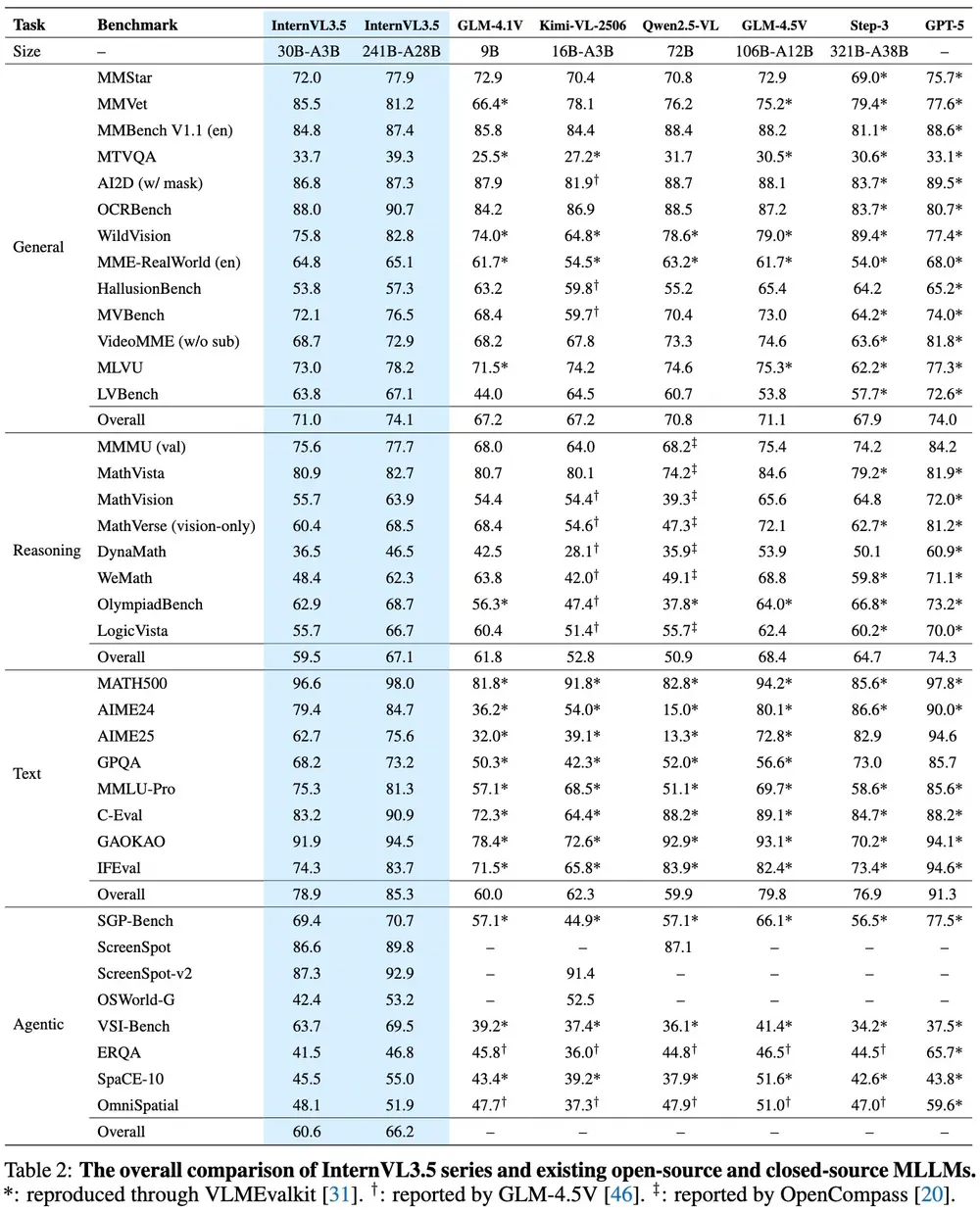
测试结果
- 多功能性:
- 在 MMStar 上,InternVL3.5-241B-A28B 的得分达到了 77.9,与 GPT-5(75.7)相当。
- 在 MMBench v1.1 (en) 上,InternVL3.5-241B-A28B 的得分达到了 87.4,接近 GPT-5(88.6)。
- 推理能力:
- 在 MMMU 上,InternVL3.5-241B-A28B 的得分达到了 77.7,接近 GPT-5(84.2)。
- 在 MathVista 上,InternVL3.5-241B-A28B 的得分达到了 82.7,接近 GPT-5(81.9)。
- 效率提升:
- 与 InternVL3 相比,InternVL3.5 在推理速度上实现了 4.05 倍 的提升,同时在整体推理性能上提高了 16.0%。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











